7
 Shared Knowledge Bases
Shared Knowledge Bases
I can best illustrate the power of knowledge sharing with the metaphor of lighting a candle. Pretend we are in a dark room, with all the lights out except one. I hold the lighted candle; the other 100 people in the room all have candles, but their candles are out. If I use my candle to light everyone else's candle, does my candle burn less brightly? Of course not. You see, I can share my knowledge, and I don't lose it. But what happens to the room after everyone else's candle is lit? The room is brighter for us all.
Daniel Burrus, Technology Futurist1
As the first major commercialization of artificial intelligence research, knowledge-based systems (KBS) embody a novel paradigm of computing that has a wide array of useful applications. Relying on the interaction between logical procedures and known facts to conduct searches for solutions, KBS technology offers the capacity to:
• Capture and retain scarce human expertise.
• Aid and inform expert decision-making.
• Improve non-expert decision-making.
• Solve specific kinds of complex or time-consuming problems more efficiently.2
The interest in knowledge as a strategic lever in business is not new. In the 1970s and 1980s, there were great expectations that knowledge-based computer systems (also called expert systems) could harness knowledge to solve many business problems. That promise was only partially fulfilled and certainly not to the extent that workers in the field had hoped. In retrospect, the problem was that developers focused too much on what has been described as "falling into the trap of trying to develop `thinking machines' rather than using machines to augment human thinking."3
The technology has already undergone a boom-and-bust cycle, initially fueled by unrealistic expectations and hype. A number of early adopting companies presided over large-scale KBS debacles, most of which occurred precisely because of the companies' overly ambitious faith in the concept of artificial intelligence rather than in the reality of KBS technology. However, another class of users--the companies that implemented the technology on a smaller scale and treated it as just another tool with its own unique assets and limitations--has seen significant benefits. These success stories are still largely in the shadow of early disappointments, but the list of systems with impressive return-on-investment numbers is growing at an accelerating pace. Consequently, even those companies burned by initial forays into KBS are finding that, within the right set of parameters, the technology--which the companies can either deploy internally or embed in another product--yields competitive advantage.4
What Are Shared Knowledge Bases?
Knowledge is relevant, useful information about things that are important to the organization, such as its customers, competitors, product development processes, and so on. Shared knowledge bases are the collective memory of the company that have been organized and made accessible by anyone within the company. It is the shared reference frame of any field of expertise or know-how. This application makes it possible to collect, share, and diffuse knowledge. The user finds information thanks to an organized representation of the knowledge. It makes it possible to increase the productivity by increasing the level of expertise of each one. It diffuses the knowledge while making it available (Intranet, Internet, extranet, and groupware), and it collects what is perceived as knowledge or potentially or currently useful knowledge, even when it appears during current processes of work.
The expertise, know-how, the featured data of a practice field, best practices, and the experiments are indexed, classified, and finalized. Collaborative processes such as joint problem-solving, re-registering problems, data interpretation, and sifting information are part of the larger enterprise that turns stored information into knowledge. It enhances communication and collaboration, whether it is between the generations, the technologies, or the offices.5 It reduces the dependency of employees on fellow department members. Knowledge is stored and accessible throughout the organization, regardless of geography or operating unit. Hence, someone in one area of the company can access information from other areas and past projects to help them make sense of and respond to current projects for different clients. Employees can refine rather than reinvent knowledge, thereby responding more quickly to the current demands of customers.
 Technology Background
Technology Background
In the pre-knowledge management era, most situation and job-specific information resided in the heads of people. Different people may have been carrying out the same sorts of tasks in other parts of the same organization. Yet, those two people may not have talked to one another, let alone shared knowledge about how best to get their similar jobs done. It is also quite clear that, in the past, knowledge has been difficult to access because it resided either in brain cells in heads or on paper in locked-up filing cabinets. Moreover, some senior managers deliberately protected their knowledge, whereas the new imperative for leaders is to diffuse useful information throughout the organization.
Recognizing that the people in an enterprise are one of its most important assets, companies have been continuously providing them with more and more computer support. Until recently, this meant providing them with more accurate, more timely, and more readily available information. This has not been enough. Companies are beginning to realize that the major distinguishing characteristic between them and their competitors is the expertise of their staff--the skill and judgment being applied to the information.
So, to make even better use of its assets, a company needs to automate key parts of the tasks that require expertise. Early attempts to do this failed because these tasks were too complex, too unstructured, and not readily analyzable using conventional techniques. The reason for the difficulty was because the programming paradigm that was being used did not allow for knowledge to be represented explicitly, and these tasks rely on the application of knowledge to a much greater extent than previous automated tasks.
A New Programming Paradigm
The conventional view of a program is: Program = Algorithm + Data. This view does not recognize that the algorithm has two components: knowledge and control. As an example, consider a payroll program.
• Knowledge is the rules and regulations set out by the government's tax and other legislation and the company's remuneration, overtime, and other policies.
• Control is that which determines the order in which the processing operations are to be performed. (The data is the information about a particular employeehis or her rate of pay, hours worked, tax code, and so on.)
With this new insight, we have: Program = Knowledge + Control + Data.
This is where the new programming paradigm of knowledge-based systems comes in. In a KBS, the knowledge is made explicit, rather than being implicitly mixed in with the algorithm. When this is done, the algorithm also has to include a reasoning or inference mechanism so that deductions and conclusions can be drawn from the knowledge. With this approach, the success rate of automating the knowledge-intensive tasks in an organization increased dramatically.
The end result is: Program (Knowledge-Based System) = Explicit Knowledge + Reasoning Mechanism + Control + Data.
The most common and simplest way of representing knowledge is in the form of rules, which is sometimes referred to as rule-based programming. Thus, we could have:
if it is evening and the sky is red, then expect good weather tomorrow.
if furnace_temp > 800 and operate_time < 15, then close Feed1 and display Warning3.
Another way to represent knowledge is using frames. A frame is very similar to the concept of an object in object-oriented programming, but is rather more powerful and predates it by about 10 years.
Knowledge-based systems and knowledge technology can be used for an extremely wide variety of tasks since, as has been shown above, it is, in essence, a more advanced programming paradigm. The use of the technology should not be restricted to cases where human expertise is being automated. Rather, it should be considered wherever an application embodies a high degree of complexity. In cases where the knowledge has never before been written down but is in the head of an expert, special analysis techniques and skills are required. These are commonly referred to as knowledge elicitation techniques.
The benefits of knowledge-based systems in general include:
• Delivering consistent decisions throughout an organization.
• Preserving the know-how of the most talented specialists by capturing their experience.
• Transferring experience from the skilled specialist to the novice.
• Building a corporate memory by sharing individual experience.
The term "knowledge-based systems" covers a broad area and encompasses particular specialties such as:
These usually employ alternative methods to represent knowledge and are combined with different reasoning mechanisms.6
Case-Based Reasoning7
Case-based reasoning (CBR) is one of those rare technologies whose principles can be explained in a single sentence:
To solve a problem, remember a similar problem you have solved in the past and adapt the old solution to solve the new problem.
Of course, the technology is considerably more sophisticated than this description suggests. A case is a formal description of a problem, together with a formal description of its solution. Often, a case boils down to a set of values for a set of parameters and is equivalent to historical examples. The starting point is a "case-base," which is a repository of representations of past cases. Some of the values in the case represent the problem description, and the rest represent the solution.
In a little more detail, the mechanism behind CBR is as follows:
The characteristics of a new problem (case) are matched against an indexed case-base of problems in the same domain, and the best-matching case is selected. The solution to this best-matching case is then adapted to fit the new case and is proposed as the solution to the new problem. This new case and adapted solution may then be considered for retaining and adding to the case-base.
CBR is related to knowledge-based systems in that the form of knowledge representation is the case-base, and the reasoning mechanism is the case matching and case adaptation processes. More specifically, CBR is closely linked to induction in that both techniques are a form of machine learning, and both rely on an historical set of examples (cases) as their raw material.
Induction is often used within CBR: the decision tree that induction can derive from a set of examples is used as a means of indexing the case-base for fast case selection. The technique of CBR is unique among the learning technologies because of being the only one that retains the examples from which it learned. It is therefore able to keep all the "raw" knowledge. Compare this to induction, for example, where some knowledge is inevitably lost as a result of the generalization mechanism. Furthermore, CBR can continue to learn incrementally by having new cases added during its operation.
A CBR approach is not suited to all problems. Some of the characteristics of a domain that indicate whether a CBR approach would be suitable are:
• There exist records of previously solved problems.
• Historical cases are viewed as assets that ought to be preserved.
• If there is no case history, it is intuitively clear that remembering previous experiences would be useful.
• Specialists talk about their domain by giving examples.
• Experience is at least as valuable as textbook knowledge.
Figure 7.1. Case-Based Reasoning Process
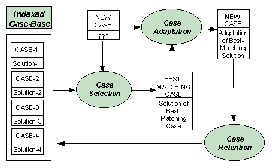
CBR is a relatively new technology, having first appeared in commercial tools in the early 1990s. Since then, it has been used to create numerous applications in a wide range of domains. The technology has been extremely effective in creating help-desk systems, but its application domain is much wider than this. It covers diagnostic systems, classification systems, and, perhaps surprisingly at first sight, control, configuration, and planning applications.
Constraint-Based Reasoning8
Constraint solving (also called constraint reasoning or constraint-based reasoning) is a relatively new technology that has evolved out of joint research between the major European computer manufacturers. It very quickly made the transition from research idea to practical technique, and there are now several suppliers of tools that are being used for many highly complex applications.
Constraint solving (CS) can be viewed as part of knowledge-based systems in that it provides a means to represent knowledge about the world, and a mechanism for reasoning on and drawing conclusions from that knowledge. It is also possible to compare CS with genetic algorithms since it addresses very similar types of problems: those that can be expressed in terms of assigning a set of values to a collection of variables.
The knowledge that a CS system represents is, primarily (and unsurprisingly), the constraints on the variables involved. This includes relationships between variables. An example will show the type of problem to which CS is very well suited:
We have a number of drying machines, each with different maximum power consumption. We also have a number of substances that needed to be dried. Each has potentially different amounts of moisture and drying characteristics. In general, the higher the drying temperature, the greater the total energy required to dry a substance, but the shorter the time needed. Furthermore, each substance is part of a different order, and each order has to be ready by a certain time. In addition, operators for the drying machines have to be scheduled according to shifts, holidays, overtime availability, skills, and so on.
The problem is to assign substances and operators to dryers in the optimum sequence so as to minimize the total energy used. At the same time, constraints of meeting delivery dates, not exceeding a maximum power load at any given time, and satisfying operator availability have to be met. A very wide range of constraints can be expressed in CS systems. Some examples might be:
• All variables in the list [A, B, C, D, E] must have different values.
• X must have a value in the list [1,3,5...10,15,20...29].
• if X > 30 and (Y < 30 OR Z < 31), then A > B.
The reasoning mechanism in a CS tool keeps track of all possible values of all variables. As it cycles around applying the constraints, it reduces these possible values. At the end of the process, if one or more variables do not have a unique value, the overall problem has more than one solution.
The developer has control over exactly how the solver goes about this process and can also determine what to do about multiple solutions. For example, it may be necessary to find all solutions and select the optimum one, or it may be that any solution is acceptable provided all constraints are satisfied. Another possibility is that no solutions are found, in which case the system can be set up to start relaxing constraints in a defined way until a solution is obtained. If genetic algorithms are being used to solve a problem, there has to be a way of determining the "fitness" of a solution. In principle, this "fitness function" could include all the constraints of the problem. It could be set up so that the more closely the constraints are satisfied, the better the "fitness" of the solution. However, as the constraints become more and more complex, the genetic algorithm approach becomes unwieldy and inefficient, and a CS approach becomes preferable.
As well as being compared to genetic algorithms, CS is often compared to mathematical techniques from operations research. The major benefits it has over these approaches are:
• Flexibility. Constraint solving can much more easily take into account ad hoc constraints, which always occur in real life. Mathematical techniques generally have to assume a degree of uniformity that exists only in the abstract.
• Incrementally. CS allows a problem to be built up step-by-step, adding new constraints without affecting the overall structure of the solution.
• Cooperative mechanisms. The constraint-solving approach makes it possible to incorporate different types of "solvers," including linear programming tools, for example, into an overall environment, thus getting the best of all worlds. CS technology is particularly suited to scheduling, resource allocation, and planning problems. It is also suited to layout problems for cutting shapes from sheet material where the amount of waste material needs to be minimized.
Fuzzy Systems9
Fuzzy logic recognizes that real-world propositions are often not strictly true or false. A liquid does not suddenly change from being "warm" at 39ºC to being "hot" at 40ºC. Instead, the concepts of cold, warm, and hot have degrees of truth that depend on the temperature.
Fuzzy logic provides a precise way of defining such imprecise concepts. For example, we could decide that anything above 38ºC was definitely hot (truth value = 1), and anything below 25ºC was definitely not hot (truth value = 0). A temperature in between would be hot to a degree(!) somewhere between 0 and 1. Similarly, warm and cold could have spreads of truth values, depending on the temperature. We can show this idea graphically as follows:
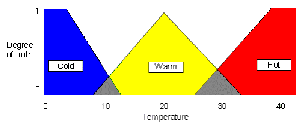
Of course, these relationships between temperature and truth value need not be straight lines. It is also possible to provide precise meanings to terms such as "very," "nearly," "almost," and so on. Having done so, we can write rules of the form:
if vapor-temperature is very hot and level-of-vessel-A is almost empty, then decrease pressure by 15%
This rule represents a sophisticated function relating the temperature of the vapor, the level of vessel A, and the pressure. The complexity is hidden in a number of places:
• Within the definitions of hot, empty, very, and almost.
• Within the reasoning mechanism that combines fuzzy truth values (i.e., how and and or operate on fuzzy truth values).
• How the reasoning mechanism deals with the action part of the rule (e.g., working out to what degree the pressure is decreased by 15%).
The beauty of fuzzy logic is that a very complex relationship can be represented by a rule that is simple to express and very easy to understand. Just a few rules of this nature can be used to cover all ranges of temperature and level. Together, they would constitute a complete control system for pressure adjustment that is intuitive, comprehensible, and could be developed without needing advanced mathematical skills.
Fuzzy logic is clearly related to knowledge-based systems. The fuzzy rules are the way to represent knowledge, while the principles of fuzzy logic constitute the reasoning mechanism. Fuzzy systems have proved to be very effective in many control applications, and an increasing number of controller chips are based on the technology. These are finding their way into washing machines, cameras, electric drills, and other equipment. The technology has also been used very successfully in certain areas of the process industries, particularly the cement industry.
The benefits of fuzzy systems for control applications are:
• They can deal with noisy and uncertain data.
• Application knowledge can be directly encoded into the rules.
• Their operation can be intuitively understood--as opposed to being a "black box."
• Development times can be very short.
• They can be implemented in hardware for even greater speed of operation.
As well as control applications, fuzzy rules can be used for decision support applications. In this case, the technology is very similar to rule-based expert systems but with the added feature of being able to represent and reason with fuzzy concepts.
Neuro-Fuzzy Systems
Fuzzy systems, as described above, are ideal in situations where the data is noisy and/or uncertain, and where the knowledge is already known. Where the knowledge is not already known but where there are historical examples available, it is necessary to use a learning technology. The most obvious choice might be neural nets, which can be used to cope with the noisy and uncertain data. However, neuro-fuzzy systems can also be used.
The term neuro-fuzzy is itself fuzzy and means different things to different people. However, what is common to all the meanings is that there is an element of learning involved. One approach to this is to assign a weight to each rule in the fuzzy rule-base. The weight determines the degree of relevance of the rule. A "learning algorithm" is used to examine the historical data and adjust the weights so as to obtain the required results. This is similar to the way in which neural networks are trained. In fact, by linking a neural net to a set of fuzzy rules with weights, the powerful neural net learning algorithms can be used to set the weights for the rules. Neuro-fuzzy systems thus combine the advantages of fuzzy rules and of neural nets:
• The ability to deal with noise and uncertainty.
Rule Induction10
Rule induction is a particular aspect of inductive learning. It is related to knowledge-based systems in that it provides a means of creating the rules that form the knowledge base of a KBS.
Inductive learning is the process of acquiring general concepts from specific examples. Very often the "specific examples" will be historical data of some form, such as production data for some product (e.g., mass of item, density of item, length of time in firing oven, temperature of oven, ambient temperature, ratio of constituent materials, and the final quality measure).
By analyzing many past examples, it should be possible to derive (induce) a "general concept" which defines the production conditions that lead to good quality products, as opposed to poor quality products. Taking this example further, suppose we have 900 examples of historical data that we can represent in tabular form (Table 7.1).
Source: AI Intelligence
The normal way induction works is to start with a subset of the examples. This subset can be randomly selected, or, by the application of some clever algorithms, can be chosen to be as representative of the whole set as possible. The induction algorithm then works on this set of examples and produces a decision tree. The decision tree can (if required) be transformed into a set of rules, which might look like:
if mass > 215 and density = normal and oven_temp < 182
then quality = good
if mass > 215 and density = high and oven_temp < 190 and ambient_temp >= 14, then quality = good
if mass < 215 AND density = normal, then quality = poor
These rules can then be tested on the remainder of the examples to determine how well they represent the data. If acceptable, they can then be used on new examples in an operational environment.
The main difference between inductive learning and neural network learning (or the similar learning associated with fuzzy logic rules) is that the results of the former can (normally) be read and understood by humans, whereas the results of the latter are generally meaningless to humans. This is one of the major advantages that inductive learning has over neural and other learning systems where the results are "opaque."
For this reason, it is legitimate with regard to the inductive process as one that creates knowledge. Very often, such knowledge has never before been explicitly (or even implicitly) recorded. Rule induction can be used for a very wide range of problems. All that is necessary is that there is a suitable historical set of examples.
Knowledge System Components
A knowledge system has two components: a knowledge base and an inference engine.
Knowledge Base
It is the knowledge base component that contains the system's knowledge. It contains both procedural (information about courses of action) and declarative knowledge (facts about objects, relationships, events, and situations). Although many knowledge representation techniques have been developed, the most prevalent form is the "rule-based production system" approach. Production rules have the general form of if (antecedent), then (conclusion 1), else (conclusion 2). Rules can be chained together such that the conclusion of one rule is the antecedent of another rule. Rules can have confidence factors associated with the conclusions so that strong and weak conclusions can be established. In this way, multiple rules coming to the same conclusion can reinforce the confidence of that conclusion. Conversely, very weak conclusions (i.e., those conclusions that are relatively unlikely) can be dropped from consideration. Typically, a Bayesian method is used to combine confidence factors as they are propagated through the rules. Not all rules pertain to the system's domain; some rules, called meta-rules, pertain to other rules. A meta-rule (a "rule about a rule") helps guide the execution of an expert system by determining under what conditions certain rules should be considered instead of other rules.
Inference Engine
There is a second component--the inference engine--that directs the implementation of the knowledge. The inference engine "decides" which search techniques are to be used to determine how the rules in the knowledge base are to be applied to the problem. In effect, an inference engine "runs" an expert system, determining which rules are to be invoked, accessing the appropriate rules in the knowledge base, executing the rules, and determining when an acceptable solution has been found. There are many variations of search techniques employed, but two of the most common are the backward and forward chaining strategies.
• Backward chaining is an inferencing strategy that starts with a desired goal or objective and proceeds backwards along a chain of reasoning in an attempt to gather the information needed to verify the goal. A chain of reasoning consists of a series of if-then statements called rules, and procedures called when needed methods. when needed methods are executed when the value of a parameter needs to be determined while backward chaining through a set of rules.
• Forward chaining is an inferencing strategy that starts with known facts or data and infers new facts about the situation based on the information contained in the knowledge base. The process is referred to as forward chaining because it starts with known facts and proceeds forward to the conclusions of the session. The process continues until no further conclusions can be deduced from the initial data. A demon is a forward chaining if-then rule. demons are evaluated by the inference engine when the value of an attribute in the demon if statement antecedent(s) changes value in the session context. demons can implement procedures called when changed methods. As the name implies, a when changed method associated with an attribute will be executed when the value of that parameter changes, such as the result of a then conclusion being asserted.11
Privacy, Protection, and Privileges
The Internet revolutionized the way business does business. Before the Internet, security inside the enterprise was as simple as passwords or administered rights to directories on a local area network (LAN). Larger networks with remote access employed simple Internet protocol (IP) filtering firewalls to keep out "hackers" and other unwanted intruders. Internet growth challenges this strategy as a safe way of doing business. Lower cost and higher availability of the Internet have also allowed smaller businesses to take a more aggressive role in information sharing.
The growth of Web technology represents the latest key ingredient to the new wave of enterprise partnering. Web technology solves two difficult problems at once--standardized document formatting and standardized development environment. Legacy desktop applications provide information in a bewildering array of incompatible formats. HTML-language produces universal "document-based" information viewed through standard Web browsers. And, Java-based programming languages promise to create a universal development model to deliver rich applications through the browser. This combination creates enormous new opportunity for enterprises to benefit from information sharing. However, because corporate information now passes through the public network, it creates security problems. Simple passwords and directory access no longer guarantee protection.
Applications for information intimacy depend upon two critical conditions. First, security must be tight and reliable. Second, decisions about information relationships must be controlled by those who understand the meanings and purposes of the relationships. Securing a network is comprised of several elements, but the heart of the security is access control.12
An access control list is an object that is associated with a file and contains entries specifying the access that individual users or groups of users have to the file. They provide a straightforward way of granting or denying access for a specified user or groups of users. Without the use of access control lists (using the permission bit mechanism only), granting access to a single user who is not the owner of the file can be cumbersome.
Access control lists (ACLs) also allow you to control which clients can access your server. Directives in an ACL file can:
• Screen out certain hosts to either allow or deny access to part of your server.
• Set up password authentication so that only users who supply a valid login and password may access part of the server.
• Delegate access control authority for a part of the server (such as a virtual host's URL space or an individual user's directory) to another ACL file.
The Access Control List System13
Access Controllers
The usual strategy for providing reversibility of bindings (authorization) is to control when they occur--typically by delaying them until the last possible moment. The access control list system provides exactly such a delay by inserting an extra authorization check at the latest possible point. The ACL system is a list-oriented strategy with many possible mechanizations. For ease of discussion, we will describe a mechanism implemented completely in hardware (perhaps by microprogramming), although, historically, access control list systems have been implemented partly with interpretive software. Our initial model will impose the extra authorization check on every memory reference, an approach that is unlikely in practice but simpler to describe. Later, we will show how to couple an access control list system to a capability system, a more typical implementation that reduces the number of extra checks.
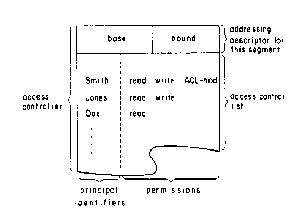
Whenever a user requests that a segment be created, the memory system (or addressing descriptors) will actually allocate two linked storage areas. One of the storage areas will be used to store the data of the segment as usual, and the second will be treated as a special kind of object, which we will call an access controller. An access controller contains two pieces of information: an addressing descriptor for the associated segment and an access control list (Figure 7.3).
Figure 7.3. Conceptual Model of an Access Controller
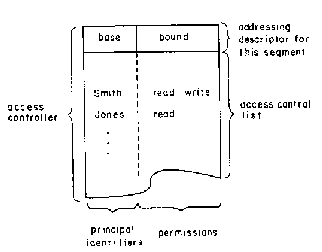
Source: Saltzer & Schroeder
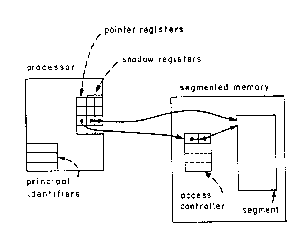
An addressing descriptor for the access controller itself is assigned a unique identifier and placed in the map used by the memory system to locate objects. The access controller is to be used as a kind of indirect address, as shown in Figure 7.4. In order to access a segment, the processor must supply the unique identifier of that segment's access controller. Since the access controller is protected, there is no need for these unique identifiers to be protected. Protection descriptor registers are replaced with unprotected pointer registers, which can be loaded from any addressable location with arbitrary bit patterns. Of course, only bit patterns corresponding to the unique identifier of some segment's access controller will work.
A data reference by the processor proceeds in the following steps, keyed to Figure 7.4.
(1) The program encounters an instruction that would write-in the segment described by pointer register 3 at offset k.
(2) The processor uses the unique identifier found in pointer register 3 to address access controller AC1. The processor at the same time presents to the memory system the user's principal identifier, a request to write, and the offset k.
(3) The memory system searches the access control list in AC1 to see if this user's principal identifier is recorded there.
(4) If the principal identifier is found, the memory system examines the permission bits associated with that entry of the access control list to see if writing is permitted.
(5) If writing is permitted, the addressing descriptor of segment X, stored in AC1, and the original offset k are used to generate a write request inside the memory system.
Figure 7.4. Access Controller as an Indirect Address
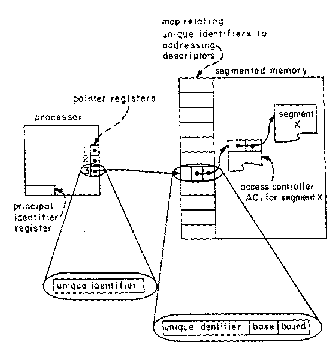
Source: Saltzer & Schroeder
One more mechanism is needed to make this system work. The set of processor registers must be augmented with a new protected register that contains the identifier of the principal currently accountable for the activity of the virtual processor, as shown in Figure 7.4. (Without that change, one could not implement the second and third steps.)
For example, we may have an organization like that of Figure 7.5, which implements essentially the same pattern of sharing as the simple capability system of Figure 7.6. The crucial difference between these two figures is that, in Figure 7.5, all references to data are made indirectly via access controllers. Overall, the organization differs in several ways from the pure capability system:
(1) The decision to allow access to segment X has known auditable consequences. An individual cannot make a copy of the addressing descriptor of segment X since he does not have direct access to it, thus eliminating propagation of direct access. The pointer to X's access controller itself may be freely copied and passed to anyone, but every use of the pointer must be via the access controller, which prevents access by unauthorized principals.14
(2) The access control list directly implements the sender's third step of the dynamic sharing protocol--verifying that the requester is authorized to use the object. In the capability system, verification was done once to decide if the first capability copy should be made; after that, further copying was unrestricted. The access control list, on the other hand, is consulted on every access.
(3) Revocation of access has become manageable. A change to an access control list removing a name immediately precludes all future attempts by that user to use that segment.
(4) The question of "who may access this segment?" apparently is answered directly by examining the access control list in the access controller for the segment. The qualifier "apparently" applies because we have not yet postulated any mechanism for controlling who may modify access control lists.
(5) All unnecessary association between data organization and authorization has been broken. For example, although a catalog may be considered to "belong" to a particular user, the segments appearing in that catalog can have different access control lists. It follows that the grouping of segments for naming, searching, and archiving purposes can be independent of any desired grouping for protection purposes. Thus, in Figure 7.5, a library catalog has been introduced.
It is also apparent that implementation, especially direct hardware implementation, of the access control list system could be quite an undertaking. We will later consider some strategies to simplify implementation with minimum compromise of functions, but first it will be helpful to introduce one more functional property--protection groups.
Figure 7.5. A Protection System
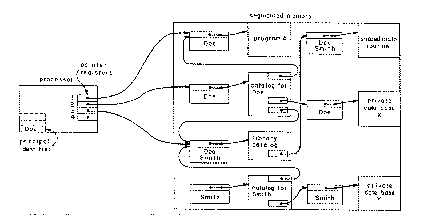
This system uses access controllers containing access control lists. In this system, every segment has a single corresponding access controller with its own unique identifier for addressing purposes; pointer registers always contain the unique identifiers of access controllers. Program A is in control of the processor, and it has already acquired a pointer to the library catalog. Since the access control list in the access controller for the library catalog contains Doe's name, the processor can use the catalog to find the pointer for the shared math routine. Since his name also appears in the access control list of the math routine, the processor will then be able to use the shared math routine.
Figure 7.6. A Simple Capability System

Protection Groups
Cases often arise where it would be inconvenient to list by name every individual who is to have access to a particular segment, either because the list would be awkwardly long or because the list would change frequently. To handle this situation, most access control list systems implement factoring into protection groups, which are principals that may be used by more than one user. If the name of a protection group appears in an access control list, all users who are members of that protection group are to be permitted access to that segment.
Methods of implementation of protection groups vary widely. A simple way to add them to the model of Figures 7.3 and 7.4 is to extend the "principal holding" register of the processor so that it can hold two (or more) principal identifiers at once--one for a personal principal identifier and one for each protection group of which the user is a member. Figure 7.4 shows this extension in dashed lines. In addition, we upgrade the access control list checker so that it searches for a match between any of the principal identifiers and any entries of the access control list.15 Finally, who is allowed to use those principals that represent protection group identifiers must also be controlled systematically.
We might imagine that for each protection group there is a protection group list; that is, a list of the personal principal identifiers of all users authorized to use the protection group's principal identifier. (This list is an example of an access control list that is protecting an object--a principal identifier other than a segment.) When a user logs-in, he can specify the set of principal identifiers he proposes to use. His right to use his personal principal identifier is authenticated, for example, by a password. His right to use the remaining principal identifiers can then be authenticated by looking up the now-authenticated personal identifier on each named protection group list. If everything checks, a virtual processor can safely be created and started with the specified list of principal identifiers.16
Implementation Considerations
The model of a complete protection system as developed in Figure 7.4 is one of many possible architectures, most of which have essentially identical functional properties. Our choices among alternatives have been guided more by pedagogical considerations than by practical implementation issues. There are at least three key areas in which a direct implementation of Figure 7.4 might encounter practical problems.
(1) As proposed, every reference to an object in memory requires several steps: reference to a pointer register; indirect reference through an access controller including search of an access control list; and finally, access to the object itself via addressing descriptors. Not only are these steps serial, but several memory references are required, so fast memory access would be needed.
(2) An access control list search with multiple principal identifiers is likely to require a complex mechanism or it will be slow--or both. (This tradeoff between performance and complexity contrasts with the capability system, in which a single comparison is always sufficient.)
(3) Allocation of space for access control lists, which can change in length, can be a formidable implementation problem. (Compared with a capability system, the mechanics of changing authorization in an access control list system are inherently more cumbersome.)
Recognizing that the purpose of the access control list is to establish authorization rather than to mediate every detailed access attacks the first of these problems. Mediation of access would be handled more efficiently by a capability system. Suppose we provide for each pointer register a "shadow" capability register that is invisible to the virtual processor (Figure 7.7). Whenever a pointer register containing the unique identifier of an access controller is first used, the shadow register is loaded with a capability consisting of a copy of the addressing descriptor for the segment protected by the access controller, together with a copy of the appropriate set of permission bits for this principal.17 Subsequent references via that pointer register can proceed directly using the shadow register rather than indirectly through the access controller. One implication is a minor change in the revocability properties of an access control list: changing an access control list does not affect the capabilities already loaded in shadow registers of running processors. (One could restore complete revocability by clearing all shadow registers of all processors and restarting any current access control list searches. The next attempted use of a cleared shadow register would automatically trigger its reloading and a new access control list check.) The result is a highly constrained but very fast capability system beneath the access control list system. The detailed checking of access control falls on the capability mechanism, which, on individual memory references, exactly enforces the constraints specified by the access control list system.
The second and third problems, allocation and search of access control lists, appear to require more compromise of functional properties. One might, for example, constrain all access control lists to contain exactly five entries to simplify the space allocation problem. One popular implementation allows only three entries on each access control list. The first is filled in with the personal principal identifier of the user who created the object being protected, the second with the principal identifier of the (single) protection group to which he belongs, and the third with the principal identifier of a universal protection group of which all users are members. The individual access permissions for these three entries are specified by the program creating the segment.18
A completely different way to provide an access control list system is to implement it in interpretive software in the path to the secondary storage or file system. Primary memory protection can be accomplished with either base-and-bound registers, or more generally with a capability system in which the capabilities cannot be copied into the file system. This approach takes the access control list checking mechanisms out of the heavily-used primary memory access path, and reduces the pressure to compromise its functional properties. Such a mixed strategy, while more complex, typically proves to be the most practical compromise.
Authority to Change Access Control Lists
The access control list organization brings one issue into focus: control of who may modify the access control information. In the capability system, the corresponding consideration is diffuse. Any program having a capability may make a copy and put that copy in a place where other programs, running in other virtual processors, can make use (or further copies) of it. The access control list system was devised to provide more precise control of authority, so some mechanism of exerting that control is needed. The goal of any such mechanism is to provide within the computer an authority structure that models the authority structure of whatever organization uses the computer. Two different authority-controlling policies, with subtly different modeling abilities, have been implemented or proposed: self-control and hierarchical control.
The simplest scheme is self-control. With this scheme, we extend our earlier concept of access permission bits to include not just permission to read and write, but also permission to modify the access control list that contains the permission bits. Thus, in Figure 7.8, we have a slightly more elaborate access controller, which, by itself, controls who may make modifications to it. Suppose that the creation of a new segment is accompanied by the creation of an access controller that contains one initial entry in its access control list--an entry giving all permissions to the principal identifier associated with the creating virtual processor. The creator receives a pointer for the access controller he has just created, and then can adjust its access control list to contain any desired list of principal identifiers and permissions.19
Figure 7.8. Self-Control Authority Controlling Policy
Probably the chief objection to the self-control approach is that it is so absolute. There is no provision for graceful changes of authority not anticipated by the creator of an access control list. For example, in a commercial time-sharing system, if a key member of a company's financial department is taken ill, there may be no way for his manager to authorize temporary access to a stored budget file for a coworker unless the absent user had the foresight to set his access control lists just right. (Worse yet would be the possibility of accidentally producing an object for which its access controller permits access to no one--another version of the garbage collection problem.) To answer these objections, the hierarchical control scheme is sometimes used.
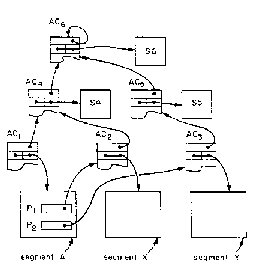
To obtain a hierarchical control scheme, whenever a new object is created, the creator must specify some previously existing access controller to regulate future changes to the access control list for the new object. The representation of an access controller must also be expanded to contain some kind of pointer to the access controller that regulates it (for example, a unique identifier). In addition, the interpretation of the permission bit named "ACLmod" is changed to apply to those access controllers that are immediately below the access controller containing the permission bit in the hierarchy. Then, as shown in Figure 7.9, all of the access controllers of the system will be arranged in a hierarchy, or tree structure, branching from the first access controller in the system. The creation of the first access controller must be handled as a special case, since there is no previously existing access controller to regulate it. The hierarchical arrangement is now the pattern of access control, since a user with permission to modify access control lists may add his own principal identifier, with permission to modify access to lower level access controllers, giving himself the ability to change access control lists still further down the hierarchy. Permission to modify access at any one node of the hierarchy permits the holder to grant himself access to anything in the entire subtree based on that node.20
The hierarchical control scheme might be used in a time-sharing system as follows. The first access controller created is given an access control list naming one user, the system administrator. The system administrator creates several access controllers (for example, one for each department in his company) and grants permission to modify access in each controller to the department administrator. The department administrator can create additional access controllers in a tree below the one for his department, perhaps for subdepartments or individual computer users in his department. These individual users can develop any pattern of sharing they wish, through the use of access control lists in access controllers for the segments they create. In an emergency, however, the administrator can intervene and modify any access control list in his department. Similarly, the system administrator can intervene in case a department administrator makes a mistake or is unavailable.21
Figure 7.9. Hierarchical Control
The hierarchical system in our example is subject to the objection that the system administrator and department administrators are too powerful. Any hierarchical arrangement inevitably leads to concentration of authority at the higher levels of the hierarchy. A hierarchical arrangement of authority actually corresponds fairly well to the way many organizations operate, but the hierarchical control method of modeling the organization has one severe drawback: the use and possible abuse of higher-level authority is completely unchecked. In most societal organizations, higher level authority exists, but there are also checks on it. For example, a savings bank manager may be able to authorize a withdrawal despite a lost passbook, but only after advertising its loss in the newspaper. A creditor may remove money from a debtor's bank account, but only with a court order. A manager may open an employee's locked file cabinet, but (in some organizations) only after temporarily obtaining the key from a security office, an action which leaves a record in the form of a logbook entry. A policeman may search your house, but the search is illegal unless he first obtains a warrant. In each case, the authority to perform the operation exists, but the use of the authority is coupled with checks-and-balances designed to prevent abuse of the authority. In brief, the hierarchical control scheme provides for exercise of authority but, as sketched so far, has no provision for preventing abuse of that authority.
One strategy that has been suggested in various forms is to add a field to an access controller, which we may call the prescript field. Whenever an attempt is made to modify an access control list (either by a special store instruction or by a call to a supervisor entry, depending on the implementation), the access-modifying permission of the higher-level access controller regulating the access control list is checked as always. If the permission exists, the prescript field of the access control list about to be modified is examined, and some action, depending on the value found, is automatically triggered. The following list suggests some possible actions that might be triggered by the prescript value, and some external policies that can be modeled with the prescript scheme.
(2) Identifier of principal making change is logged (the "audit trail").
(3) Change is delayed one day ("cooling-off" period).
(4) Change is delayed until some other principal attempts the same change ("buddy" system).
(5) Change is delayed until signal is received from some specific (system-designated) principal ("court order").
The goal of all of the policies (and the prescript mechanisms, in general) is to ensure that some independent judgment moderates otherwise unfettered use of authority.
The notion of a prescript, while apparently essential to a protection system intended to model typical real authority structures, has not been very well developed in existing or proposed computer systems. The particular prescript mechanism used for illustration can model only a small range of policies. One could, for example, arrange that a prescript be invoked on every access to some segment, rather than just on changes in the authority structure.
Discretionary and Nondiscretionary Controls
Our discussion of authorization and authority structures has so far rested on an unstated assumption: the principal that creates a file or other object in a computer system has unquestioned authority to authorize access to it by other principals. In the description of the self-control scheme, for example, it was suggested that a newly created object begins its existence with one entry in its access control list, giving all permissions to its creator.
We may characterize this control pattern as discretionary22 implying that the individual user may, at his own discretion, determine who is authorized to access the objects he creates. In a variety of situations, discretionary control may not be acceptable and must be limited or prohibited. For example, the manager of a department developing a new product line may want to "compartmentalize" his department's use of the company computer system to ensure that only those employees with a need to know have access to information about the new product. The manager thus desires to apply the principle of least privilege. Similarly, the marketing manager may wish to compartmentalize all use of the company computer for calculating product prices, since pricing policy may be sensitive. Either manager may consider it unacceptable that any individual employee within his department can abridge the compartmentalization decision merely by changing an access control list on an object he creates. The manager has a need to limit the use of discretionary controls by his employees. Any limits imposed on authorization are controls that are out of the hands of employees and are viewed by them as nondiscretionary. Similar constraints are imposed in military security applications, in which not only isolated compartments are required, but also nested sensitivity levels (e.g., top secret, secret, and confidential) that must be modeled in the authorization mechanics of the computer system. Nondiscretionary controls may need to be imposed in addition to or instead of discretionary controls. For example, the department manager may be prepared to allow his employees to adjust their access control lists any way they wish, with the constraint that no one outside the department is ever given access. In that case, both nondiscretionary and discretionary controls apply.
The key reason for interest in nondiscretionary controls is not so much the threat of malicious insubordination as the need to safely use complex and sophisticated programs created by suppliers not under the manager's control. A contract software house may provide an APL interpreter or a fast file-sorting program. If the supplied program is to be useful, it must be given access to the data it is to manipulate or interpret. But unless the borrowed program has been completely audited, there is no way to be sure that it does not misuse the data (for example, by making an illicit copy) or expose the data either accidentally or intentionally. One way to prevent this kind of security violation would be to forbid the use of borrowed programs, but for most organizations the requirement that all programs be locally written (or even thoroughly audited) would be an unbearable economic burden. The alternative is confinement of the borrowed program, a term introduced by Lampson. That is, the borrowed program should run in a domain containing the necessary data, but should be constrained so that it cannot authorize sharing of anything found or created in that domain with other domains.
Complete elimination of discretionary controls is easy to accomplish. For example, if self-controlling access controllers are being used, one could arrange that the initial value for the access control list of all newly created objects not give "ACL-mod" permission to the creating principal (under which the borrowed program is running). Then, the borrowed program could not release information by copying it into an object that it creates and then adjusting the access control list on that object. In addition, if all previously existing objects in the domain of the borrowed program do not permit that principal to modify the access control list, the borrowed program would have no discretionary control at all, and the borrower would have complete control. A similar modification to the hierarchical control system can also be designed.
It is harder to arrange for the coexistence of discretionary and nondiscretionary controls. Nondiscretionary controls may be implemented, for example, with a second access control list system operating in parallel with the first discretionary control system, but using a different authority control pattern. Access to an object would be permitted only if both access control list systems agreed. Such an approach, using a fully general access control list for nondiscretionary controls, may be more elaborate than necessary. The few designs that have appeared so far have taken advantage of a perceived property of some applications of nondiscretionary controls. The desired patterns usually are relatively simple, such as "divide the activities of this system into six totally isolated compartments." It is then practical to provide a simplified access control list system to operate in parallel with the discretionary control machinery.
An interesting requirement for a nondiscretionary control system that implements isolated compartments arises whenever a principal is authorized to access two or more compartments simultaneously, and some data objects may be labeled as being simultaneously in two or more compartments (e.g., pricing data for a new product may be labeled as requiring access to the "pricing policy" compartment as well as the "new product line" compartment). In such a case, it would seem reasonable that, before permitting data from an object to be read, the control mechanics should require that the set of compartments of the object being referenced be a subset of the compartments to which the accessor is authorized. However, a more stringent interpretation is required for permission to write, if borrowed programs are to be confined. Confinement requires that the virtual processor be constrained to write only into objects that have a compartment set identical to that of the virtual processor itself. If such a restriction were not enforced, a malicious borrowed program could, upon reading data labeled for both the "pricing policy" and the "new product line" compartments, make a copy of part of it in a segment labeled only "pricing policy," thereby compromising the "new product line" compartment boundary. A similar set of restrictions on writing can be expressed for sensitivity levels; a complete and systematic analysis in the military security context was developed by Weissman. He suggested that the problem be solved by automatically labeling any written object with the compartment labels needed to permit writing, a strategy he named the "high water mark." As an alternative, the strategy suggested by Bell and LaPadula declared that attempts to write into objects with too few compartment labels are errors that cause the program to stop.23 Both cases recognize that writing into objects that do not have the necessary compartment labels represents potential "declassification" of sensitive information. Declassification should occur only after human judgment has been interposed to establish that the particular information to be written is not sensitive. Developing a systematic way to interpose such human judgments is a research topic.
Complete confinement of a program in a shared system is very difficult, perhaps impossible, to accomplish, since the program may be able to signal other users by strategies more subtle than writing into shared segments. For example, the program may intentionally vary its paging rate in a way users outside the compartment can observe, or it may simply stop, causing its user to go back to the original author for help, thereby revealing the fact that it stopped. This problem has been characterized with the phrase "banging on the walls."
Major Players
Microsoft's Exchange Server is the leading messaging and collaboration product on the market today, providing e-mail, group scheduling, collaboration, and applications such as workflow and routing.
The other market leader, Lotus Development Corporation, offers Notes, an integrated Internet client, and Domino server for messaging, collaboration, and Internet and intranet applications.
Dataware Technologies, Inc. provides its clients with advanced, Web-based knowledge solutions, application design consulting, and implementation expertise. Dataware's knowledge solutions improve an organization's business processes, products, and services, putting the organization at a competitive advantage through the deployment of Web and Intranet-based applications that leverage the value of their knowledge assets. More than 2,000 organizations, including corporations, government agencies, commercial publishers, and educational institutions, are currently using Dataware knowledge solutions as an integral part of their business. (One Canal Park, 2nd Floor, Cambridge, Massachusetts 02141, Phone: (617) 621-0820, Fax: (617) 621-0307, http://www1.dataware.com/).
PC DOCS/Fulcrum solves real-world business problems through document and knowledge management software. PC DOCS/Fulcrum's products deliver a controlled way to manage corporate information and Web content, and an innovative way to understand it. Customers rely on these products to gain access to the information that matters and then analyze and re-use this information, leveraging its value and conferring a sharp competitive edge. PC DOCS/Fulcrum provides solutions to professional services firms, manufacturers, financial services organizations, and government agencies and, as a global organization, has offices and partners throughout the world. For more information, visit http://www.pcdocs.com. (2005 Sheppard Avenue East, Suite 800, Toronto, Ontario, Canada, Phone: (416) 497-7700, Fax: (416) 499-7777).
Verity is a leading provider of enterprise knowledge retrieval solutions for corporate Intranets, online publishers, e-commerce vendors, and market-leading OEMs and ISVs. Verity's product suite enables organizations to turn corporate Intranets into a powerful knowledge base by creating corporate portals, making business information accessible and reusable across the enterprise. Verity's leadership has been recognized by numerous organizations, including Delphi Consulting, which gave Verity the Market Recognition Award, based on a survey of 600 corporate users. Verity's comprehensive and integrated product family enables enterprise-wide document indexing, classification, search and retrieval, personalized information dissemination, and hybrid online and CD publishing all from the same underlying Verity collection. (894 Ross Drive, Sunnyvale, California 94089, Phone: (408) 541-1500, Fax: (408) 541-1600, http://www.verity.com/).
The mission of MosaicSoft, Inc. is to create open, flexible, and scalable software products that increase productivity in organizations of any size that are open in architecture and scale with the growth of the organization. The first such product is DocSmart, with other products to follow. All products are based upon state-of-the-art technologies and strategic partnerships that are formed with industry leaders. (22982 Mill Creek Drive, Laguna Hills, California 92653-1248, Phone: 949-609-0840, Fax: 949-583-9213, http://www.mosaicsoft.com/).
Founded in 1980, Excalibur Technologies Corporation is the pioneer of innovative knowledge retrieval software solutions that transform information into knowledge. Excalibur empowers people and enables organizations to quickly analyze, index, catalog, browse, access, search, retrieve, and more easily share all enterprise knowledge assets, whether they are paper, text, images, or video. As the world's leading developer of high-performance software products for the intelligent search and retrieval of all knowledge assets irrespective of media type, over Intranets, LANs/WANs, extranets, and the Internet, Excalibur products fulfill mission-critical needs to leverage extant intellectual property to meet a need, solve a problem, or answer a question. (1921 Gallows Road, Suite 200,Vienna, VA 22182-3900, Phone (703) 761-3700, (800) 788-7758, http://www.excalib.com/home2.html).
Primus Corporation is a leader in Web-based problem resolution and knowledge management software, providing solutions that enable businesses to deliver superior customer service and support to maintain competitive advantage in the e-business marketplace. Successful companies worldwide use Primus® SolutionSeries? software and services to create, capture, reuse, and share up-to-the-minute knowledge that can be easily accessed to solve problems, answer questions, or find options for customers on the spot. (1601 Fifth Avenue, Suite 1900, Seattle, Washington 98101, Phone: (206) 292-1000, Fax: (206) 292-1825, http://www.primuscorp.com/).
New Technology
The rise in power, connectivity, content, and flexibility is dramatically reshaping relationships among people and organizations, and quickly transforming our processes of discovery, learning, exploration, cooperation, and communication. It permits us to study vastly more complex systems than was hitherto possible and provides a foundation for rapid advances in the understanding of learning and intelligent behavior in living and engineered systems. Today's challenge is to realize the full potential of these new resources and institutional transformations.
The National Science Foundation (NSF) is investing in fundamental research and education designed to realize the full potential of this emerging era. Taking shape within an ambitious, foundation-wide effort called Knowledge and Distributed Intelligence (KDI), these investments are focused on deriving human knowledge from intelligent access to information, wherever it occurs and in whatever form it is to be found. KDI efforts aim to improve our ability to discover, collect, represent, transmit, and apply information, thereby improving the way we conduct research and education in science and engineering. These efforts promise to change how we learn and create, how we work, and how we live.
NSF aims to achieve, across the scientific and engineering communities, the next generation of human capability to:
• Generate, gather, model, and represent more complex and cross-disciplinary scientific data from new sources and at enormously varying scales.
• Transform this information into knowledge by combining, classifying, and analyzing it in new ways.
• Deepen our understanding of the cognitive, ethical, educational, legal, and social implications of new types of interactivity.
• Collaborate in sharing this knowledge and working together interactively.
To achieve the aims of KDI, the NSF has defined three areas of focus:
• Learning and intelligent systems.
• New computational challenges.24
Knowledge Networking
The aim of knowledge networking (KN) is to facilitate the evolution from distributed information access to new technical and human capabilities for interactive knowledge creation and use. Through this evolution, interdisciplinary communities can be joined in sharing data and building knowledge to address complex problems traditionally treated within disciplinary boundaries.
KN focuses on the seamless integration of knowledge and activity across content domains, space, time, and people. Modern computing and communications systems are beginning to provide the infrastructure to send information anywhere, anytime, in mass quantities--very high connectivity. Further advances in computing and communications hold the promise of fundamentally accelerating the creation and distribution of information. The creation of new knowledge in groups, organizations, and scientific communities requires additional advances beyond the ability to collect, process, and transmit large amounts of data. Building upon the growing capability for connectivity, the knowledge networking initiative is designed to support the creation and thorough understanding of:
• New forms of and tools for data gathering, such as sharable remote instruments and large-scale Web-based experimentation.
• New ways of transforming distributed information into seamlessly sharable, universally accessible knowledge.
• Appropriate processing and integration of knowledge from different sources, domains, and non-text media.
• Useful communication and interaction across disciplines, languages, and cultures.
• New tools and means of working together over distance and time.
• Efficacious socio-technical arrangements for teams, organizations, classrooms, or communities, working together over distance and time.
• Cognitive dimensions of knowledge integration and interactivity.
• Deepening understanding of the ethical, legal, and social implications of new developments in knowledge networking.
• Sustainable integration, long term use, and life-cycle effectiveness of knowledge networks.
Both technological capability and human interaction in the overall scientific process must evolve if knowledge networking is to reach its full potential. Achieving the new capabilities envisioned for knowledge networking and making them widespread, universally accessible, and sustainable over the long term specifically requires research into the human processes involved in creating and disseminating knowledge. Multidisciplinary knowledge networking efforts will fail unless we understand and provide for the environments that enable skill sets, conceptual models, and values to be rapidly shared across disparate fields, and that account for the institutional and cultural dimensions of knowledge sharing and interaction.
Examples of selected outcomes of KN activities could include:
• Increasing capabilities of high-speed, high-capacity networks, and the development of principles for future network design.
• Building and linking complex data repositories that integrate widely-scattered sources of information in disparate forms.
• Creating Internet-based "collaboratories" that enable multidisciplinary teams of researchers and educators, participating from their home laboratories, offices, and classrooms around the world, to work together as if they were meeting face-to-face. Participants would be able to interact with each other, control remote instruments, select and screen data, and observe experiments and phenomena--all on a live, real-time basis.
Learning and Intelligent Systems
Efforts to understand the nature of learning and intelligence and the realization of these capacities in the human and the mind are among the most fundamental activities of science. The learning and intelligent systems (LIS) focus emphasizes interdisciplinary research that:
(1) Advances basic understanding of learning and intelligence in natural and artificial systems.
(2) Supports the development of tools and environments to test and apply this understanding in real situations.
The aim of LIS is to unify experimentally- and theoretically-derived concepts related to learning and intelligent systems and to promote the use and development of information technologies in learning across a wide variety of fields. This long-range goal is very broad and has the potential to make significant contributions toward innovative applications. To pursue this goal in a realistic and sustainable fashion, LIS focuses on fundamental scientific and technological research undertaken in the rigorous and disciplined manner characteristic of NSF-supported endeavors. The initiative ultimately should have a major impact on enhancing and supporting human intellectual and creative potential.
LIS encompasses studies of learning and intelligence in a wide range of systems, including (but not limited to) the:
• Nervous systems of humans or other animals.
• Networks of computers performing complex computations.
• Robotic devices that interact with their environments.
• Social systems of human or non-human species.
• Formal and informal learning situations.
LIS also includes research that promotes the development and use of learning technologies across a broad range of fields. Development of new scientific knowledge on learning and intelligent systems, and its creative application to education and learning technologies, are integral parts of the LIS focus.
Selected examples of LIS research and education efforts include the following:
• Understanding the functions of the brain--how it handles complex information and computations, as in learning science and mathematics; how it acquires, comprehends, and produces language; how it represents and operates upon sensory information, as in spatial navigation; and how it produces actions, as in reaching for and grasping objects--and applying this understanding to efforts to enhance human learning and develop intelligent systems.
• Combining experimental procedures for training in skills, computational modeling, mapping of brain functions, and automated tutoring to develop more effective approaches to teaching people to read.
• Supporting learning technology research centers. These centers would promote the transfer of advances in learning technologies from the lab to the classroom and train multidisciplinary learning researchers.
• Creating machines that can present information in a way that best meets the needs of a user. For example, if a machine "senses" (from reaction times or even observed facial expressions) that a student is bored, it might respond by switching from a theoretical approach to one that is more experiential, offering illustrations that incorporate the person's known hobbies and interests.
New Computational Challenges
New computational challenges (NCC) focuses on research and tools needed to:
• Model, simulate, analyze, display, or understand complicated phenomena in a collaborative environment.
• Control resources and deal with massive volumes of data in real-time.
• Predict the behavior of complex, multi-scale systems in order to exploit the potential for decision-making and innovation across science and engineering.
Much of NCC research might be described briefly as the leading edge of computational science and engineering. Based on continuously expanding computational power, improved software systems and tools, and better understanding of the power of the computational paradigm, fundamental advances in science and engineering have been achieved. However, phenomena, data, and systems of interest in the immediate future so exceed in scope, scale, and dimensionality what can be handled by present techniques that incremental advances will not suffice. New computational schemata, such as quantum computing or biomimetic computing, are needed.
Models, tools, and resources must be shared among many researchers in different places. Moreover, a key need is immediacy--control of networked resources in real time and tailored to people's needs and capabilities, "on-the-fly" analysis of data to guide experiments or manage situations as they happen. These features--scope, scale, dimensionality, shared use, and immediacy--distinguish NCC from the earlier work on which it builds. NCC aims to enable collective understanding and effective management of complex systems. These aims will require quantum advances in hardware and software to handle complexity, representation, and scale; to enable distributed collaboration; and to facilitate real-time interactions and control.
Another distinguishing aspect that expands the traditional view is the overlap with knowledge networking and learning and intelligent systems. Here, issues such as management and manipulation of data, extraction of information from data or models, amplification of intelligent behavior, and communication in a useable form to those who need or can exploit the enabled scientific advances come into play. Hence, a description of NCC activities must be undertaken with this broader context in mind.
The challenging problems now enabled by significant advances in information technology and required by research and applications in science and engineering naturally combine the following features: They are computationally intensive, they are data-intensive, and they are representationally difficult. It is this merging of computation, data, and representation for highly complex problems that makes NCC a significant new challenge for NSF. The data-intensive aspects of NCC provide a linkage to and overlap with knowledge networking, while the representational aspects are closely related to learning and intelligent systems.
Scientific problems with these features include the following:
Simulation and analysis of complex phenomena that span large scales of space and/or time, are highly nonlinear, require high resolution, result in large data sets, and require a quantum leap in computational power:
• Fluid flows complicated by dimensionality or geometry or by multiphase, transport, or chemical or thermal processes.
• Molecular dynamics and multibody problems.
• Materials modeling especially of the transition from microstructure to macro properties.
• Interrelation of structure and function of muscles, human brain, etc.
• Biological modeling from proteins through living organisms to ecological systems.
• Modification of a structure to respond to impending changes based on data from embedded sensors, e.g., automatic survivability enhancing in buildings a few seconds prior to an earthquake.
Real-time control of experiments:
• Steering an experiment based on real-time feedback and analysis (e.g., light microscopy study of living cells).
• Real-time control of instruments for climate and astronomical observations.
Representation, access to, and use of data:
• Visualization of multidimensional, multivariable phenomena, often in real time.
• Recognition of known or unknown patterns.
• Graphic representation of data, especially high-dimensional data or data mapped against other data such as GIS.
• "Intelligent" decisions based on connotation or imperfect information including "smart" instruments, "smart" manufacturing, expert systems, and natural language processing; support and integration of multimodal data, particularly when some modalities were unknown at the time of conceptual analysis, generation, or collection.
Selected outcomes from NCC research could include:
• Development of new algorithms for modeling phenomena involving multiple scales and enormous complexity (such as species invasions in an ecosystem and the consequences for conservation biology, biological control, and agriculture).
• Enhanced technologies for storing, organizing, and searching digital libraries and databases to provide wider, faster, and more effective access to knowledge. New techniques for encoding maps, videos, and other images, and new search methods for accessing data in image form, such as electron micrographs, specimen photographs, and molecular models, could result.
• Advances in pattern recognition and data mining, that is, discovering "unusual" items in a massive set of data. Today's methods of data mining are appropriate only for modest-sized databases. Enhanced pattern recognition technology holds tremendous promise for reliably and effectively screening mammograms or pap smears for abnormalities and for mining biological databases to gain a better understanding of the function of genes.
• Expanded availability of magnetic resonance imaging (MRI) videos in real time.
The proposal deadline for grant awards was May 17, 1999. With a budget of approximately $50 million, the NSF KDI program anticipates funding 40 to 50 proposals of varying size and duration in September of this year.
Forecasts and Markets
Dataquest. A report by Dataquest predicts "businesses will spend $4.5 billion on knowledge management products and services by 1999." The principal driving force for this is a growing realization that effective management of knowledge can add real value to the organization.25
Meta Group. By 2003, over 75% of global 2000 organizations will have instituted knowledge managenets to drive innovation, enhance productivity, and augment diminished human capital. Soft issues (culture, motivation, metrics, etc.) will present the greatest implementation challenges as KM functionality (visualization/navigation, capture, search, push, categorization, and map) becomes embedded in teamwork, information and process management, multimedia, desktop, and business applications.
Further, groupweb products will continue to evolve around the following trend: By 2001 or 2002, collaborative facilities found within Intranet and messaging platforms will evolve from basic discussion, connectivity, and productivity applications (discussions, scheduling, information/process management, shared applications) to dynamically linkable yet well-integrated "teamwork environments." Those environments will enable intelligent knowledge capture and distribution, while providing Web-enabled task and information management facilities.
This trend indicates that cultural issues, as well as technical challenges, will continue to be overcome, and that KMN construction will become a de facto part of organizations through the next millennium. Information acquisition and management, real-time collaboration, and precise, targeted distribution of organizational knowledge will ultimately become part of the fabric within which corporations operate. Ultimately, groupweb and KM functionality will become inseparable, but it will be another few years before cultural and technical integration is totally seamless.26
Fastwater. Fastwater (www.fastwater.com) analyst Bill Zoellick grabbed everyone's attention early by showing research that labels KM as a $2.5 billion "early market." He pointed out, however, that the $2.5 billion (up from $2 billion in 1997) is an oxymoron. There is no such thing as a "$2.5 billion early market." What there is, he said, is an embryonic software and services market being pulled along in the slipstream of the Intranet juggernaut. The problem is that the KM industry is being lulled into thinking it does not need to develop its own voice and create its own demand--that Microsoft (www.microsoft.com) and Lotus (www.lotus.com), who together dominate the Intranet messaging space, will not leave much opportunity for very strong players to emerge.
Zoellick's research predicts about a 40% growth rate for true knowledge management software and services and divides it into enterprise and departmental applications. In the enterprise space, where cross-departmental knowledge sharing, cost savings, and productivity are most important, Microsoft and Lotus are and remain poised to be the dominant players. For the department level, where cost savings and improved service and quality are leading goals, Dataware (www.dataware.com), Fulcrum (www.fulcrum.com), and Grapevine (www.grapevine.com) join the big two.
Choosing a much smaller $90 million market figure--representing only the sale of KM-labeled software and not services and other system components--Palmer and Zoellick agreed that a $5 billion market in five years is feasible. A key to getting there, according to Palmer, is "you need to talk to buyers" and address their needs.27
Forrester Research. The forecast market for customer interaction applications, worldwide:
Ovum Ltd. The forecast market for knowledge management software and services:
Industry/Technology Roadmaps
At the University of Edinburgh, AIAI28 has produced a framework for developing knowledge asset roadmaps to support strategic knowledge management initiatives. Roadmaps have been used by AIAI with a number of commercial and government organizations, as well as in support of pan-European research "clubs."
Knowledge asset roadmaps are mechanisms enabling organizations to visualize their critical knowledge assets, the relationships between these, and the skills, technologies, and competencies required to meet future market demands.
The goal of developing a knowledge asset roadmap is to increase an organization's competitiveness by:
• Enabling all sections of an organization to appreciate the current and future critical knowledge assets and their linkages to business objectives.
• Guiding strategic research, development, marketing, and investment decisions.
• Identifying current and future knowledge assets required to meet business objectives and placing them on a timeline.
• Identifying critical actions and projects required to develop and maintain the assets in the context of the business objectives.
• Specifying the relationship between the assets, actions, projects, and business objectives of the organization and the roles that each asset is expected to have in achieving the objectives.
A knowledge asset roadmap provides a coordinated picture of the various parts of an organization's overall knowledge management program such that the diverse and dispersed efforts can be seen as part of the whole and can be justified as such.
Knowledge assets are the knowledge regarding markets, products, technologies, and organizations that a business owns or needs to own and which enable its business processes to add value and generate profits. Knowledge management is not only about managing these knowledge assets, but managing the processes that act upon the assets. These processes include: developing knowledge; preserving knowledge; using knowledge; and sharing knowledge. Therefore, knowledge asset management involves the identification and analysis of available and required knowledge assets and knowledge asset-related processes and the subsequent planning and control of actions to develop both the assets and the processes so as to fulfill organizational objectives.
Technology roadmaps are used internationally to identify and reach consensus on future technology requirements. Technologies are selected on the basis of their potential contribution to marketplace competitiveness and their strategic applicability.
The various elements of a technology roadmap are illustrated in Figure 7.10. A technology roadmap is split into a number of facets, which collect together major types of work within the program. Facets appear as horizontal running bands in the roadmap itself. The particular facets required on a roadmap will depend on the purpose to which it will be put.
Within each facet, there could be a number of threads, which are used to relate program elements together in a communicable way. Threads may carry on for the whole program duration if they are sufficiently important, and it is suggested that strong threads are identified which do carry on in this way. However, threads could also be for a more limited duration during a specific phase of the program. Threads can be a good mechanism to keep particular technical or organizational themes running through the program. Threads appear as horizontal lines within a facet and will have annotations at the appropriate date for major program elements that relate to the thread. Ties are used to show major connections between program elements. They are shown on the roadmap as vertical or rightward pointing diagonal lines showing the supporting relationship between the elements. Ties are one major way in which justifications, proposals, and business cases for lower-level activities can be better presented in terms of higher-level objectives. AIAI has used the ideas and techniques behind technology roadmaps in order to develop a framework for developing knowledge asset roadmaps to support knowledge management initiatives.
Figure 7.10. Elements of a Roadmap
A knowledge asset roadmap is built by carefully relating knowledge management actions upward to business objectives and strategy and downward to specific knowledge assets.
The first step in establishing a roadmap for a program is to set up a number of facets that will be helpful. Some examples of general facets are given below. In practice the facets need tailoring to the specific needs of the program and may require further revision as the roadmap is developed.
Business objectives and business drivers with threads such as:
• More effective capture and use of business knowledge.
• More effective product innovation.
• A more efficient research process.
• Objectives relating to new products or services.
Lead projects and knowledge management actions:
• The threads could relate the chosen projects to the major types of task or major challenges that the program needs to address.
Knowledge management enablers with threads relating to:
Also, facets should include knowledge-related processes and knowledge assets.
The development approach needs to be tailored to the specific needs of the program. An example of such an approach is:
(1) Examine the strategic business plans and taking each business objective in turn.
(2) Determine which knowledge assets and processes will have to be in place to support this objective. The knowledge assets need to be described in sufficient detail so that current knowledge assets can be evaluated and subsequent knowledge gaps can be addressed.
(3) Analyze the status of the knowledge assets and processes.
(4) Identify which knowledge management enablers (e.g., technologies, processes, and organizational changes) are required to achieve the objective, along with the time-scales for their insertion.
(5) Add any necessary intermediate developments of assets, processes, and technologies.
(6) Align knowledge asset road ties and linkages and sort out timeline dependencies.
Having established a knowledge asset roadmap, it should be communicated as widely as possible within the organization. Thereafter, any new knowledge management enabler entries on the roadmap could be justified in a number of ways. One reason might be that they are in support, or allow attainment, of an objective or entry already on the roadmap. In general, well-justified knowledge management enabler roadmap entries would:
• Relate to identified existing business objectives.
• Open the opportunity for future business prospects.
• Be based on current knowledge assets.
• Lead to the development of future knowledge assets.
The process of developing the roadmap and the completed document provide a framework that allows individual knowledge management actions to be defined and justified in terms of their contribution to overall objectives.
• Setting of time-scales for development of new assets.
• Identification of key assets that support many objectives.
• Identification of opportunities to "pull through" new assets ready for exploitation.
• Identification of opportunities for strategically competitive products and services that combine a set of assets unique to the organization.
• Identification of knowledge gaps that need to be filled.
• Identification of critical paths from asset developments to meeting business objectives.
• More effective communication between participants and observers of the program (e.g., users, researchers, technicians, managers, and directors involved in the various aspects of the program).
• Management aids for those involved in carrying out the program and measuring its progress.
• Reduction of investment risk through better prioritization of projects.
• Sensible decisions to be taken on the opportunities for further exploiting the results of the program.
The roadmap reflects the current state of the interrelationships between work in progress, work proposed for the future, and the overall milestones and aims of the program. Hence, it can serve as a framework for monitoring progress against overall objectives.
Knowledge asset roadmaps are evolutionary and, as such, need to be actively maintained and updated at program reviews, when business objectives change, when there is a shift in knowledge asset focus, and as new assets mature. An owner of the roadmap should be identified. For example, the organization's knowledge manager and a process for maintaining and managing the roadmap should be defined to suit the organizational structure within the business and type and size of the knowledge management program.
The roadmap is not an alternative to individual project plans and more detailed management aids. It is a high-level overall coordination and communication aid. As such, it cannot be expected to show all knowledge assets and relevant ties. Special versions of the roadmap can be developed for specific audiences or showing relevant facets, threads, and ties for a specific purpose.
Knowledge asset roadmaps can be used by organizations as a strategic planning tool to identify the gaps between their current know-how and future requirements and to make informed investment decisions to close this gap. They provide a global timetable of expected capabilities and results in terms of an organization's objectives, its knowledge assets, and the related actions required for achieving and preserving the assets. In addition, they provide a framework for coordinating the activity within a knowledge management or other strategic program, thereby allowing the measurement of overall progress.
Risk Factors
Education
Since knowledge management and knowledge sharing is very much an evolving concept, the approaches and services in the marketplace will be changing and adapting to new ideas. A recent McKinsey & Co. study points out that most companies do a very poor job of managing their talent. They don't know what skills they need or what their people have.29 So, if that is the case, what happens next in a market where the vendors and consultants see the role of technology in KM, but many customers have not yet made the direct link?
Education, say some experts, is one piece of the puzzle. More information needs to be disseminated about knowledge management--about how knowledge sharing technologies can help organizations leverage their knowledge for gain. According to some consultants and vendors, customers are asking for technology solutions that will allow them to seamlessly access, share, manage, and reuse information, but aren't asking for it by that name.30
Legal
There are still murky legal issues that will cause problems. What portion of an employee's knowledge about the company's activities belongs to the company, and what belongs to the individual? Does documenting the knowledge into a KM system change the legal situation? If you document after a project how you could have done it better, is someone going to sue you for not doing it better?31
Organizational Culture
Sharing insights and best practices is a behavior that is critical to the success of any knowledge management system, yet it is counter to the culture found in most organizations. This cultural issue is seen by many experts32 as the main obstacle to implementing knowledge management since, for most firms, facilitating the capture of useful business knowledge represents a major change in employee behavior. In a 1997 survey of Fortune 1000 executives, 97% of respondents said that there were critical business processes that would benefit from more employees having the knowledge that was currently within one or two people, and 87% said costly mistakes are occurring because employees lack the right knowledge when it is needed.33 While knowledge is one of the few resources that can increase in value as it is shared, the inter-competitive environment in many organizations fosters knowledge hoarding; in these firms, unique possession of knowledge is seen as power and job security. As with any major transition in employee behavior, this change from a knowledge-protective to a knowledge-sharing environment needs to be consistently supported in multiple and interrelated ways.34
Unstructured Information
One of the greatest challenges for knowledge sharing software is capturing what transaction-based systems cannot--what's in people's minds. Co-founder and director, Thomas Craig, of Monitor Co. says, "It's linking the tangible side--the hardware and software--with the behavioral, cultural, commitment building, action-taking side."35
• Most knowledge is still recorded as unstructured natural language, with all its shortcomings of precision and conciseness.
• Documents and, in particular, small parts of them such as sentences, are often hard or impossible to find, hard to update cooperatively, and hard to keep coordinated.
• Merging and linking information from various sources is difficult; for example, "replication," as used in Lotus Notes, is a very crude approach and usually too coarse-grained.
• Lacking any AI components, most systems today offer nothing in the way of inference, semantic checking, or natural language processing. The thesaurus function in some search engines is as far as it goes today.
• Documents are often quite knowledge-poor, i.e., the density of useful knowledge per megabyte (or per minute of reading) is too low, and finding and organizing the "nuggets" of knowledge is too difficult. (AI-style knowledge-based systems are the best way of dealing with this, but they are very hard to build and usually not expressive enough.)
• Terminology is uncontrolled. Within a single document, a word may have several meanings that are difficult to disambiguate. In addition, people may use various terms for the same concept.36
Privacy and Profiling
A note has been submitted to the World Wide Web Consortium, which means it is for discussion only. The authors37 argue that it is possible to leverage existing Internet standards and proposals to provide sites with access to demographic and other personal profile information, while placing users in control of how this information is disclosed. They explain that users need to control which personal information gets disclosed or withheld from a particular Website in order to maintain privacy. Users need to be notified what profile information is requested from a particular site, allowing them to choose who may use this information, for what purposes, and under what conditions; including retaining the right to publish updated records and to retract usage permissions. In addition, information stored locally on a user's machine may be encrypted to keep it safe from unauthorized usage. Further, users may want to present a different persona at different Websites or at different times of the day. Probably the best example of this is the distinction between the work and home persona. This is no doubt an issue that will become increasingly bigger whether it be the Web, the corporate intranet, or groupware.
Managing Chaos
In short, investing in knowledge assets is probably the only sensible way of managing the realities of chaos and/or complexity. The best that any knowledge repository or knowledge network can do is to play an informative role. With this goes a fair amount of risk. The reliability, validity, accuracy, and relevancy of the information obtained from the knowledge repositories and knowledge networks contribute toward the knowledge risk levels. The profile of the persons/sources you network with become vital. You need to know who they are, what knowledge they can contribute, how they are connected, what their competencies and competency levels are, etc.
Let's assume you build your knowledge repository on a Web page. A possible way of managing the risk of the information/articles that you place on the Website is to build a mechanism into the page that requires each user of a given source/article to validate the information in terms of a matrix between various factors, such as relevance, accuracy, and academic/scientific value, before exiting that source. The value/risk judgment of that given knowledge is thus determined by the hard school of learning--the users that access that knowledge and their clinical evaluation of the value thereof.
This way you simplify complexity. You don't need rocket science formulas or doctors to evaluate the information; you manage the risk based on the premise that, if it has value for the majority, it will be worth your while to invest time in reading that information. With some manipulation of the values of the variables in the matrix, you should be able to dictate to your search engine on whether you want a list of articles/information sources that are scoring high on relevance, accuracy, or academic value, etc.38
The range of knowledge management solutions to these problems will depend on technology. Very sophisticated retrieval engines will continue to be built that exceed today's search standards for "recall" and "precision." In addition, solutions to the glut problem must employ technology to abstract (or highlight) and synthesize multiple hits from searches. When one adds various administrative functions such as permission and security, a "knowledge server" concept emerges. The organizations that exploit technology effectively may be considered "e.knowledge" participants; e.knowledge is the application of electronic technologies to the creation, classification, synthesis, analysis, storage, retrieval, and display of knowledge.
Electronically processing knowledge still won't do the whole job. People are needed to certify and calibrate the sources, add value through analysis, and make recommendations that are customized to the consumer's environment much as help desks do today. Conduits to various common-interest communities must be provided, and facilities for the consumer to query the experts should be included.39
COTS Analysis40
6DOS solutions help corporations achieve their objectives by encouraging employees, customers, and vendors to communicate and collaborate. 6DOS products use human expertise, automated tracking, and reward systems to efficiently increase and enhance knowledge sharing.
AGE Logic, Inc. specializes in remote access and application sharing over the Internet.
Autonomy's Knowledge Suite product builds a profile of workers and what they're working on so that workers can discover each other's work in a large organization.
Assistum (Assistum, Ltd.) provides a suite of tools for the creation and application of custom knowledge bases by individuals, or teams of experts, which allows them to deepen their understanding of the practical and commercial issues behind a commercial decision.
Beacon Interactive Systems develop contact management, customer service, and project management software for use over the Intranet or Lotus Notes.
Bittco Solutions produce brainstorming and decision-support groupware for the Macintosh and Windows environments.
C.A.Facilitator provides a virtual meeting area with chat, voting, and surveying functions.
CBR Content Navigator by Inference Corporation includes a family of products that helps users access knowledge most pertinent to their needs. The products include search and retrieval plus knowledge indexing and content management.
Changepoint Corporation sells products that provide interactive project planning and management with critical path planning and a complete process for sharing the plan's expectations.
Cipher Systems has groupware that supports competitive intelligence and knowledge management.
Computer Application Services, Inc. is a mainframe software vendor specializing in a suite of electronic mail, personal productivity, and application-development tools.
Data Fellows Software combines personal information managers, contact managers, relational databases, free-form mapping tools, and e-mail systems.
EDGE Software has created a family of applications that brings together the power and benefits of knowledge management with continuous process management.
Excalibur's family of products solve a multitude of knowledge retrieval challenges and help manage assets ranging from paper, text, images, and video.
First Floor Software provides Web-based business document delivery solution for developers.
Fulcrum Knowledge Network provides a rich, complete map of your enterprise knowledge base. You can span vast repositories of information with a single query. You can find only the information you need, regardless of its format or location.
Grapevine produces a knowledge management plug-in for use with Lotus Notes/Domino and Netscape Compass Server (now in beta). It uses personalized interest profiles, auto-classification of information, and custom notification to avoid information overload on corporate Intranets.
Group Logic develops applications for remote whiteboarding and text-based collaboration.
Hyperknowledge, Inc. produces a knowledge management software package and offers consulting support; both of which are based on its proprietary "what, how, why" philosophy.
Imaging Solutions, the knowledge management division of Wang New Zealand, Ltd. Effective knowledge management is the delivery of knowledge to the right people at the right time.
Internet Knowledge Kiosk by the Molloy Group uses a proprietary cognitive processor that imitates human thought processes for dynamic problem solving and knowledge retrieval.
Intraspect integrates the best features of collaboration, information search and retrieval, groupware, and database software to create the first environment where people can easily share and reapply each other's work.
Intr@vation focuses on groupware for proposal development.
Kanisa, Inc. creates software applications that knowledge-enrich business processes and customer relations.
KnowledgeDirect by PricewaterhouseCoopers. With Knowledge Direct and its network of virtual communities, you can now have a live link to the sustainable competitive advantage that fast, qualified knowledge provides.
KnowledgeX Enterprise creates a searchable database of content generated from within a corporation (text, spreadsheets, presentations) or gleaned from the Internet. It also shows relationships of content to individuals in the organization.
LearnerFirst software is one of the best investments you can make in knowledge-based assets. The software provides a means for capturing and preserving a great deal of information about how to manage knowledge.
Lotus Notes/Domino provides state-of-the-art e-mail, calendaring, group scheduling, Web access, and information management--all integrated in an easy-to-use and customizable environment.
Microsoft Exchange Server is the smart choice for your long-term business needs. It is the ideal platform for business critical messaging, with unmatched interoperability, low-cost administration, and powerful collaborative features.
Milagro's K.Net is the first knowledge network product positioned for the knowledge management movement.
Netscape Collabra provides collaboration services through discussion groups. A company's employees can participate in private "virtual meetings" that break down barriers of time and distance. Users can create their own discussion groups to share product development ideas, allow customers to discuss problems and request information, check the status of requests and billing information, track and distribute competitive information from the field, and develop communities of interest around products and services.
Orbital Technologies, a privately held software company, is the leading vendor of expertise matching and profiling technology to help knowledge flow and discovery within the enterprise. In other words, the "know-how" and "know who" within the organization.
ProcessBook by Performigence gives employees access to knowledge for work processes in multiple formats and media.
Tango clarifies familiar tangible factors such as pricing and capacity, as well as critical intangible factors such as image, know-how, personal chemistry and individual competence.
Verity is a leading provider of corporate knowledge retrieval solutions. They offer an integrated product family to manage all phases of the knowledge lifecycle.
Wincite Systems' customized software and services give organizations the power to leverage intelligence, improve decision-making, and increase the bottom line.
XD (Executive Desktop) by SapuraSoft is a complete EIS (executive information system) development environment that allows users to develop graphical interactive management reporting systems.
XpertRule KBS by Attar Software is a knowledge-based system development package with in-built resource optimization.
Basic Conferencing
Technology Background
Collaborative conferencing technologies, in general, are tools that enable real-time multi-person interactions between geographically dispersed individuals. The technologies include videoconferencing, data conferencing (workgroup and whiteboard systems), and audioconferencing. Videoconferencing allows people in different locations to meet through video and audio communication. Data conferencing allows workers in the same or in different locations to access and work on a file simultaneously. Audioconferencing allows people in different locations to communicate verbally.41
Technically, conferencing technologies are a computer-based system that provides a multi-user interface, communication and coordination within the group, shared information space, and the support of a heterogeneous, open environment which integrates existing single-user applications. They can be categorized according to a time/location matrix using the distinction between same time (synchronous) and different times (asynchronous), and between same place (face-to-face) and different places (distributed).42
Collaborative conferencing revolutionizes vital, everyday tasks such as corporate management, training, and communication between geographically dispersed teams. This technology enables interactive, live sharing of audio, video, and desktop applications during a conference session. Multiple users participating from geographically distant locations can collaborate on an application and share visual information while they discuss a project together. Internet voice and video and PSTN video increase productivity and reduce travel time and cost, while offering a personal mode of communication. Applications are wide-ranging and include investor relations, telemedicine, distance learning, technical design reviews, and other collaborative activities.43
Companies are looking for ways to run their business in a more cost efficient manner while also better meeting the growing demands of their customers. By holding business meetings, corporate training classes, and customer support sessions online, software-based group conferencing enables companies to improve productivity and better serve their customers--all at a fraction of the cost of previously available alternatives. Videoconferencing isn't just for CEOs any longer, thanks to falling prices, easier-to-use products, technical standards, a proliferation of new technology, and a growing need among businesses to share information quickly and to collaborate.
Figure 7.11. Conferencing Systems

Room-based Conferencing System Desktop Conferencing System
The purpose of this section is to explore some of the basic conferencing tools used for a multimedia link to the outside world. Included in this discussion are videoconferencing, data conferencing, and video streaming.
Videoconferencing
Videoconferencing is a technology that combines and transmits audio, video, and data streams, to enable rich human interaction and efficient work processes between remote users. Voice communications over the telephone, animated videos, or data file transfers via modem are basic technologies with which we are all familiar. When combined simultaneously in real-time, they provide a very comprehensive and powerful communication experience.
The implementation of videoconferencing on PC platforms consists of a series of processes involving specialized hardware and the PC processor. Audio and video streams are captured respectively by a microphone, a camera, and a video capture card. These streams are encoded (translated from an analog to a digital stream) and compressed to make more efficient use of transmission bandwidth. Then, they are multiplexed with binary data (for instance, a file that will be transferred), and finally transmitted over a single network connection to the other videoconference participant. A similar process occurs on the receiving platform, which decodes and separates the AV streams, so that the reconstituted information can be played back in real-time.
Simultaneous transmission and delivery of audio and video is a minimum functionality requirement for a videoconferencing system. In fact, this feature is the one that has driven most of the videoconferencing deployments so far. Users are able to see and hear colleagues or clients at offsite locations. This way, they can participate in virtual meetings without having to leave their office, thereby saving time and money. Typically, they can also see their own local image, and there are some systems that allow multiple participants to be viewed on the screen at the same time.
Application Conferencing
Application sharing allows you to conference with someone who may not have the same application programs you have. One person launches the application, and it runs simultaneously on all participants' desktops so that everyone can view the application screen simultaneously. All users can input information and control the application using the keyboard and the mouse. Files can be transferred easily and the results of your conference are available to all users immediately. This kind of application is designed to allow participants at multiple sites to view and sometimes control it. Usually, the person who launched the application can lock out other persons from making changes, so the locked-out person sees the application running but cannot control it. Application conferencing is almost never used as a standalone technology, rather it is usually used jointly with one of the other conferencing technologies discussed in this section.
Data Conferencing (Electronic Whiteboard)
Data conferencing is a term used to describe the placement of shared documents or images on an on-screen "shared notebook" or "whiteboard," which allows a document or image to be viewed simultaneously by two or more participants. All participants can then view the document while making annotations on it using the drawing or text capabilities of the specific whiteboard program. Most of the shared whiteboard programs use different colors to indicate whose annotations are whose. Some software includes "snapshot" tools that enable you to capture entire windows or portions of windows and place them on the whiteboard.44
In a data conference, you can type, draw a chart, or paste images, Website addresses, or anything else onto an electronic whiteboard on your computer screen that other users can see simultaneously on their screens, no matter where they are. A chairman or host typically organizes and controls the conference, displaying the initial image or document. Authorized participants join at the appointed time by clicking a button, which allows the whiteboard's contents to be displayed in a browser on their screens. Initially, the host has the floor, controlling the cursor and what's drawn or placed on the whiteboard. But a participant can request control, typically by choosing a command from a menu. When the current participant is finished, the host passes control to the next person, who can then place or annotate something on the whiteboard.
Whiteboards usually have a tool bar for drawing, adding text, highlighting, or otherwise marking what's being viewed. To change an image or document, its owner typically edits the original document and pastes the result on the whiteboard. Most products also have a file transfer feature that allows you to copy a file to one or more users' machines without requesting cursor control and interrupting the conference.
Outside of the whiteboard, participants can type comments in a chat window, directing them to an individual or to the group. When the meeting is over, chat text can be saved in a file and distributed as meeting notes. Typing comments back and forth isn't always expedient for involved conversations among a large group, but it works surprisingly well for most small groups.45
Video Streaming
We tend to think of video communications equipment as interactive, bi-directional, and real-time. However, there is a new, network-centric conferencing paradigm emerging that permits the use of unidirectional or streaming technologies.
Streaming video is a sequence of "moving images" that are sent in compressed form over the Internet or network and displayed by the viewer as they arrive. Streaming media is streaming video with sound. With streaming video or streaming media, a Web user does not have to wait to download a large file before seeing the video or hearing the sound. Instead, the media is sent in a continuous stream and is played as it arrives. The user needs a player, which is a special program that uncompresses and sends video data to the display and audio data to speakers. A player can be either an integral part of a browser or downloaded from the software maker's Website.
Streaming video is usually sent from prerecorded video files, but can be distributed as part of a live broadcast "feed." In a live broadcast, the video signal is converted into a compressed digital signal and transmitted from a special Web server that is able to do multicasting, sending the same file to multiple users at the same time.46
Progress to Date
Until recently, conferencing systems were either room-based or roll-about systems and were too expensive, too complex, and the performance too poor for the technology to gain a hold in many businesses. Companies implementing a videoconferencing system needed to set up special rooms with $100,000 worth of proprietary equipment and a dedicated staff in order to connect video callers in real time. Today, however, advances in desktop and portable computer technologies, compression techniques, falling prices, and the ratification of industry standards have made the PC a viable alternative for software-driven conferencing applications. These conferencing applications enable a business to take advantage of existing IP-based network technologies such as POTS, local area networks, corporate Intranets, and the Internet. Although room-based and roll-about systems are not going to disappear, desktop systems will continue as the principal driver of growth.
Standards
It has taken videoconferencing more than three decades to evolve to the point where a growing number of companies consider it part of their essential communications services. One key development was the adoption of videoconferencing standards that let equipment from different manufacturers work together over ISDN connections (H.320) and IP connections (H.323).
In the recent past there were no standards that would enable conferencing between systems that did not use the same proprietary compression schemes. The published standards adopted by the International Telecommunications Union (ITU) describe in detail, acceptable methods of compression of videoconferencing signals. All compressed signals transmitted that adhere to these standards are capable of being received and decompressed by any other device that adheres to these standards. This allows videoconferencing to be as universal as fax machines. All major manufacturers of videoconferencing equipment presently adhere to these standards providing the ability to connect and successfully videoconference with other manufacturer's equipment.
There are three videoconferencing standards: H.320, H.323, and H.324. H.320 is ISDN-based, H.323 is LAN-based, and H.324, which operates over ordinary telephone lines, is POTS-based. Desktop videoconferencing was given a boost by the approval of the H.323 standard in 1996 and the growing use of IP networking, which allows for videoconferencing over the Internet using the IP's real-time transport protocol (RTP). This standard specifies the coding and decoding of video and audio signals, allowing for different products at each end of the connection to interoperate over the Internet and LANs where bandwidths may vary.47
Figure 7.12 shows the protocols/standards that comprise the "H" series of videoconferencing standards.
H.320 is actually an "umbrella" protocol that is comprised of three protocol groupings, each addressing a different aspect of low bandwidth videoconferencing. The first grouping contains the ITU video compression standards H.261 and H.263 which define the compression algorithms and video resolutions used in videoconferencing. The second grouping focuses on the diverse audio needs of videoconferencing applications and includes the audio codec standards G.711, G.722, and G.728. The third and last grouping deals with the transmission and control issues surrounding video conferencing (i.e., frame structure, format, and multipoint control) and contains the specifications H.221 and H.231.
Figure 7.12. "H" Series of Videoconferencing Standards
Source: Videoconferencing Solutions, Inc.
The H.320 standard series addresses videoconferencing over circuit switched networks, such as Integrated Services Digital Network (ISDN) or switched 5G. H.320 includes the H.261 video compression algorithm, and three audio codecs to address a range of applications.48
H.323 establishes standards for videoconferencing and multimedia communications over local area networks (LANs). It extends videoconferencing to packet-switched networks like Ethernet and token ring, which do not guarantee a quality of service (QoS). H.323 is based on the real-time protocol (RTP/RTCP) from the IETF, so it can also be applied to video on the Internet.
The H.324 standards address high quality video and audio compression for high-speed modem connections over the POTS network. H.324 is the first standard to allow for video, data, and voice to be transmitted over a single analog phone line. It also specifies interoperability over a single line. As a result, the "videophones" being introduced by a number of companies will be able to connect to, and talk to, one another. Each of these standards applies to multipoint and point-to-point applications.49
The drawback of H.323 is video quality. Although bandwidth over LANs can be high, video traffic competes with LAN data traffic. Thus, the availability of bandwidth at any given time depends on LAN usage. If bandwidth availability drops, transmission speeds slow and video quality suffers. Video traffic and LAN data traffic can be segregated, but special equipment and software are required. Moreover, if one of the videoconferencing sites is not on the LAN, the data must be converted from a packet to a switched format, a process that can result in degradation and instability. However, LAN-based systems are relatively inexpensive, with prices running as low at $500.
The H.323 standard has created potential opportunities for Internet service providers to offer videoconferencing. ISPs are not likely to compete for point-to-point conferences but can offer an advantage when conferences involve a large number of participants. Bandwidth, however, remains a problem. An ISP may be in a position to guarantee bandwidth to their customers, but once the conference leaves the ISP network and enters the Internet, bandwidth cannot be guaranteed. Thus, ISPs are not in a position to offer the quality that is available through other solutions.
The ISDN-based H.320 standard tends to be more reliable because bandwidth is assured. An ISDN BRI line can transmit data at 128 Kb/s, which is generally fast enough to deliver high-quality video, if the carrier supports it. In many areas, however, the maximum rate is 112 Kb/s. Desktop ISDN systems, which cost up to $5,000 in 1993, are now available at less than $1,500. ISDN lines to the desktop, of course, are also required. If the entire LAN is to have ISDN-based videoconferencing capabilities, this option can become expensive.
The POTS-based H.324 standard is limited by modem speeds that are, at best, 56 Kb/s and more commonly 28.8 Kb/s. At these speeds video quality is low. Consequently, H.324 is not likely to be a significant component of videoconferencing for business purposes.
Table 7.2. H.320 Data Rate: Application Suitability
Source: FVC.COM50
Videoconferencing is not only video but audio as well. The H.320 standard has three audio formats--G.711, which transmits at 64 Kb/s, G.722 at 56 Kb/s, and G.728 at 16 Kb/s. Since the three standards allocate different bandwidths to audio, they are incompatible. There are also differences in the dynamic frequency range. G.728 and G.711 each deliver a dynamic frequency range of 300 to 3,400 Hz, while G.722 delivers a dynamic frequency of 50 to 7,000 Hz.51
T.120 provides real-time data conferencing standards that allow people at multiple locations to conduct a voice conference call and create and manipulate still images such as documents, spreadsheets, color graphics, and photographs.
Falling Prices
The market is being fed by a new supply of less-expensive equipment options. Prices for end units--the devices that are used to set up a conference and display the video call--have fallen from roughly $60,000 per unit to as little as $4,000 to $6,000 per unit, depending on how much bandwidth they use and what features they offer.
Much of the reduction in prices has come from the shift to set-top end units and the plummeting cost of PCs, which form the core of some standalone videoconferencing units. Many systems can turn a VCR-ready conference-room television into a videoconferencing station. Other videoconferencing systems, such as Intel's ProShare Video System, can turn a desktop PC into a videoconferencing unit by adding a camera, speakers, and a card for the PC.52
When streaming video products were first introduced, they didn't justify the exorbitant cost. They offered no security, their management interfaces were virtually non-existent, and the codecs that the vendors licensed were not intended for use over a TCP/IP network. But streaming applications have reaped the benefits of major technological improvements since then, bringing developers closer to their ultimate goal of achieving 30 frames per second (fps) of live streaming video.53
Compression Techniques
Videoconferencing transmission is challenging because it is a steady stream of information. This leads to the issue of frame rate and the definition of full-motion video. Frame rate is the number of pictures that can be displayed on a monitor in a second, and full-motion video is 30 frames per second (fps) . Most video monitors consist of at least a 1024 × 768 pixel display. While many videoconferencing packages do not utilize the entire screen, a picture of 300 × 200 pixels (roughly one-quarter of the screen) would use 60,000 pixels or 60 kilobytes for each frame. At this frame rate, a video picture of this size would be sent at the rate of 1.8 Mb/s. To demonstrate the difficulty of this transmission consider that the one-time transfer of a 1 MB file over a standard telephone line would take 17 minutes. This means that videoconferencing must be able to send roughly 30 times that level of information a second to achieve full motion video.
To accomplish full motion video one of two things needs to happen:
• The lines used for the transmission must be capable of handling a high bandwidth.
• The data must be compressed to travel along existing lines.
Data compression is the process of reducing the size of the information to be transmitted. There are several ways data is compressed. It can be compressed through a lossless compression scheme or a lossy compression technique. A lossless compression means that 100% of the data is received and available after de-compression. Lossy compression does not retain 100% of the data, which means the quality of the final picture is reduced. CODECS (Compression and DECompresion componentS) refers to the specifications used by the software and hardware to package and unpackage data. The CODECS of various systems help determine the amount and method of data packaging. Historically, videoconferencing systems required costly investment in equipment to perform data compression. Our perception of the quality of motion video is strongly related to the frame rate, and our perceptions are based on TV signals. Below is a breakdown of these ratios with the quality percentage relating to the degree of loss after de-compression:
Source: Ted Pelecky
Compression techniques use algorithms to reduce the file size of an image. Extensive video compression results in long calculations on the part of the hardware involved, which can be a time-consuming process. There are many compression algorithms, along with the ITU-T H.261 standard, which involves a lot of computation; therefore, it requires special purpose hardware. The videoconference industry challenge has been to both overcome bandwidth limitations and improve data compression technologies. The growth of videoconferencing will depend on providing a high-quality product for an affordable price. The industry has developed many methods to squeeze the most information possible out of current technologies. The future of videoconferencing will be determined by the techniques used to break the barriers to delivering high-quality/low-cost videoconferencing products.54
Network Transport
A key issue for videoconferencing is interoperability. Early videoconferencing systems used proprietary technology that was not interoperable with competing systems. Videoconferencing, therefore, was largely limited to intra-company meetings, but even this application was impeded by a lack of common standards that curtailed the utility of the technology.
Videoconferencing has historically used circuit-switched networks where data is transmitted between two points by setting up a physical linkor circuitbetween them. The usual example of a circuit-switched network is the plain old telephone system (POTS) network. When you dial a phone number, the phone company's switching equipment sets up a direct circuit between your telephone and the destination. The chief advantage of circuit switching is that the flow of data (for example, your voice) is not subject to delays introduced by the network, and the recipient receives data exactly as it was sent. The big disadvantage is that much of the connection's available bandwidth may be wasted due to the bursty nature of data traffic, which will rarely saturate the link's capacity.
ISDN, a circuit-switched network, is probably the best known transport for videoconferencing to-date. The H.320 standard, which defines the implementation of videoconferencing over ISDN, has been in place for a decade now. ISDN allows the transport of videoconferencing at a range of quality levels, from low quality, suited to casual personal use, to high quality that is suited to business and distance learning applications.
ISDN is able to provide high quality videoconferencing primarily because its synchronous nature enables video transport with very low delay and delay variation. The transport characteristics provide the critical sensitivity to delay demanded by videoconferencing traffic and ensure the timely delivery of video information. It is able to implement videoconferencing at a variety of transmission rates, from 64 Kb/s up to 2 Mb/s. At 128 Kb/s, videoconferencing on ISDN is of only marginal quality and cannot really be considered suitable for most business uses. At speeds of 384 Kb/s and beyond, which can be considered the baseline of business quality videoconferencing, ISDN provides very high quality transmission of videoconferencing.
While ISDN can provide the quality required for useful videoconferencing, the implementation of ISDN at speeds of 384 Kb/s and above is a costly and complex undertaking. Three 128 Kb/s basic rate ISDN (BRI) interfaces must be pulled to each and every videoconferencing capable device. (See Figure 7.13.) These BRI lines must then be bonded together to form a single communications channel using a device called an IMUX. Additionally, using 384 Kb/s ISDN speeds typically means having to purchase a V.35 card and RS-366 dialing card for each videoconferencing station.
Unfortunately, this additional cost and complexity associated with deploying videoconferencing at 384 Kb/s on ISDN often results in videoconferencing being implemented at 128 Kb/s instead. The result of this is videoconferencing at a lower cost, but at a quality that simply does not meet the needs of many applications.55
IP-Based Videoconferencing
ISDN desktops are still the main staple of the desktop videoconferencing marketplace. These products have their genesis in the H.320 group video systems--a mature and well-understood technology. The ISDN products have good performance characteristics, partly because most products compress the video in hardware and partly because the bandwidth and quality of service are inherent to the circuit-switched network.
In contrast to ISDN, IP videoconferencing systems are just beginning to be deployed in small numbers. Most people are "experimenting" with the technology. Their wide-scale deployment is still a way off because many corporate intranets and the public Internet cannot adequately handle real-time motion video and deliver the quality of service expected for business applications.
Most people equate poor video quality with IP desktops. In this regard, IP products have gotten a bad rap. It's true that some of the more popular (low-cost) products do have mediocre-quality video; however, the quality is not necessarily related to the fact that these products are IP-based, but rather to the type of compression used in the desktop. Here's why.
Compression can be performed in either hardware or software. Desktops using hardware compression have an add-in board, which plugs into the computer's card slot. The compression processes are executed on this board, thereby freeing the main CPU to perform its other tasks. Hardware compression produces good-quality video because the processing is independent of the CPU, but the additional hardware that's required increases product costs.
Desktops using software compression use the resources of the main CPU to compress the video; however, the CPU resources are also shared with other processing tasks. The compression (which uses many machine cycles) and other processing often taxes the CPU to its limits, resulting in mediocre-quality video. Desktops using software compression are inexpensive because these products do not require extra hardware.
Most ISDN desktops use hardware compression, which explains its higher-quality video and higher cost. On the other hand, IP desktops are available with either hardware or software compression engines. IP products using hardware compression are capable of producing the same high-quality video as their ISDN counterparts, if (and that's a big if) the network they're operating on has adequate bandwidth and latency characteristics. Most of the more popular, low-cost IP products use software compression, which explains the low-quality video.
Videoconferencing and Packet Networks
The biggest problem with IP conferencing is the network. Packet networks originally were designed to reliably communicate data--not video. As a matter of fact, video and packet networks are fundamentally incompatible. Without suitable protocols, packet networks cannot adequately transport real-time streamed video/audio. Packet jitter (fluctuations in packet delivery time) and latency (delays in packet delivery) will degrade its performance. Furthermore, the continuous bit streams coming from a desktop can congest the network and reduce its performance for both data and video users.
The successful implementation of real-time videoconferencing over packet networks requires:
• Developing protocols to reduce the effects of packet jitter and latency.
• Placing controls on the number of videoconferencing units accessing the network.
• Having faster networks to accommodate the large amounts of data generated by the desktops.
The first two are addressed in the ITU-T's H.323 suite of recommendations. The third requires upgrades to corporate intranets and the Internet.
In one sense, IP desktops have arrived without suitable networks to transport the information. Limited bandwidth, latency, and no guaranteed quality of service are the principal obstacles to IP conferencing. H.323 mitigates some but not all of these deficiencies.
H.323 borrows several protocols developed by the Internet Engineering Task Force (IETF) to help with jitter and latency issues inherent in packet networks. These protocols include the user datagram protocol (UDP) and the real-time protocol (RTP). UDP/RTP essentially provides "best-effort" delivery of video/audio packets without retransmission and acknowledgment. This type of service is defined as "unreliable" because there is no guaranteed end-to-end delivery/integrity of packets. This unreliable service works for videoconferencing because it reduces latency and packet jitter at the expense of an occasional dropped video frame. But this is in contrast to the familiar transmission control protocol (TCP) used in IP networks, which does provide reliable end-to-end packet delivery, preserving data integrity at the expense of higher latency.
Latency can also be improved by using the IETF's Resource Reservation Protocol (RSVP), which allows a subscriber to request a specific bandwidth for a conference session. RSVP is not part of the H.323 standard; however, a videoconferencing product having this capability, together with RSVP-enabled routers, will improve performance.
IP Desktops--The Bandwidth Hog
To the network, IP desktops look like bandwidth hogs. A 128 Kb/s videoconference consumes 256 Kb/s of bandwidth (without overhead): 128 Kb/s to transmit and 128 Kb/s to receive. It doesn't take too many desktops on a LAN to overload a 10-Mb/s Ethernet segment, creating annoyances for all users and nightmares for the network administrator. Some network administrators address this problem by outright prohibiting real-time video over their networks. H.323 addresses the problem by controlling access using the optional gatekeeper function specified in the standard. Here's how it works.
The network administrator reserves bandwidth for conferencing by setting parameters in the gatekeeper. All videoconferencing terminals must request permission from the gatekeeper to access the network for videoconferencing. If bandwidth is available, access is granted. If not, access is denied. This process is referred to as "call control." While call control helps the jitter/latency problems and prevents the network from being congested, it does so at the expense of denying access to the videoconferencing users. Improved access requires faster networks, which typically are not yet in place at most corporations.
Besides call control, the gatekeeper also performs another important service by translating aliases assigned to videoconferencing terminals to IP addresses. This allows desktop users to place calls by entering terminal names instead of IP addresses.
Although the gatekeeper is optional under H.323, it's required from a practical standpoint for all except the smallest of networks.
Upgrading Corporate Networks
Some corporations already have upgraded their corporate networks, while many are in the process of upgrading. Two of the more popular upgrades are switched Ethernet and 100 Mb/s Ethernet. It's interesting to note that the driver for these upgrades is not videoconferencing but, rather, the need to use multimedia as well as other data-intensive applications in today's business environment. Desktop conferencing is just another application that will ride the coattails of these network upgrades.
How fast these upgrades occur is the key question. If a corporation already has the required network infrastructure, then it makes sense to begin deploying IP desktops. If not, then the administrator must consider the number of IP desktops to be deployed and evaluate their impact on the existing network.
With faster networks and appropriate protocols, IP desktops can communicate successfully over corporate Intranets; however, communicating over the public Internet presents a problem. With the Internet's inherent latency and restricted bandwidth, it's sheer folly to think that it can be used for real-time videoconferencing at a quality level acceptable for business applications. Enhancements to the public Internet will be required in order to communicate real-time, business-quality video, and these enhancements are a ways off.
Some possible options for communicating outside the local area network include frame relay and ATM. However, frame relay can introduce latency under load, and ATM is not yet universally available. Both of these services increase communication costs. Another option is to use the circuit-switched wide area network accessed through a gateway; however, this also increases communication costs and defeats the purpose of going IP in the first place.
A final option is to subscribe to a private Internet service. Private IP services offer high-speed access and have high-speed backbones to minimize latency, and most providers usually guarantee latency. Private IP networks also offer value-added services such as IP-to-ISDN gateway, directory, and private-to-public Internet bridging--all at a cost.
Communicating with H.320 Legacy Systems
ISDN desktops will be around for the foreseeable future and ISDN group systems even longer. There often may be a need for an IP desktop to communicate with an ISDN desktop or group video product. IP-to-ISDN conferencing is accomplished using the gateway specified under H.323.
Gateway products are just beginning to appear in the marketplace. While critical functions such as conversions between transmission formats, communications procedures, call setup, etc., are specified under H.323, other functions and services are optional and left to the manufacturer. These include the number of IP desktops that can access the gateway, the number of ISDN connections allowed, the number of simultaneous point-to-point conferences allowed, and transcoding capabilities. The functions/services offered in a manufacturer's product must be evaluated carefully to make sure they satisfy user requirements.
Communicating with H.320 group systems also places a special requirement on the quality of the video coming from the H.323 desktop. Group systems typically have large monitors, and any aberrations in the video will be exacerbated when displayed on the large screens. This almost always requires that the H.323 desktop use hardware compression to ensure the integrity of the transmitted image. Desktops using software compression simply do not cut it when communicating with a group system.
IP Multipoint
Multipoint in the IP world can be centralized, decentralized, or hybrid. Centralized multipoint requires having an H.323-compliant multipoint control unit (MCU) to mix audio, switch video, and distribute data. This is analogous to the MCUs used in the H.320 world. The principal advantage to using an H.323 MCU is that it does not require any additions or modifications to the existing LAN infrastructure. However, H.323 MCUs (like their H.320 counterparts) are expensive and do not make efficient use of network bandwidth.
Decentralized multipoint uses IP multicast technology. There is no traditional MCU in the network; however, one terminal must be able to centrally coordinate the process. A special multicast header addresses a group of terminals in the multipoint session, and each terminal processes the appropriate audio, video, and data streams in software. (In effect, the multipoint functions are distributed.) Decentralized multipoint has two significant advantages over centralized. First, it's inexpensive because the multipoint functions are performed in software. Second, IP multicasting makes efficient use of network bandwidth resources. The main disadvantages are that the routers in the network must be enabled to process multicast messages and that the desktop terminals must have enough processing power to perform the additional multipoint tasks (usually not a problem with today's microprocessors). The ability to use decentralized multipoint is a distinct plus for IP conferencing.
Hybrid (as implied by the name) is a mixture of centralized and decentralized multipoint. It's used when all terminals in large networks do not have enough processing power for decentralized operation or when all routers are not multicast enabled.
Summing It All Up
The videoconferencing market is moving on parallel tracks. The ISDN-based standard has the advantage of reliability but the disadvantage of limited access. The IP-based standard has the advantage of almost universal connectivity but does not match the quality of the ISDN systems. These tracks are not mutually exclusive. Depending on the nature of the conference, ISDN may be appropriate in some instances and IP in others. Companies are likely to keep their options open, at least over the next few years, until the efficacy of the H.323 standard can be demonstrated.
It's inevitable that desktops will migrate to IP; however, the road to IP will be evolutionary, not revolutionary. IP conferencing provides the opportunities for low-cost, point-to-point, and also multipoint conferencing (when using multicast). However, the network infrastructure will have to be upgraded before we see any meaningful movement toward IP.
Most corporations already have a sizable investment in their existing networks, and many either have upgraded or are in the process of upgrading their networks. So, the corporate Intranet can support IP videoconferencing (or soon will be able to), but this isn't true for the public Internet.
The principal obstacle to IP conferencing is the WAN. The public Internet does not provide the quality of service required for business-quality video. This is in contrast to ISDN, where the public network does provide a guaranteed quality of service. There are other options for IP videoconferencing over the WAN; but these options either are not universally available, have performance limitations, or add to the operating costs.
So, is it ISDN or IP? ISDN desktops are a proven technology and will be around for a while. These products are best utilized when deployed in small numbers and used to communicate with other ISDN (group or desktop) products over the WAN.
On the other hand, IP products are ideal for collaborative communications when used in a campus environment over high-speed LANs or in an environment where existing IP networks are already linked by a high-speed enterprise WAN. It's just another application riding on the IP network.
It's safe to say that IP and ISDN desktops will coexist for the foreseeable future. The two networks will interoperate thanks to the H.323 gateway--the "glue" tying the two together.56
Major Players/Market Leaders
Videoconferencing Products57
Multipoint conferencing units:
• Polycom's ViewStation MP and WebStation.
• VTEL MCS/IP conference server.
• VideoServer's Encounter NetServer.
• White Pine Software's MeetingPoint.
• Madge Networks' LAN Video Gateway.
• VideoServer's Encounter NetGate.
• White Pine Software's CU-SeeMe Pro desktop videoconferencing client.
New Technology
IP Videoconferencing
Bigger changes are on the way in the next 12 to 18 months, thanks to the rise of the Internet and IP-based networking. While ISDN connections are still the standard way companies handle videoconferencing, IP systems are gaining in popularity. Many systems being designed and developed today are capable of handling IP and ISDN traffic.
As data and voice networks converge, it's likely that videoconferencing will become just one more set of bits on the network. The result should be even more affordable videoconferencing access. IP video, like IP voice, is cheaper to deliver and more flexible than ISDN.
Conferencing vendors are also beginning to build streaming video capabilities into their products. Once companies are set up to handle the bandwidth requirements of a converged network, vendors say IP video alone shouldn't pose a problem.
VTEL Corporation, for example, has built its product line on the assumption that IT managers will plug its products into an IP data network. The videoconferencing vendor has built a multipoint conferencing system, gateway, and network-management software designed to manage IP videoconferencing end units. The conferencing system and gateway are PC-based, run on Windows NT servers, and plug into 10-Mb/s or 100-Mb/s Ethernet networks.
Videoconferencing becomes easier once it is just another application on the LAN, vendors say. "Once you solve the bandwidth problem--by re-architecting your LAN if necessary--video quality is actually better over IP," says Richard Moulds, VP of marketing for VideoServer, Inc. in Burlington, Massachusetts. "Once someone has upgraded their network to handle IP conferencing, they tend to conference at 700 Kb/s or even 1 Mb/s, whereas it's typically only 100 Kb/s over ISDN."
Eventually, as bandwidth levels go up and IP becomes standard, videoconferencing capabilities should become a standard part of LAN equipment. That should push prices down even further, researchers predict.
Over time, both voice and video capabilities will be embedded routinely on enterprise switches, says Emmy Johnson, senior analyst in the networking services area of Cahners In-Stat Group. "You would have one box instead of all of these different boxes," Johnson says. "That will probably be cheaper than buying a bunch of different pieces."58
H.323
Work has recently completed on the H.323 videoconferencing standard. It is designed to facilitate videoconferencing on packet-based networks such as Ethernet, Token Ring, and FDDI, using a TCP/IP transport. H.323 is unlike the H.320 and H.321 standards, which were designed to take advantage of the inherent QoS capabilities of ISDN and ATM, for high quality videoconferencing. In practice H.323 is transport independent allowing implementation on top of any network transport architecture including ATM.
Standards-based videoconferencing on IP/Ethernet networks is thus becoming a reality. The key difference in the way that videoconferencing is implemented in the Ethernet arena is that Ethernet does not have an underlying QoS architecture on which to base video transport. Even switched Ethernet infrastructures are quite unpredictable in nature, especially on network trunk links and through routed backbones.
The result of this network behavior on videoconferencing is increased delay and jitter, resulting in greatly decreased quality. Videoconferencing on Ethernet using today's technology could not be classed as business quality, as it does not have the quality required to replace travel. Video on Ethernet infrastructures also has the unfortunate side effect of permitting interaction between the data and the video traffic. The bandwidth requirements of the video traffic slow down the data traffic on the network, the best effort nature of the data impacts the quality of the video transmission.
Naturally there is a range of quality outcomes that are acceptable in the realm of videoconferencing. What is important is that the quality is appropriate for a particular purpose.
For example, applications such as ad-hoc discussions between individuals collaborating on a project could well be established over the Ethernet connections from personal desktop videoconferencing equipment. However a senior review meeting for the same project between the team-leaders and senior management would need to be conducted on a network that supports business quality video and multi-point videoconferencing. This application demands ATM or ISDN.
Ethernet's inherent lack of QoS has prompted the designers of this network transport system to go back to the design board and attempt to retro-fit Ethernet with QoS capabilities. This new protocol, called the Resource Reservation Protocol (RSVP), is a signaling system designed to enable the end points of a network transaction to reserve network bandwidth for particular communication streams. RSVP is likely to become a widely accepted method of enabling existing network infrastructures to deliver some QoS-like capabilities. However at this time, RSVP is untried, especially in the large corporate environments where it would be most appropriate. In any case, RSVP cannot solve the two fundamental QoS issues of packet-based networks:
(1) RSVP operates in the Ethernet environment and must deal with variable length frames. This means that it is probable that small latency-sensitive packets carrying videoconferencing could easily be stuck in a buffer behind much larger data packets. This is the case for 10Base-T, 100Base-X, and Gigabit Ethernet.
(2) RSVP is a simple signaling system, where every hop-by-hop link must be negotiated separately. There really is no end-to-end guarantee of service level. Contrast this to ATM which does set up an end-to-end connection with a specific QoS class that commences at call set-up and ends at call tear-down.59
The Internet2 is a revolutionary new Internet designed by the academic world for the research community that is 100 to 1,000 times faster than the current Internet. The bandwidth of this network is much larger than the current Internet; therefore, it can carry much more information and different types of information than the current Internet. This project continues the collaboration between universities, industry, and the federal government that was so effective in developing the current Internet. Over 130 universities have joined forces as the University Corporation for Advanced Internet Development (UCAID) to develop advanced applications for this high-speed, broadband Internet. According to the Internet2 Website "About Internet2," the universities have three major goals:
• First and most importantly, creating and sustaining a leading edge network capability for the national research community.
• Second, directing network development efforts to enable a new generation of applications to fully exploit the capabilities of broadband networks.
• Third, working to rapidly transfer new network services and applications to all levels of educational use and to the broader Internet community, both nationally and internationally.
The universities are joined using two major, interoperable backbone network systems, vBNS (very-high-performance Backbone Network Service) and Abilene. Both of these networks are made of fiber optics and connected with the latest switching devices; therefore, they are much faster and can carry a lot more information back and forth at one time than the current Internet. Government programs also support both. The Next Generation Internet (NGI) is the most prominent of those programs. Both of these backbone networks fall under the umbrella of the National Science Foundation (NSF), which awards high performance connections (HPC) to deserving universities. When granted HPC, a university is provided access to an approved High Performance Network Service Provider (HPNSP). The National Science Foundation had already awarded access to vBNS to over 70 Internet2 universities. As of December 1998, these universities have the option of connecting to vBNS or Abilene because Abilene was granted conditional HPNSP status. Abilene is even more advanced than vBNS and will also be used to support Internet2.
One of UCAID's goals for 1998 was for all participating universities to have a stable vBNS connection to Internet2 by the end of 1998. However, the Abilene backbone network system plans to connect at least 60 Internet2 universities by the end of 1999. As of December 1998, Abilene was not actually supporting any universities. This backbone network is faster and newer than the pre-existing vBNS. On January 20, 1999, the Abilene Project achieved coast-to-coast connectivity in the United States. When fully functional, Abilene claims it will operate at speeds approximately 85,000 times faster than a typical computer modem. As for a completion date for Internet2, it will be a constantly changing system. The Internet2 may very well be a project that is never "finished" because there will always be researchers finding new and better ways to develop it.
Although Internet2 was not designed for direct public or industrial use, we should all benefit from the research supporting this huge program. One of the chief goals of this program is to rapidly transfer new network services and applications to all levels of educational use and to the broader Internet community, both nationally and internationally. As with our current Internet, the business community will integrate the discoveries of the academic community into useful applications for themselves and consumers. The United State's profit-driven economy will insure that new technology is used in a way that supports commerce and makes it easier.60
Source: Sun World, ©1998 MCI Telecommunications Corporation61
Conferencing Trends in 199962
Streaming video with quality-of-service (QoS), multimedia switching and, finally, the H.323 videoconferencing technology over Internet Protocol (IP) were just some of the interesting trends demonstrated at January's ComNet '99 in Washington, DC.
Web-Based Scheduling
Sprint will offer a multi-tiered "video, Web-based, conferencing reservation service," enabling Internet users to manage their own conference schedules in the carrier's large array of public and private videoconferencing rooms. "We have clients with as many as 50 conferencing rooms, and they'd have secure [Web] access to see [who is conferencing] in their own private space," says Amy Holmes, group manager of conferencing services at Sprint.
The Sprint service will offer three levels of scheduling access: View Only, User, and Administrator. "View only is a browse capability," Holmes explains. "Potential users can see what's available in public rooms throughout the country listed at the Sprint Web site. Authorized users, on the other hand, can book and update reservations, and create their own profiles and conferencing reports."
At the highest level of access, "administrators can make or change reservations, override existing reservations, and have the capability to control others' access," Holmes says. Administrators and users also can register with no subscription fee. ("Obviously, we're trying to encourage more and more conferencing reservations," she notes.)
Companies using public conferencing rooms can access the Web and reserve space using secure access with firewall control, according to Holmes. "These are real-time reservations, where you can reserve hardware for the back room, bridging--whatever is required." Sprint's Web-based application also will perform a facilities check to determine room availability. "Basically," Holmes says, "we're extending out to the customer what used to be [the authority] of a reservation team. Large users and the government want this. In the future, we'll see such extended features as trouble management and trouble reporting."
Empowering the Users
The Sprint service may be indicative of a new trend in "user empowerment" which leverages the Web as a control point.
"The really exciting news for 1999 is that customers will get products that work like toasters and telephones, and not like personal computers and painful cures," claims Elliot Gold, president of TeleSpan Publishing Corporation. "In the area of audio, I expect to see an avalanche of easy-to-use conference call options, which allows users to set up their own calls, big and small, hold `em, and hang up on `em when done."
In data conferencing, "we're already seeing a full menu of offerings being dished up which allow the user to sit back, as they do in an ordinary meeting now, and receive graphical information without any more effort than squeezing a mouse," Gold says.
In the video area, "the push is clearly toward the appliance: sit down, pick up the instructions, which read, `click, click, click, dial and go,'" Gold says. "We'll see everything shipped with both videoconference standards--H.320 and H.323--with dual-access potential for when and if IP delivers the quality of service we need for audio and video."
Bill Erysian, president of audioconferencing vendor Soundgear, agrees in principle: "What I've seen over the last five years in portable audioconferencing is a reduction in pricing and a more sophisticated DSP [digital signal processing]-based technology," he says. "We see more powerful units with better sound clarity, and more flexibility in terms of features." Ordinary squawk boxes that used to ruin the quality of audioconference bridge services are being replaced by software-intensive phones with a variety of acoustic features. Software algorithms can now "recognize" differences in pitch, frequency, and volume of human voices; adjust to noisy environments; and deliver the communications quality of full-duplex handsets without echo or cutoff, Erysian says.
QoS: The Great Unknown
The ComNet Expo did not solely reflect stark simplicity. Cabletron Systems demonstrated a streaming video QoS solution designed for corporate enterprise frame relay networks linking remote offices. The application involves a centralized video server and a smart switch router that includes a four-port wide area network (WAN) card. This establishes a WAN-to-LAN (local area network) connection via a point-to-point protocol (PPP) session. The smart switch router enables traffic and bandwidth to be prioritized to enable QoS guarantees.
"You can do streaming video using frame relay and still define QoS," says Ken Pappas, product line manager at Cabletron Systems.
With selective bandwidth allocation, the picture quality is extremely high--especially adaptable to corporate training applications. "This is not an Internet solution," Pappas says. With time-sensitive delays and problems with QoS, "that's why a company requiring video over its network has to look at end-to-end quality, including devices on the network."
QoS is the great unknown as far as IP is concerned. "The thing holding back adoption of IP videoconferencing today--specifically, devices implementing the H.323 standard--is that IP networks typically don't guarantee QoS end-to-end," says Mike Steigerwald, vice president and general manager of VTEL's global services. Asynchronous transfer mode (ATM) networks, such as those in large public settings or in government applications, "can provide that today, but packet switched technology can't, and that's why most conferencing systems still run off H.320, ISDN, and circuit-switched infrastructure."
The reality of H.323 not quite being there was in evidence at ComNet'99. Polycom showed the $12,000 version of the ViewStation MP, a multipoint conferencing unit using H.320 circuit-switched technology and a fully integrated multipoint control unit (MCU). The system uses bandwidth from four ISDN lines that can link as many corporate sites in an interactive conference with variable bandwidth options.
Although Polycom is touting its unit as "H.323-ready" but not compliant, with software upgrades designed for IP networks expected for release in June, the company is notably cautious about IP quality issues. "We offer continuous presence for multi-site conferences with the H.320 standard," says Kim Kasee, vice president of marketing at Polycom. "Before the introduction of the ViewStation MP, you'd have a videoconferencing bridge that would have cost up to $100,000 or you'd use a bridging service from a carrier [for a multi-site conference]. Now, you have a multipoint conferencing unit integrated into the system at a much lower cost."
The MCU may, in fact, be six times less costly than standalone bridges, Polycom claims. And with as much as 512 Kb/s for a point-to-point call (down to 128 Kb/s for four-site videoconferencing), along with a dual-monitor configuration enabling the ViewStation MP site to "see" each remote site full-screen during a conference, the product fulfills the function of much more expensive corporation solutions. Polycom does not seem overly anxious to rush into the IP space at the expense of quality controls.
The Changing Infrastructure
Infrastructure and access issues for high-bandwidth conferencing may be changing. At ComNet, ViaGate Technologies and VBrick Systems demonstrated live, two-way videoconferencing over very high-speed digital subscriber line (VDSL) technology. Using standard video cameras and monitors, ViaGate demonstrated the use of its 3000/4000 Multimedia Access Switch, which can handle full-motion, MPEG-quality video delivered over ATM to copper wire. The ViaJet is a VDSL modem piping 27 Mb/s downstream over conventional copper wire at distances of 3,000 feet.
VBricks, by contrast, are described as self-contained "video network appliances" that provide two-way or one way MPEG video wherever a network reaches without the need for additional PC adjunct components. Multi-services switching allows for multi-channel data, voice, and video applications, supporting digital cable TV and constant bit rate (CBR) for intensive multimedia. ViaGate claims its switch provides a robust platform for such subscription-based services as video on demand, telemedicine, videoconferencing, distance learning, electronic publishing, Internet/intranet access, and electronic commerce.
Some conferencing companies believe that rapid development of a "premium Internet," or Internet2, will facilitate mass consumer acceptance of H.323 and IP conferencing solutions. "Clearly, the equipment has to go to H.323," claims Paul Weismantel, product manager for NEC's Corporate Networks Group. "The real problem with H.320 and ISDN is that it's difficult to get connectivity ubiquitously, whether for desktops, rooms, or large and small businesses. But as ... Internet II is defined, allowing for video to be deployed rapidly, this could open up IP conferencing very quickly." Weismantel argues that "IP offers the opportunity for lower entry price and, one would hope, an improvement in performance." Performance could be contingent on development of dual-mode systems or intelligent gatekeepers and/or servers that can manage bandwidth and allocate video sites selectively. "The basic premise is that once you've cracked an IP desktop delivery system [for conferencing] and offered it as a computer application, you have a much broader marketplace to play in," Weismantel says. "But the perceived added value for multimedia is still rather low, so that demands for implementation must basically be effortless.
"Products like Microsoft's NetMeeting aren't good enough--most don't work past firewalls; therefore, it's still a local application that no one uses," Weismantel adds.
H.323, however, is gaining ground. Conferencing systems in the State of South Dakota use it successfully under carefully controlled WAN/LAN network designs that lay out strict minimum bandwidth requirements. Companies like VTEL have developed multilink bridges that are H.323-capable with gatekeeper products to manage bandwidth.
Another vendor, White Pine Software, says H.323 is poised to grow dramatically. "What we're seeing is that the multipoint market is already growing up with the introduction of H.323," says Peg Landry, director of marketing at White Pine. "Companies have thus far made limited investments in point-to-point ISDN conferencing. But with the advent of such tools as Intel's TeamStation, which is being expanded to enable multiple conference rooms and desktops to conduct conferences [over IP], we'll see significant growth."
Landry claims that White Pine's CUSeeMe client version, which is not fully H.323 compatible, already has three million users. Server products, such as White Pine's Meeting Point designed for WindowsNT servers, will allow H.323 users to connect in a virtual conference on an IP network with many QoS metrics in place.
"A lot of the fear about H.323 has gone down," Landry says, noting that a full-fledged H.323 version of CUSeeMe would be available by the end of first quarter. "Quality can be built into a server [managing a virtual conference], and with such techniques as bandwidth `pruning' and latency detection and correction, we can get performance that will be business-quality--roughly 15 to 17 frames per second. Now, the biggest challenge will be educating consumers as to the possibilities of IP conferencing."
One Vendor's View of the Future: What Will Drive the H.323 Market?63
The technologically astute will be suspicious of all this enthusiasm over a new, as yet-unproved standard. What will propel H.323 products where earlier products did not? Put simply, it is the convergence of many factors. We will examine some of these forces, and sources of uncertainty, from two perspectives:
(1) The information services/telecommunication professional.
The IS/Telecom Professional
Video communications and conferencing technology developers are climbing on the H.323 bandwagon because they believe that millions of mainstream users worldwide will choose to use IP-based conferencing tools as part of their complement of productivity applications.
Meanwhile, the IS telecom professional is concerned about:
Less than 30% of today's business computers are capable of supporting H.323 videoconferencing (P166 and above installed base). Though many of today's corporate PCs will not be sufficiently powerful to accomplish video compression and simultaneous decompression in real-time, the next generation of desktop computers will come bundled with low-end H.323 capabilities. In fact, most users by the year 1999 will have H.323 in their baseline business computing platforms by virtue of Microsoft's distribution of the protocol stack in their Windows Operating System.
There are few network managers prepared to support video reliably on their existing local area infrastructure. However, improvements to networks "in terms of capacity and management" are coming. We see specific change in the following areas:
• Increased replacement of Category 3 with Category 5 wiring; this will initially be used for backbone expansion and will eventually support 100BaseT to the desk.
• Increased use of Fast Ethernet to the desktop and Gigabit Ethernet or ATM in the backbone.
• Increased replacement of slow routers with faster devices (e.g., switches) permitting up to 10 MB per desktop in most circumstances.
Network managers face a similar challenge on the wide-area side. Bandwidth is expensive and must be used prudently. Moreover, most router- and packet-based WAN technologies lack the QoS mechanisms required to transport real-time, interactive data sessions. VTEL sees change in the following areas:
• Increased acceptance and implementation of Real Time Protocol (RTP) and Reservation Protocol (RSVP) in network components.
• Increased deployment of WAN technologies capable of carrying multiple media types (e.g. ATM).
• Continued proliferation of ISDN technology which can be used for H.323 wide area links.
• The introduction of class-of-service offerings for traditional, packet-based technologies such as frame relay.
Maintaining secure networks is also a concern among IS professionals.
The End User
End users are typically indifferent as to the network on which they are running. To them, it's the conferencing application that is of paramount importance. They do not care if it is H.320 or H.323 running over ISDN, ATM, or frame relay. End-users expect one thing: when they click on the button, it works. The compelling reasons to use videoconferencing and collaboration will come quickly when the available tools meet the specific needs of the application. As these tools are introduced to the market, we will see a more widespread acceptance of H.323 technology among the end-user community. Conferencing technologies generally assist people in making more informed decisions more rapidly. A certain percent of the population will immediately gravitate to these technologies. Outside of these first-tier applications, the adoption of conferencing will be slower. However, it will happen. From the users' perspective, conferencing is just an extension of the multimedia platform experience.
The Web has done a great deal to accelerate the value of networks and the expectations of users to have rapid, secure, and accurate answers to an array of questions. H.323 will eventually offer a variety of tools to meet specific vertical market needs. When reaching someone at their desk with "eyes and ears" is as easy and cost effective as using a telephone, the preference will be for higher bandwidth communications, especially if the image quality and interactivity are natural. Rapid adoption of the technology will follow.
Conferencing technology will eventually be integrated in all standard productivity applications. This will make it relatively easy to extend these technologies into custom applications. Some examples where real-time video will be important include virtual human resources screening tools (interviews), just-in-time training applications, a conference-enabled graphic design department's tracking and production calendar, and a virtual medical consultation/triage center.
• Over the next five years companies will expand their network infrastructures, gradually adapting them to meet the demands of multimedia applications.
• Ultimately, most information technologies will share a common network (otherwise known as "consolidation" or "convergence").
• Centralized servers will take on management responsibilities, maintaining the businesses critical data warehouses and supporting various services to end-points.
• The clients on IP networks will have access to a wide array of stored information and applications as well as support for real-time services such as Internet-/intranet-based telephony and videoconferencing.
Forecasts & Market
Multimedia Telecommunications Association64
In today's economic environment, there is a growing shortage of skilled labor and a growing need for increased productivity. These factors are forcing companies to focus on economizing on their use of scarce labor while maximizing use of the specialized skills that are available. As competition becomes more intense, the need to innovate or otherwise develop products or services that can help a company maintain or enhance its market position becomes more pressing. One response to these market forces is the development of project teams that combine interdisciplinary skills. In short, collaboration has become an important corporate tool for meeting challenges. Collaborative technologies are intended to raise productivity and save money by reducing travel time, bringing down travel costs, and making it easier for people in remote locations to work together.
Spending on collaborative technologies totaled an estimated $7 billion in 1997, an increase of 29% over 1996. A majority of that total, $4.1 billion, was accounted for by videoconferencing, with audioconferencing tallying $2.4 billion and groupware $425 million. Competitive pressures and labor scarcities are expected to characterize the marketplace over the remainder of the decade, and these factors should continue to propel spending on collaboration. By 2001, overall spending on collaboration is projected to reach $15.7 billion, escalating at a 22.6% compound annual rate from 1997. Videoconferencing is expected to increase at a 25.5% annual rate to $10.3 billion. Spending on groupware is projected to total $1.2 billion in 2001, growing at a 28.3 percent rate, while audioconferencing will expand at a 15.7% rate, reaching $4.3 billion by 2001 (see Table 7.3 and Table 7.4).
Table 7.3. The Overall Collaboration Market ($ Millions)
Sources: MMTA, Data Communications
The H.323 standard, if it proves to be effective, should make videoconferencing a cost-effective option for a greater number of companies, but with the market increasingly comprised of lower-cost desktop systems, spending growth will moderate. Spending on videoconferencing equipment is projected to rise to $2 billion by 2001 from $930 million in 1997, growing at a compound annual rate of 21.1% (see Tables 7.5 and 7.6).
Table 7.5. The Videoconferencing Market ($ Millions)
Sources: MMTA, Data Communications
Spending on services, which consists of time charges, line costs, and the use of third-party services, totaled an estimated $3.2 billion in 1997. Spending on services reflects the growing installed base, in excess of 25,000 establishments, and the increased use of videoconferencing as a collaborative option. The anticipated expansion of the installed base over the next few years should lift services spending. Spending on videoconferencing services is expected to grow at a 26.7% compound annual rate over the 1997-2001 period, reaching $8.3 billion by 2001.
Total spending on videoconferencing will rise from $4.1 billion in 1997 to a projected $10.3 billion in 2001, representing an average growth rate of 25.5% compounded annually.
Table 7.6 Growth of the Videoconferencing Market (%)
Sources: MMTA, Data Communications
The increased need to make better use of scarce skilled labor and the trend in the rapidly changing economy to the use of group projects have spurred the demand for data collaboration. Meanwhile, the introduction of new software products to meet these collaboration needs while making use of the Internet is allowing more companies to participate in the market. Spending on groupware totaled an estimated $425 million in 1997, up 25.7% over 1996. Over the next few years, growth rates are expected to be even higher as more companies discover the benefits of collaboration. By 2001, groupware spending is projected to reach $1.2 billion, nearly three times the 1997 total. Growth over the 1997-2001 period will average 28.3% compounded annually.
Table 7.7. The Groupware Market
Sources: MMTA, Data Communications
Audioconferencing was an estimated $2.4 billion industry in 1997, 21.8% larger than in 1996. This is a market driven less by penetration growth than by economic growth, which is boosting sales and generating greater demand for external and internal communications. Expansion of videoconferencing and data conferencing should not displace, or compete with, audioconferencing. Audioconferencing is generally used for purposes different from those of either videoconferencing or data conferencing. Spurred by a robust economy, particularly in the near term, spending on audioconferencing is projected to grow to $4.3 billion by 2001, increasing at a 15.7% compound annual rate.
Table 7.8. The Audioconferencing Market
International Multimedia Teleconferencing Consortium
According to industry reports, the conferencing market is growing at a rapid rate of 37% per year and is expected to reach US$39 billion by the year 2002.65
Frost & Sullivan
Bolstered by standards, the videoconferencing market has been growing rapidly, with the systems and services market climbing 38.3% per year, according to Frost & Sullivan. U.S. videoconferencing revenue hit $5.8 billion in 1997, the latest year available from the research firm.66
Global Phenomena
The following graphic shows the projected distribution by geography of videoconferencing system (equipment) sales based on revenues and the projected distribution of video-telecommunication transmission services by revenues.
Figure 7.15. Worldwide Videotelecommunications Market Forecast, 1995-1999
Source: View Tech, Inc.67
A Market Analysis of Videoconferencing in Europe68
The market for videoconferencing systems, MCUs, and services in Europe is gaining in importance. In 1997, this market was worth $3.46 billion. It is expected to grow at a rapid rate as companies begin to incorporate videoconferencing as part of their telecommunication needs.
The market is rapidly growing due to the need of companies to remain competitive in a global business environment that is dependent on telecommunications for its success. Corporate headquarters are increasing their reliance on videoconferencing to communicate with their subsidiaries and affiliated companies on a worldwide basis. This technology enables them to save money on traveling costs and makes it possible to better utilize the time of their key personnel. This enables them to improve their productivity level and gives them increased leverage in a global market.
From Group to Desktop Systems
Initially, the market was dominated by group systems. In 1997, these accounted for a shipment of 15 thousand systems that corresponded to revenue of $375 million. The recent introduction of standard-based desktop systems is changing the nature of the market. Companies are gradually introducing these systems in an effort to improve their communications within and outside the corporation. In 1997, there were 81.5 thousand desktop videoconferencing systems shipped in Europe. This corresponded to revenue of $89.8 million.
Videoconferencing is changing the manner in which people work, unnecessary trips can be avoided, teleworkers can remain in contact with their offices as well as with their colleagues, which makes them feel less isolated.
More Than Just Business
The impact of this technology can be felt outside the business sector as applications are being developed in the fields of education and healthcare. These sectors are being driven towards a greater dependence on videoconferencing through the needs they have to reduce costs and improve their efficiency. For instance, in healthcare, this may lead to the implementation of remote diagnostic facilities and the delivery of medical services in remote locations. Another example is in education with the establishment of distance learning programs geared at people living in far away places. In 1997, the business sector accounted for 86.4% of the revenue for the total videoconferencing market; education accounted for 7.8%, and telemedicine followed with 5.6%.
The demand for videoconferencing systems is expected to increase substantially as end-users increase their use of advanced telecommunications systems and services in order to conduct virtual meetings at all organizational levels. The need to communicate with several sites simultaneously is expected to give rise to an increased demand for MCUs. In 1997, this lead to the shipment of 3.8 thousand MCU ports which represented revenue of $16.4 million. The increased size of the established base of videoconferencing systems is expected to create a flourishing service industry.
The Services Market
In 1997, the total revenue for the European services market amounted to $61.8 million. The provision of bridging facilities for multipoint conferencing accounted for 40.8 percent of the above revenue. Demand for consulting services accounted for 1.9%, and the maintenance and management sector accounted for the remaining 57.3%.
The cost of owning a videoconferencing system and the charges levied by network operators are rapidly decreasing. These systems will thus become more affordable to a wider range of end-users. In 1997, revenue attributable to the European transportation market amounted to $2.89 billion. This consisted of ISDN utilization charges. In 1998, corporations are expected to decide on the transport method they are going to choose for their video traffic. They are going to have to decide between H.323 or H.320 standard-based products. These standards, plus the recent introduction of the T.120 standard, mean that companies can now be assured that their systems can communicate with other products.
Desktop Videoconferencing
Demand for desktop videoconferencing extends to the consumer market, which also includes SOHO (small office/ home office) users. In 1997, this market accounted for a shipment of 45.1 thousand systems. This represented revenue of $22.8 million. These systems were either H.323 or H.324 based. The desktop market can be sub-divided into a number of categories whether systems are hardware-based or software-based. The business market currently relies almost exclusively on hardware-based products because of their greater processing power. Conversely, the consumers market consists mainly of software-based products because of cost issues.
Factors Driving the European Market
The European market for videoconferencing is being driven by a number of factors. These include:
(1) The increased availability of ISDN across Europe, which is bringing videoconferencing into more enterprises. Geographical differences, nonetheless, continue to exist between countries. For instance, Germany has been actively promoting the use of ISDN within the consumer, as well as business markets, while the United Kingdom is only beginning to promote the use of ISDN to the business sector.
(2) Failing prices are bringing videoconferencing technology into the economic reach of more companies. Videoconferencing was, until recently, the domain of a select few multinationals able to allocate substantial resources for maintaining and operating this technology. However, increased competition is causing prices of group and desktop systems to fall.
(3) Telecom deregulation is driving communications prices down and is leading more competitors into the value-added services. Manufacturers of videoconferencing systems are expanding their range of services to include maintenance and management of systems on behalf of their customers. Likewise, PTTs are offering similar services to their existing customers and are developing new services.
In spite of the success of videoconferencing within given business sectors, growth of this market is still being hampered by some factors. These include:
(1) Cost of ISDN connections remain too expensive in some European markets for small companies. Although ISDN is rapidly gaining in popularity across Europe, the connection cost and subsequent line rental continues to differ substantially between countries.
(2) Low margins threaten small players. The increased level of competition in the European videoconferencing market is causing companies to lower their margin in order to maintain market share. Large players like PictureTel and Intel are able to make up the loss through an increase in shipment volume. However, small players, which include manufacturers and some system integrators, don't have the leverage of the big industry participants and are threatened by a decrease in margins.
(3) Lack of awareness among potential end-users of videoconferencing is slowing down growth in this market. Large manufacturers such as PictureTel, Intel, and Sony are still finding out that many would be buyers lack the necessary understanding of the technology and its benefits. This is resulting in long sale cycles, especially for expensive group systems and MCUs.
A Look Toward The Future
Companies that are active in the videoconferencing market are facing a number of challenges which need to be addressed if they are going to be successful in the coming years. These include:
(1) Lack of awareness among potential customers is lowering the potential size of the market. The difficulty lies in convincing the management of SMEs (Small and Medium Enterprises) of the benefits that videoconferencing can bring to an organization. Manufacturers of videoconferencing systems still have a lot of groundwork to do with respect to educating potential end-users.
(2) A shortage of new applications could potentially damage the market. Growth within the videoconferencing market could rapidly increase with the development of new applications. How companies use videoconferencing in conjunction with other business activities could determine how rapidly the market will expand.
(3) Companies feel the cost of marketing their products into a deregulated European telecommunications market. In order to expand into the opening market created by deregulation, videoconferencing companies must be able and willing to spend large sums of money on expensive marketing strategies before realizing any profits. Consequently, videoconferencing manufacturers should be prepared to allocate a large proportion of their revenue to their plans for an extended period of time.
Collaborative Strategies, LLC69
The Data Conferencing and Real-Time Collaboration Market in the New Millennium
LAN infrastructures have been available to corporations since the late 1980s, providing a high-speed backbone that supports data transfer. The rise of Intranets in the mid-1990s provided the infrastructure that CS' research shows is the most widely used for both real-time and asynchronous collaboration today. In the vast majority of cases, real-time tools are being used inside organizations first before being deployed with business partners or customers. For these external applications, the Internet is the ideal medium.
People naturally interact both synchronously and asynchronously. What has changed in the late 1990s is that real-time interaction is not only supported by the Internet's infrastructure but is being demanded by organizations reaching out to their workers, business partners, and customers. The Web supports inexpensive and virtually free interaction, and, by its nature, is a bi-directional graphical medium, unlike other forms of mass communication.
Regular Web users accept shorter cycle times as a fact of life. Because our society is beginning to move in "Web time," more and more workers are forced to treat a calendar year as if it were in dog years (passing seven times as fast!). New iterations of products, especially software, are being released on a semi-annual or quarterly basis. Software can be downloaded directly from the Internet anytime. Real time collaboration tools are proliferating and adoption is occurring more rapidly than the adoption of other social technologies in the past.
The real time collaboration (RTC) marketplace is made up of three interlocking technologies: audioconferencing, data conferencing, and videoconferencing. Armed with a sense of the larger forces that are shaping this market in 1999, let's examine some details culled from CS' recent research.
Worldwide Market Size
RTC is a $6.2 billion dollar market in 1999. Worldwide, audioconferencing will represent a $2.3 billion industry this year, while videoconferencing (counting both room-based and desktop figures) has a value of $3.4 billion. These segments are respectively growing at 19% and 25% annually. Sales channel revenues were factored into the videoconferencing estimates since most vendors pass through a channel partner before reaching the customer. The teleconferencing estimate accounts for service provider revenues only, and does not include hardware sales (such as bridges, switches and PBXs).
Data Conferencing Growth
The data conferencing market, which receives particular attention throughout the report, is growing at a much faster rate that the other two segments of RTC. CS' calculations indicate the average annual growth rate between 1998 and 2002 for data sharing will be 64%. Further, the growth rate between 1998 and 1999 is an astounding 111%. In 1999, data conferencing vendors and their channel partners comprise a $550 million market. CS forecasts this market will grow to $1.8 billion by 2002.
Clearly, data conferencing is the current "sweet spot" of RTC. A couple of the drivers of this surge are that such products and services require no new hardware and only minor behavioral changes. The biggest challenge to this technology today is education. Many companies, for example, don't realize they may already have these tools in-house. Everyone who has Windows 98 (or downloaded and installed it into Windows 95) has NetMeeting, yet surveys indicate less than 10% of potential users leverage the application regularly.
We expect the U.S. to represent at least two-thirds of the data conferencing market for the next few years. Assuming our projected average 64% annual growth rate between now and 2002, we estimate that by then:
• The total number of data conferencing users will be 12.9 million.
• The total number of corporate or other organizational deployments will be 35,750.
Data Conferencing Deployment Functionality and Current Valuation
The functional areas for which user organizations have implemented data conferencing applications are indicated below as percentages of the market. Associated with these segments is what CS has determined their relative worldwide dollar valuation to be in 1999:
Although all of these areas will grow significantly in coming years, Web-based sales and marketing uses are the fastest growing functional sub-segment.
Vertical Markets, Divisional Synergies, and User Survey Feature Results
According to CS research, the four vertical markets adopting these technologies most rapidly are:
• High tech (which has the infrastructure and cultural requirements).
• Financial services (a hyper-competitive, rapidly changing market that demands real-time response).
• Telecommunications (largely because data conferencing is only a small step away from audioconferencing).
• Pharmaceutical (getting drugs to market faster not only saves lives but dramatically impacts the bottom line).
The divisions and job functions that adopt data conferencing most quickly are:
• Customer service and support.
• Training and information management.
Our survey of nearly 100 data conferencing users indicates that application sharing continues to be the single most important feature in a data conferencing product (28%). However, slide presentations (21%), whiteboarding (21%), and real-time text chat (20%) have also become popular. Collaborative Web browsing and other features (9%) are also built into many data sharing products and services.
The Data Collaboration Vendor Market
We have identified some 50 vendors in the data conferencing marketplace today. As synchronous data collaboration becomes more widespread, many vendors will fall victim to the forces of competition. CS expects rapid consolidation of the vendor market over the next three years. We anticipate there will be eight to 10 vendors left by 2002. Large companies, such as Lotus and Microsoft, are highly likely to still be active in this space by that point. Who the others will be cannot be easily determined at this time.
We also foresee the data conferencing market fragmenting rapidly into application specific niches, and we believe a number of vendors will select these niches in which to specialize. We are already seeing indications of this, as WebLine focuses on customer call center support, Pixion (formerly PictureTalk) focuses on distance software demonstrations, and Centra focuses on training for sales and marketing teams. We see the market splintering along both vertical and horizontal lines. Latitude is an example of a company going after the horizontal virtual meeting market. CS believes channel partners will also add more value over time as they become more sophisticated, and we expect a corresponding increase in their revenues.
CS has identified three principal vendor groups that have similar technological and functional orientations. One vendor model offers products that are integrated into an organization's existing infrastructure and require software (and occasionally hardware) installations on end user's computers. These thick client tools are often used on intranets and used to facilitate internal corporate communication and training. Thin client vendors leverage the Internet and standard browsers. Nearly half of this group's end users are attending live sessions over the Web, and sales and marketing is the single largest use of these applications. The thin client vendors all offer their applications as a hosted service (many sell servers as well), allowing organizations to outsource data conferencing functionality rapidly and inexpensively. A third group, what CS refers to as hybrid model vendors, tries to straddle the fence between the two previously described vendor groups. Many are browser-based, for example, but only sell servers (accompanied by some services) and are typically used for internal purposes. A fourth group, made up of synergistic vendors who integrate their asynchronous tools with data sharing applications, also impacts this market. Taken together, some two dozen vendors are thoroughly detailed in the report.
Key Trends
Key trends that impact RTC and will continue to do so in the future include knowledge management, globalization, technological advancements, and the convergence of audio and data. E-commerce and application outsourcing are emerging forces that could also significantly impact data collaboration early in the new millennium.
Conclusion
data conferencing today is the "sweet spot" of RTC. We expect this market to grow rapidly as this technology moves beyond what author Geoffrey Moore described as the "early adopters," and crosses the chasm into the mainstream. We see integration of these products and services with mature teleconferencing technologies as one good way of surviving the crucible (our metaphor for valid markets undergoing consolidation).
Because data conferencing is a young market, it is experiencing tremendous growth that we anticipate will significantly add to the revenues of teleconferencing and videoconferencing vendors. We believe that education is still the largest barrier to adoption for both data- and videoconferencing (although adding additional hardware like cameras and video boards are also a cost/complexity barrier). As more and more users get comfortable with data sharing applications, they will further expand into the use of desktop video systems for special applications that require this function.
The Gartner Group
Figure 7.16 depicts projections by The Gartner Group that indicate videoconferencing systems (equipment) will continue growing in terms of total revenues at a compounded rate of greater than 60% per year.
Figure 7.16. Videotelecommunications Systems (Equipment) Market Revenues Forecast,
1995-1998
Key Note70
The U.K. videoconferencing market was worth £90m in 1997, an increase of 25% from 1996. Volume sales rose much faster, by 111.5%. Value spending has been held back by the rapid reduction in market prices and the shift in the market towards desktop systems. Currently, the market is dominated by integrated services digital network-based (ISDN) systems, although local area network-based (LAN) systems are gaining in importance.
• The introduction of agreed technical standards.
• Recent price reductions and the falling cost of installation.
• The rapid growth of worldwide telecommunications systems (e.g., switched plain old telephone systems [POTS], high-speed switched local area computer networks, the Internet and corporate intranets).
• Recent dramatic quality improvements; the availability of video-enabled PCs.
• The support given to the market by the government and major telecommunications companies.
• The proven benefits of videoconferencing for multinational companies.
The videoconferencing market essentially splits into three broad segments: conferencing systems, both group and desktop, including hardware and software, and associated costs, such as installation; other hardware (including multipoint control units (MCUs), standalone CODECs (compression/decompression), video modems, etc.); and services (mainly maintenance).
The major issues facing the market now are:
• The growth of LANs and wide area networks (WANs) in business.
• The potential for asynchronous transfer mode (ATM) to open the LAN and WAN market to videoconferencing systems.
• The introduction of new MCUs.
• The introduction of new products, like larger screens, compact systems, sophisticated videophones, and plain old telephone-enabled systems (POTS).
Key Note estimates the U.K. videoconferencing market will grow by 177.8% between 1998 and 2002. By the year 2000, desktop systems will have overtaken group systems in terms of value spending, while other equipment sales and sales of customer services will grow strongly. Services will be the major growth area over the coming five years, albeit from a low base, followed by desktop systems and then other equipment. Group systems will show strong growth, but at a rate much lower than the rest of the market.
Roadmap
A Roadmap for Deployment71
Deploying any networked application and associated technologies requires a clear roadmap. Since every network is essentially unique and composed of multiple unique subnets, there is no guarantee that the lessons learned through the actual building process of one H.323-compliant network will apply to the next. This said, the following sections discuss some general principles to consider.
Evaluate users' needs. In evaluating users' needs, consider the fact that H.323 is a complete system with a combination of telephony-like and data network-like services. Given this assortment of new services, users will not immediately utilize them all. To a certain extent, it is the responsibility of the application and network designers to collaborate in forecasting the behavior or common-use scenarios for potential applications.
Constrain applications at the outset. Understand and constrain the most-likely applications during an introductory period. For instance, a video help desk has some common requirements with a PBX-based automatic call center application. However, H.323 video capability may bring new efficiencies such as being able to see a broken part in an order-desk application. Behavioral and business process changes will be required in order to take full advantage of these new capabilities. Such changes are best taken in small pieces.
Predict bandwidth requirements. Based on the projected behavior of the different application users, predict the bandwidth needed on a particular network segment and on the WAN. Whether using a gatekeeper or configuring the terminal to address bandwidth allocation, the formula to constrain the application bandwidth and patterns will depend on the total bandwidth available on the subnets, in the backbone, and on the WAN.
Estimate call volume. Estimating call volume will help you calculate required bandwidth. As a whole, people who are involved in a variety of consultative and ad hoc calls will vary in their ability to adapt to the new characteristics of H.323-compliant conferencing. Most companies have telecommunications management tools that track and report call activity. A conservative prediction of call volume in the first four months of deployment would be one-third the normal call volume would transfer to the IP network, leaving two-thirds on the PBX. As time progresses, successful deployments will see an increase in call percentage over the IP network.
Risk Factors
Even though most vendors conform to the T.120 data conferencing and H.232 videoconferencing standards, compression, download time, and audio/video synchronization could be better and more consistent across platforms.
Reliability is also an issue, since any software or hardware failure can ruin an entire meeting. Data conferencing software itself is reasonably stable, but computers in general crash all too often. It's bad enough when a reboot causes a participant to miss part of a meeting. But when the host's computer or the central server running the data conference software goes down, the meeting comes to a halt and usually has to be continued later.72
Code of Conduct
Perhaps the biggest barrier to succeeding with conferencing is knowing when and how to hold a conference. The host must take extra time to plan the agenda, and he should have his electronic documents fully prepared and ready to share. Software should be properly installed on everyone's machine, and everyone should know how to use it.
Beyond that, the group has to agree on a code of conduct--who speaks when, how you interrupt, and so on. Conferees must know beforehand what and what not to expect. If you're going to rely on chat or Internet telephony for communicating, new users need to understand that it won't be as easy as talking on the phone.
Vendors could help by providing a guidebook on how to prepare for a conference. People could also benefit from tutorials, sample meetings, and wizards to produce training demos for new users. But people need a compelling reason to use a new technology, so getting good tools from vendors is only part of the solution. For example, Microsoft distributes NetMeeting from its Website for free and the software is installed automatically when you download Internet Explorer, but few people use NetMeeting or even know it's available.73
Distribution. Distributors face a number of challenges in the collaboration market. Since collaboration can include video, audio, computer, LAN, and Internet components, a variety of technologies and products are essential to make it work. Collaboration also requires that teams in different locations be able to work together. Moreover, collaboration involves a wide range of solutions that address differing needs. Distributors need to be able to help companies find the solutions that are most appropriate to their requirements and help companies implement solutions on an enterprise-wide basis. Since penetration of videoconferencing and data conferencing collaboration is relatively low, distributors face the additional task of helping companies understand the benefits of collaboration and how collaboration can work in a potential customer's corporate environment.
Understanding the Issues74
Homogeneous Networks
A homogeneous H.323/T.120 conferencing network may run over a variety of physical networks as long as all the video- and/or audio-enabled end points comply with the same standard. The homogeneous network may also support intranet/Internet applications via an independent Internet service provider. Despite their seeming simplicity, single-protocol applications require careful planning due to differences in:
• Quality of service guarantees on different network segments.
• Security issues (requires the purchase and configuration of a H.323 firewall and proxy server).
• Billing complexities such as access charges, metered network usage, and departmental billback.
Heterogeneous Networks
We define a "heterogeneous conferencing network" as any system of networked devices in which applications based on different communications protocols have a need to communicate. Some examples include:
• Networks with H.323 and H.320 end points.
• Networks with H.323 and H.324 end points.
• Networks with H.323 and other (proprietary) products.
Most of the issues associated with deploying homogeneous networks also apply to heterogeneous networks. In addition, heterogeneous networks need to support multiple protocols and probably will require additional components and functionality such as network gateways and algorithm transcoding.
These requirements should be further refined in order to determine the number and complexity of these components. Some things to be considered include the frequency of circuit-switched network access and the duration of a typical conference connection. Multiple conferencing protocols will complicate the planning, deployment, and configuration of multipoint conferencing. Therefore, the planning process should consider discreet segments of the total network solution incrementally.75
Security
When it comes to data and videoconferencing, network managers are facing a huge challenge: how to open up access for these tools without compromising network security. Because new conferencing applications based on the H.323 videoconferencing and T.120 data conferencing standards are designed for use over corporate intranets or the Internet, network managers are in desperate need of better tools to control access.
The T.120 standard allows users to hold electronic meetings in which files are transferred and/or shared on electronic whiteboards. Because they're concerned about remote users gaining access to the network, many network managers allow users to make outbound T.120 calls but block incoming T.120 traffic. Their security fears are heightened by the increasing capability of T.120, which will soon allow application sharing. With this capability, a remote caller could conceivably run applications on a T.120 user's machine.
The architecture behind H.323 videoconferencing, which also can incorporate T.120 data conferencing, requires adjustments to current security systems. Although H.323 uses a standard IP port to make a connection to a network, the H.323 control channel can spawn several auxiliary channels that use random IP ports, making it difficult for firewall security systems to detect and monitor H.323 traffic.
There are several alternatives for safeguarding these collaborative tools. One approach is to have each conference participant connect to an MCU (multipoint control unit) outside his or her network. Corporations could use an outside service to arrange this type of meeting, or they could purchase their own MCUs and place them in a demilitarized zone outside their network.
Another approach is to use a proxy server to provide secure connections through a firewall. All conferencing traffic would come to the proxy server, which would contact the recipient's machine.76
COTS Analysis
Video Conferencing Products77
The solutions presented in the following pages vary in their cost, functionality, and ability to interoperate with other systems. Some are designed for corporate conference room settings. Some are designed for single-user home PC environments. Some incorporate IP-based conferencing, others are designed to work over ISDN. Some were created with specific applications in mind, such as distance learning, or telemedicine. A handful of the cameras that are available for these types of systems are covered as well.
8∞8, Inc.
2445 Mission College Boulevard
Santa Clara, California 95054
Website: www.8x8.com
8∞8, Inc, has recently announced the Via-IP broadband videophone, a development system for audio and video telephony over broadband Internet connections. Delivering full 30-fps video at VHS resolution, the Via-IP platform is being used by cable modem manufacturers, cable television system operators, and telecommunications companies to develop broadband Internet telephone systems. The 8∞8 Via-IP broadband videophone is a small TV set-top device that uses a standard TV for display and a touch-tone phone for audio, dialing, and control. No PC is required to operate the Via-IP unit. Full compliance with the H.323 protocol ensures interoperability with other solutions, such as Microsoft's NetMeeting.
Based on 8∞8's VCP processor architecture, the Via-IP system supports all of the relevant ITU standards for Internet telephony, including the H.261 and H.263 video codecs; G.711, G.723, G.728, and G.729 audio codecs; Q.931 call signaling protocol; RAS gatekeeper signaling protocol; and H.245 call control protocol. The solution also offers echo cancellation and a complete TCP/IP stack. For more information, call 408-727-1885 or visit the company's Web site at www.8x8.com.
AG Communication Systems
2500 West Utopia Road
Phoenix, Arizona 85027
Website: www.agcs.com
AG Communication Systems' ATIUM VIA 188 is a corporate video conferencing solution designed to allow business professionals to communicate over distances in a cost-effective manner. The ATIUM VIA 188 offers simultaneous data and MPEG-2 (motion picture experts group 2) compressed video over ATM (asynchronous transfer mode technology). It has local- and wide-area network (LAN/WAN) connectivity and does not need to be connected to a switch to operate. It has multi-point add/drop capabilities that consume less bandwidth per application, so the user can get maximum use out of each line. VIA 188 supports multiple ATM MPEG decoders per box, so fewer boxes are needed for a network.
The VIA 188 accommodates video, audio, and embedded data applications for the network. AG Communications has also recently announced the availability of SVCs (switched virtual circuits) across the complete line of ATIUM products enabling the product line to work in any SVC-based ATM network. The solution can be used for a variety of applications, including distance learning, remote arraignment, telemedicine, and business conferencing. For more information, contact the company at 1-888-888-AGCS or visit their Web site at www.agcs.com.
Accord Video Telecommunications, Inc.
500 Northridge Road, Suite 200
Atlanta, Georgia 30350
Website: www.accord.co.il
Accord's MGC-100 multi-point control unit is based on a telco-grade architecture that offers numerous advantages to users and conference operators. The MGC-100 offers support of endpoints with different bit rates, frame rates, resolutions, and audio compression algorithms in the same conference. Designed with hot swappable, self-configuring modules, a high-speed multimedia bus, universal slots, and redundant power supplies, the MGC-100 enables a highly scalable multi-point conferencing environment. The MGC-100 supports up to 80 sites, up to 14 continuous presence/transcoding conferences, and up to 42 continuous presence/transcoding participants.
Recently, Accord announced that the company would integrate RADVision's H.323 Protocol Stack, in order to develop an H.323-compliant MGC-100. Using the RADVision H.323 Protocol Stack, Accord will provide gateway and multi-point conferencing capabilities for both IP and ISDN-based video conferencing users. All of Accord's advanced functionality, including continuous presence, five-way transcoding, T.120 data conferencing, and conference management capabilities, will be supported in the H.323 environment. For more information, contact Accord Video Telecommunications at 770-641-4400 or visit the company's Web site at www.accord.co.il.
FVC.COM
3393 Octavius Drive, Suite 102
Santa Clara, California 95054
Website: www.fvc.com
FVC's Video Access Node (VaN) implements broadcast quality video using H.310 MPEG-2 over ATM. The VaN's MPEG-2 over ATM video, with support for either 25 Mb/s or 155 Mb/s ATM connectivity, is comparable to the quality provided by VHS and laser disk systems. The VaN can be implemented on both campus ATM networks, and across the long-haul ATM networks that service providers are now installing for wide-area access. The system brings video conferencing, video-on-demand, and video broadcast to applications requiring high-quality video, such as distance learning and telemedicine.
The VaN supports First Virtual's Video Locator software, which allows users to schedule and manage calls through a Web-based interface. The Video Locator provides call management for videoconferences across multiple standards on the same network, including H.310, H.320, H.323, and low bit-rate endpoints. The VaN's own multi-point capabilities support up to a four-way multi-point conference using a single encoder and multiple decoders. As part of First Virtual's complete video networking solutions, the VaN supports video-on-demand using the V-Cache, and multicast using the V-Caster. The VaN is available as a fully integrated roll-about system, complete with cart, camera, and necessary peripherals, or as a stand-alone codec. For more information, call 408-567-7200 or visit the company's Website at www.fvc.com.
Intel Corporation
5200 N.E. Elam Young Pkwy.
Hillsboro, OR 97124-6497
Website: www.intel.com
Intel's TeamStation System 4.0 is a conference room workstation that combines video conferencing, Internet access, corporate network access, and PC applications in one convenient system. The product is billed as the first workstation to feature H.323- and H.320-compliant video conferencing in the same system, the ability to both receive and transmit high-quality video across either a LAN or ISDN. TeamStation delivers up to 30 fps (frames per second) full common intermediate format (FCIF) video at 128 Kb/s and 384 Kb/s, and operates at data rates up to 400 Kb/s, full duplex, on a LAN. Furthermore, Intel includes the H.261/263+ filtering algorithms for video smoothness and clarity.
TeamStation tightly integrates Microsoft's T.120 NetMeeting data conferencing tools, thus enabling window management for seamless video and data collaboration within a single call. For a more in-depth look at this product, as reviewed by TMC Labs, please refer to Internet Telephony's September issue (Volume 1, Number 3), page 48. For more information, contact Intel at 800-788-2286 or visit the company's Web site at www.intel.com.
Intelect Visual Communications
645 Fifth Avenue, 17th Floor
New York, New York 10022
Web site: www.videoconferencing.com
LANscape 2.1 uses Wavelet video compression to provide a smooth picture at up to 30 frames per second with fully synchronized CD-quality sound. Wavelet technology reduces the network load by selectively transmitting and reconstructing only those wavelengths of light that are most significant to the human eye, thus achieving compression ratios of 1:1 to 350:1.
LANscape 2.1 can run over an existing LAN using IP as the transmission protocol, which means that it can run on any IP transport network including Ethernet, Fast Ethernet, T1/E1, Frame Relay, ATM, and SONET. LANscape 2.1 offers software selectable network transmission protocols (i.e., IP Multicast (IPMC), IP, and UDP). The product eliminates the need for a Multipoint Conferencing Unit (MCU) to engage in a video conference with more than one person. Multipoint conferencing is inherent in the software, and since LANscape 2.1 offers multiple windows, if you are conferencing with more than one person, you can view each of them in individually scaled video windows. Lastly, because LANscape 2.1 offers IP Multicast support, you can actually reduce network load associated when video conferencing with multiple participants. IP Multicast allows you to send one message, one time to all participants. For more information, contact the company at 212-317-9600 or visit their Web site at www.videoconferencing.com.
Lucent Technologies
211 Mt. Airy Road, Room 3C348
Basking Ridge, New Jersey 07920
Website: www.lucent.com
Lucent's MultiPoint Conferencing Unit (MCU) is a multipoint audio, video, and data conference bridge that connects multiple locations around the world. It enables up to 25 locations to fully participate in a video conference, allowing participants to view up to 16 sites simultaneously on one screen. The MCU connects to public and private networks, and can be used behind a digital PBX or connect directly to video endpoints. Users can take advantage of the MCU's Conference Reservation and Control System, which includes scheduling and management capabilities. Another feature of the Lucent offering is SpeedMatching - this allows endpoints transmitting video at different bandwidths to participate in the same video conference.
The MCU supports the H.320 video conferencing and T.120 data conferencing standards. Release 5.0 includes the following enhancements:
• Panoramic screen layout.
• Incorporated H.263: Allows MCU to support H.263 endpoints, such as Polycom.
• Conference Manager enables easier management of a conference.
• OpCenter SP: Designed for service providers, enables real-time remote monitoring and control of conferences.
For more information, visit the company's Website at www.lucent.com.
Madge Networks
625 Industrial Way West
Eatontown, New Jersey 07724
Web site: www.madge.com
Madge Networks' LAN Video Gateway is fully compatible with the ITU H.320 video standard used to transmit video over ISDN and high-speed serial connections such as V.35. On the LAN side, the gateway is fully compliant with the H.323 standard for carrying video, voice, and data over local-area networks using the IP protocol and is interoperable with H.323 video codecs. A separate version of the gateway is available which allows existing H.320 desktop video codecs to be connected to the LAN.
In addition to acting as a link between the LAN and the PSTN, the gateway has an integral gatekeeper, which provides call control for video conferencing sessions. Individual LAN stations can be addressed by video telephone numbers or, under H.323, individual users' names may be used when dialing. Flexible PBX functions (i.e., call transfer and variable call forward) are built in and accessible from most H.323 and H.320 video codecs. Through the use of IP multicasting, one LAN station can broadcast video to many other LAN attached video codecs for training purposes, employee communications, and urgent video briefings. For more information, contact the company at 732-389-5700 or visit the company's Web site at www.madge.com.
Mitsubishi Electronics America
5665 Plaza Drive
Cypress, California 90630
Website: www.mitsubishi-imaging.com
The Diamond Video Series 9100 is a complete Pentium-based video conferencing system running DOS and Windows. The system includes a camera, media processor, system interface, control panel (or keyboard and mouse), and software. A unique in-band data port allows unrestricted collaborative computing and permits a variety of interactive applications such as business conferencing, telemedicine, distance learning, and video arraignment.
The Series 9100 media processor integrates, distributes, and manipulates multiple audio, video, and data sources. The Media Processor is based on an Intel standard PCI/ISA Bus, and features a VGA to NTSC scan conversion card, 3.5" floppy disk drive, 6x minimum CD-ROM drive, seven inputs, and seven outputs. The processor includes an integrated codec board, which supports an operating bandwidth of 56 to 1,984 Kbps. International video conferencing standards are met as the Diamond Video Series 9100 Media Processor complies with all CCITT/ITU standards and is compatible with ISDN BRI (2B+D), dual RS-499/V.35, and RS-366 (dialing) communications. For more information, contact the company at 800-843-2515 or visit their Website at www.mitsubishi-imaging.com.
Nogatech, Inc.
20300 Stevens Creek Boulevard
Cupertino, California 95014
Web site: www.nogatech.com
The Nogatech PCMCIA type II ConferenceCard is a one-card video solution for high-performance, real-time conferencing. A mobile solution for distance learning, voice-over document sharing, presentations, and remote video capture applications, Nogatech's ConferenceCard works together with many popular conferencing software packages, including Microsoft's NetMeeting, Intel's Internet Video Phone, PictureTel's Live Phone, and White Pine Software's Enhanced CU-SeeMe. The ConferenceCard provides both full-duplex sound and video capture capabilities to enable quality video and two-way audio conferencing directly on a notebook computer.
Offering full-motion video display and capture at up to 30 frames per second and a resolution of up to 320x240 (.avi format), the ConferenceCard is fully compatible with Microsoft Video For Windows and Windows Sound System as well as most video and audio conferencing software. Nogatech also bundles the ConferenceCard with a camera, headset, a cable for audio inputs/outputs and video inputs, and free video conferencing software, offering the solution under the name Mobile Video Pro, a total video and audio conferencing solution for notebook computer users. For more information, contact Nogatech at 408-342-1400 or visit the company's Web site at www.nogatech.com.
Nortel (Northern Telecom)
2221 Lakeside Boulevard
Richardson, Texas 75082
Web site: www.nortel.com
Nortel's Symposium Multimedia Conferencing 5.1 includes several new user features and an improved PCI video codec that provides up to 30 frames per second (fps) in full CIF mode. The new release retains the full feature set from the previous version (version 5.0): H.320 video conferencing, T.120 data applications, and other features including whiteboarding, application sharing, file transfer, chat, directory dialing, call logging, and a variety of connectivity options.
Symposium Multimedia Conferencing 5.1 offers onscreen camera control (requires a pan/tilt/zoom camera at the endpoint), and a presenter tool with the ability to store preset camera and audio control settings for quick switching during a videoconference. The presenter tool allows storage of preset documents and applications for easy opening during a conference.
Other features include advanced call diagnostics (updated in real-time during a conference) for both transmit and receive signals, and general improvements such as the ability to share Power Video's video broadcasts or video clip viewing during a conference. For more information, contact Nortel at 1-800-4NORTEL or visit the company's Website at www.nortel.com.
ONE TOUCH Systems
40 Airport Parkway
San Jose, California 95110
Web site: www.onetouch.com
ONE TOUCH Systems' Front Row is a Web-based application that delivers real-time audio, video, and Web knowledge to interactive distance learning (IDL) students at their desktops via corporate intranets. Front Row provides the same instructor/learner interactivity as a broadcast TV classroom via patented Response Keypads, which permit participants to speak directly with the presenter and respond to multiple choice or alphanumeric questions. The presenter can also guide students through Web content by synchronizing and updating the participants' browsers in unison.
Front Row minimizes the impact of traffic on corporate networks by incorporating the latest compression and transmission standards. Front Row delivers 15 fps video to the desktop using less than 3 percent of the bandwidth of a typical 10Base-T Ethernet network by employing the H.263 video compression standard and the G.711 audio compression standard in the Intel MDS streaming multimedia framework. For more information, contact ONE TOUCH at 408-436-4600 or visit the company's Web site at www.onetouch.com.
OutReach Technologies
9101 Guilford Road
Columbia, Maryland 21046
Web site: www.outreachtech.com
The CONFERease 900, from Outreach Technologies, is a T.120-compliant, real-time, multi-point Windows NT conferencing server designed to combine business-quality audio communications, document conferencing software, and teleconference management software into a single, turnkey system. Aimed at enterprises and service providers alike, the CONFERease 900 supports from 24 to 96 users and leverages communications infrastructure such as existing phone (PSTN/PBX) and TCP/IP networks.
CONFERease 900 enables users to maximize conference productivity. For example, while engaging in a conversation through the synchronous voice connection, participants can share applications or documents and make and review changes in real time. Furthermore, CONFERease 900 features multi-level security options, allowing users to schedule and instantly create conferences, view conference calendars, change conference settings, disconnect participants, create custom IVR messages, and generate activity and usage reports from any designated network desktop. As an added security measure, administrator and conductor capabilities are password-enabled. For more information, contact the company at 410-792-8000 or visit their Web site at www.outreachtech.com.
PictureTel Corporation
100 Minuteman Road, M/S 721
Andover, Massachusetts 01810
Web site: www.picturetel.com
PictureTel's LiveLAN visual collaboration solution enables users to meet in virtual conference rooms and perform H.323-compliant, business-quality audio, video, and data sharing over their existing corporate IP infrastructure or any IP network. Release 3.1 of LiveLAN, LiveManager, and LiveGateway offer enhancements that allow customers to receive video at up to 30 frames per second at very high network speeds. LiveLAN and LiveManager also support FORE Systems' native ATM, designed to provide Quality of Service (QoS) and expand available network options.
Other LiveLAN 3.1 features include network transmission speeds up to 768 Kbps, support for Microsoft Internet Locator Service (ILS) browsing; and Lotus Notes integration, enabling LiveLAN to initiate a call to another client listed in a Lotus Notes address book. New features of LiveManager 3.1 include network status monitoring via the Web, the ability to share LiveGateway resources between two or more LiveManagers, and the integration of LiveManager and LiveGateway consoles. Upgrades to LiveGateway 3.1 enable customizable greetings and improved T.120 data sharing capabilities. For more information, contact the company at 978-292-5000 or visit their Web site at www.picturetel.com.
Polycom, Inc.
2584 Junction Avenue
San Jose, California 95134
Web site: www.polycom.com
Polycom has recently announced their new ViewStation V.35, a video conferencing system that delivers 768 Kbps full-motion video capabilities and supports Microsoft's NetMeeting. Augmenting the Polycom ViewStation 128 and ViewStation 512 products that support ISDN networks, ViewStation V.35 enables customers on both public and private networks worldwide to deploy ViewStation throughout their organizations. ViewStation V.35 provides full-motion 768 Kbps video over digital networks such as T1, E1, and PRI and also includes H.331 broadcast mode support to allow users to transmit high-quality broadcast video transmissions. With Microsoft NetMeeting support, users can share data and applications real-time in-band.
The product's support of RS-366 allows customers the option to place either dialed or non-dialed calls. Furthermore, the product includes dual monitor support, a voice-tracking camera, integrated presentation capabilities, and remote management capabilities. Fully H.323 ready, ViewStation's innovative embedded Web server enables easy access for remote system management and diagnostics, as well as simple software upgrades via the Internet or Intranet. For more information, call 408-526-9000 or visit the company's Web site at www.polycom.com.
Prolink Computer, Inc.
15336 East Valley Boulevard
City of Industry, California 91746
Web site: www.prolink-usa.com
Prolink's Pixelview Meeting Pak Plus is a video conferencing solution incorporating the Brooktree 848 chipset. The solution is PCI 2.1-compliant and offers plug and play capabilities. In addition to supporting NTSC, PAL, and SECAM video inputs as well as Composite and S-Video inputs, the Meeting Pak Plus offers a motion display of up to 30 frames per second, relayed through the PCI master bus interface where the video resolution is boosted to 24-bit 320x240 pixels. The solution supports Microsoft's Video for Windows as well as Windows 95.
The Meeting Pak Plus consists of a TV/FM tuner and capture card combination utilizing the Brooktree 848 chipset, a Phillips brand analog camera, a microphone, the necessary installation drivers, and bundled video conferencing software. The video conferencing software allows users to see and hear each other on their PCs through the Internet or via standard telephone lines. For more information, contact the company at 626-369-3833 or visit their Web site at www.prolink-usa.com.
RADVision
575 Corporate Drive, Suite 420
Mahwah, New Jersey 07430
Web site: www.radvision.com
The L2W-323 is a self-contained standalone gateway designed to translate between the H.323 and H.320 protocols, and convert multimedia information from circuit-switched to H.323 IP packets. On the PSTN side, the product supports either voice-only calls, or H.320 video conferencing sessions. The L2W-323 enables users to exchange audio, video, and data in real-time from 64 Kbps to 384 Kbps. The L2W-323 supports up to eight concurrent voice calls or four concurrent video calls between users on different networks. Users of an L2W-323-enabled network also benefit from full end-to-end support for T.120 sessions, provided all terminals support the standard in their collaborative applications.
The L2W-323, working in conjunction with an embedded RADVision H.323 GateKeeper, provides the functionality of a multimedia PBX, allowing internetwork calls, direct inward dialing, call forward and transfer, and custom call control via IVR and DTMF signaling. Real-time routing (or bypass routing) between network segments is provided. Optional hardware modules perform real-time audio transcoding between G.723 and G.711, as well as G.728 and G.711. For more information, contact the company at 201-529-4300 or visit their Web site at www.radvision.com.
Siemens Business Communications
4900 Old Ironsides Drive
Santa Clara, California 95054
Web site: www.siemenscom.com
Siemens Business Communications has introduced the Hicom Xpress IP Video, a video conferencing solution that enables video calls between LAN-based and ISDN-based PC video conferencing systems. The Hicom Xpress IP Video solution enables the following applications: distance learning, telesales, telemedicine, and remote patient consultation. Hicom Xpress IP Video is a component of Siemens' recently announced Multimedia-IP LAN solution.
Siemens has partnered with RADVision and VCON to deliver this solution. The Hicom Express IP Video product is comprised of VCON's voice, video, and gateway system operating on an IP network-connected PC, a video client from VCON that runs on a LAN-connected PC, and a video gateway from RADVision that connects the video clients to a Siemens Hicom communications server. The Hicom Xpress IP Video enables connectivity between LAN video and ISDN video through the RADVision video gateway. Compatibility exists between disparate video products as long as they conform to either the H.323 or H.320 industry standards for video conferencing. For more information, contact Siemens at 408-492-2000 or visit the company's Web site at www.siemenscom.com.
VCON
17440 N. Dallas Parkway, Suite 200
Dallas, Texas 75287
Web site: www.vcon.com
VCON's MediaConnect 8000 offers cost-effective, real-time group video conferencing over IP and ISDN. The group meeting system combines a 3BRI single-board solution with multimedia capabilities up to 768 Kbps LAN and 384 Kbps ISDN conferencing. The MediaConnect 8000 addresses several key end-user issues: Television-quality video with audio synchronization; Document sharing without eliminating video quality; and Multimedia capabilities.
Features of the MediaConnect 8000 include voice-only calls over IP, video and audio conferencing up to 384 Kbps ISDN and 768 Kbps LAN at 30 fps, and T.120 data conferencing. The system runs over multiple communication protocols, including LAN, WAN, ATM, ISDN, and frame relay. The MediaConnect 8000 system includes a codec, 29" SVGA monitor, 200 MHz MMX Intel-based PC, roll-about cart, a 10/100 IP or ISDN network connection, wireless keyboard, pan/tilt/zoom camera, speakers, and a microphone. Furthermore, a 32-bit Software Developer's Kit (OCX 32bit) is available for customized application integration with VCON's MediaConnect and desktop systems. For more information, contact the company at 972-735-9001 or visit their Web site at www.vcon.com.
VideoServer, Inc.
63 Third Avenue
Burlington, Massachusetts 01803
Web site: www.videoserver.com
VideoServer's Encounter Family of IP (Internet Protocol) conferencing products is designed to deliver mainstream video conferencing over the Internet. The Encounter Family IP conferencing solution offers businesses clear audio, video, and data collaboration over the Internet, optimizing the available bandwidth and integrating essential multi-point services, gateway functionality, and conference management. The solution is comprised of three products: Encounter NetServer, Encounter NetGate, and Encounter GateKeeper.
The Encounter NetServer is an H.323 Multimedia Conference Server (MCS) for LAN-based conferencing applications, and the Encounter NetGate is a gateway server connecting ISDN and IP conferencing endpoints. Both the NetServer and NetGate are built on the popular Windows NT/Intel architecture and are fully compliant with the international standard for IP-based conferencing (H.323). The NetGate also supports the international T.120 standard for data conferencing. These products ensure interoperability between conferencing endpoints from Microsoft, Intel, PictureTel, VCON, and others. The family also includes Encounter GateKeeper, which controls access and bandwidth utilization. For more information, contact the company at 617-229-2000 or visit their Web site at www.videoserver.com.
White Pine Software, Inc.
542 Amherst Street
Nashua, New Hampshre 03063
Web site: www.wpine.com
MeetingPoint cost-effectively delivers multimedia group interaction over the Internet or any IP network, such as a corporate intranet. The product integrates into existing networks, and can be configured and administered remotely from any computer with a Web browser. Furthermore, MeetingPoint even manages the amount of bandwidth required for group interaction and takes full advantage of IP multicast technology.
White Pine has recently announced MeetingPoint version 3.5. Some of the audio subsystem enhancements offered in this new version include G.711 and G.723 audio mixing, mixing of multiple audio streams (enabling "hands free" conferencing), and silence detection/background noise suppression. Video subsystem improvements include support for full CIF video (in addition to QCIF) and video switching based on amplitude detection.
MeetingPoint 3.5 is now optimized to work with Intel ProShare, PictureTel LiveLAN, and Microsoft NetMeeting clients. For more information, contact White Pine at 603-886-9050, or visit the company's Web site at www.wpine.com.
Zydacron, Inc.
7 Perimeter Road
Manchester, New Hampshire 03103
Web site: www.zydacron.com
Zydacron's OnWAN350 is a Peripheral Component Interconnect (PCI)-based desktop video conferencing package that can run at up to 30 frames-per-second (fps). An integrated desktop video conferencing solution with ISDN-BRI on a single PCI-compatible codec board, OnWAN350 features the latest AVP-III Video/Audio Processor chipset from Lucent Technologies. Lucent's AVP-III Video/Audio Processor is one of the industry's most complete video conferencing solutions, offering video, audio, acoustic echo cancellation, and communication protocol functions. The AVP-III codec chip supports standards-based, two-way, real-time video conferencing over both analog and digital lines.
The product is designed to provide a complete communications solution offering T.120 support for data collaboration as well as full Microsoft NetMeeting integration. Other OnWAN350 features include:
Onboard ISDN communications with S/T and U interface.
Built-in ISDN analyzer software
Call size up to 128 Kb/s.
MCU support.
End user diagnostics.
For more information, contact Zydacron at 603-647-1000 or visit the company's Web site at www.zydacron.com
A panel of distinguished judges reviewed new products featured at MultiMediaCom '99, and selected top prize winners in nine categories, providing special recognition for the innovative products and their companies during the nation's largest networked multimedia event. They were:
(1) Best New Deployment & Management Tool: MGC-100 from Accord Video Telecom.
(2) Best New Streaming/Broadcasting Product: Digital Lava's VideoVisorT Professional.
(3) Best New Developer's Tool: 384k ISDN BRI Video Conferencing Emulator from Merge Technologies Group.
(4) Best New Audio Conferencing Product: Polycom's SoundPoint Pro.
(5) Best New Video Conferencing Product: Polycom's ViewStation MP.
(6) Best New Data Conferencing Product: Polycom's WebStation.
(7) Best New Streaming/Broadcasting Service: Vialog Group's MessageCast.
(8) Best New Multipoint Conferencing Service: Managed Conference Services Group from V-SPAN.
(9) Best New Consumer Conferencing Product: Xirlink's IBM PC Camera with IBM Mail.
The judges praised the latest crop of high tech innovative products and services. Matt Kramer noted that Polycom was the big winner, taking first place in three categories at the show. Kramer commented that "Polycom's conferencing products are very strong. Obviously, this is a company that is constantly striving to improve its products across the board."
In the category of Best New Video Streaming Product, Digital Lava garnered special praise from Trudy Wonder. "I was really pleased with this upgrade," she said. "They have added huge new capabilities and the quality was great." She described it as enabling the user to manipulate the subject matter more and being more user-friendly.
The "Best New Streaming/Broadcasting Service," which went to Vialog Group Communications' Messagecast, was called "really useful for getting information out rapidly" by Al Huberty. He pointed out that it really fulfills a need.78
Advanced Conferencing
The world is becoming smaller, yet the distance between locations is not changing. As a result, new ways of conducting business has become a necessity. Worldwide, nationwide, even statewide collaboration must often take place to complete a project, meet a deadline, or plan a future. To facilitate this, conferencing software is being used with increasing frequency to provide the necessary connections for the collaboration. With ISDN and desktop conferencing (see section on basic conferencing), workgroups can be brought together in ways that are easier, faster, and less expensive. Individuals can "fly" all over the world and never leave their desks.79
A collaborative environment facilitates workgroup computing, optimizes productivity, and fosters innovation by allowing users to share ideas and applications remotely. Many organizations are implementing collaborative computing to expedite research and development, support business decision-making, and improve competitive positioning.
Idea generation is another group activity that is effective and economical with software as the medium rather than conducting a face-to-face meeting. Idea generation or electronic brainstorming involves exchanging typed comments anonymously and simultaneously over a computer network. It has been demonstrated to be superior to the typical oral meeting by increasing group satisfaction with the process, reducing meeting time, increasing participation and idea generation, increasing group synergy and consensus, and providing other benefits.80
Collaborative systems are increasingly cost justifiable as well. In a time where the life of a product or service may only last a month and where the newest information remains new for only hours, every minute counts. Traditional mail services do not meet the time needs of today's businesses and information seekers.
As a means of enabling corporate communications, desktop conferencing tools can be as basic as a shared whiteboard or shared application functionality. Such lower-bandwidth collaborative solutions support improved technical collaboration, introduce users to the desktop conferencing paradigm, and can provide a seamless migration path to fuller conferencing capabilities when required.81 Conferencing software also allows for anonymous communication via online communities, decision-making (a.k.a., group consensus), or idea generation.
Technology Background
Initial developments for real-time point-to-point sharing of data between two participants using inexpensive PCs and simultaneous voice began in the early 1990s. However, acceptance of such systems by the market was sluggish, mostly because the technology existing at that time let only two users share data and voice. In addition, these early products were not flexible.
Some of the earliest text-based applications--well before the advent of the graphical browser and the Web--involved chat rooms, bulletin board systems (BBSs), and multiuser dungeons (MUDs) as ways of bringing people together. Typically, these were simplistic, stark, text-based environments that enabled users to become immersed in the experience as if it were a physical place--if the interactions were rich enough. Fortunately, most of the impact of user collaboration can be obtained through "low-tech" solutions, such as chat, application sharing, and illustrated audio for real-time needs, and discussion databases, news groups, and bulletin boards for asynchronous collaboration.82
Multipoint, as opposed to point-to-point, denotes a conference of at least three participants that can be stationed within a corporate campus or at sites hundreds of miles apart (see Figure 7.17). The word synchronous can also be used to loosely qualify it as real-time conferencing.
Figure 7.17. Point-to-Point versus Multipoint
Source: IEEE Spectrum
There are four levels of real-time conferencing, based on the needs of the meeting (see Figure 7.18). At the low-cost end of the complexity and functionality spectrum are simple chat sessions; these are the most time-consuming and the least expensive mode of a remote meeting. One level up is data conferencing together with shared whiteboard. At this level, everyone at a meeting can see the document brought up on the monitor, but not everyone may be able to edit the document. That capability is available in "universal" document editing, which is the third level. These three levels, especially the last two, may or may not include audio exchange among the participants, although the presence of audio enhances the value of a meeting. The fourth level offers full data-, audio-, and video-sharing capabilities among the participants. It also yields the most intrinsic value, despite having the highest cost.83
Figure 7.18. Four Levels of Remote Real-Time Conferencing
Source: IEEE Spectrum
With the development of the Internet and its phenomenal growth, the process of exchanging information has been revolutionized. Internet protocol (IP), the underlying communications language of the Internet, makes multipoint data flow possible in three modes (see Figure 7.19):
• Unicast, in which data packets travel between two specified points.
• Multicast, which allows data packets from one user to be replicated in the server or the multicontrol unit and forwarded to all recipients in a specific conference session.
• Broadcast, which allows data from one client to reach everyone on the network, even if they have no interest in the packets.84
Multipoint data sharing on desktops satisfies many real-life needs. The meetings can be set up on short notice without the aid of skilled technicians or a dedicated wide-bandwidth line. It also saves time and travel expenses.
Figure 7.19. Multipoint Data Flow Methods
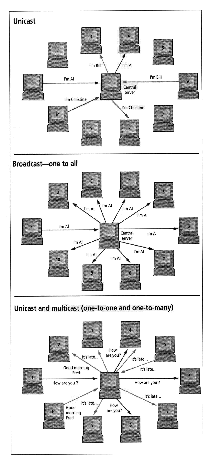
Online Communities
One of the most exciting social aspects of bringing millions of people online is the potential of building geographically disparate, but socially or ideologically compatible communities. These online communities:
• Enable the collection and filtering of ideas.
• Draw users into self-defining interactive experience.
• Can be synchronous, i.e., real-time, or asynchronous.
• Can be extrinsic (a site) or intrinsic (a function).85
While communities are most often associated with entertainment "chat rooms" and cited as an emerging tool for e-commerce, their fundamental contribution is in the incubation of new ideas and knowledge.
Figure 7.20. How Communities Create Value
Source: Gartner Group
From a utopian perspective, the attractive premise of online communities is that we can share ideas and pool knowledge not based on who is physically next to us, but on a much larger scale, and tap into the minds of hundreds or thousands of people. All of the ideas and knowledge offered by each of the members is used to advance the current knowledge base or frame of reference. A primary benefit of building an online community is making social interactions and learning comfortable and intuitive, and giving a context in which participants can communicate. Participants are not forced to passively watch the proceedings, but can be a part of the creative process. By helping shape the community, they feel a sense of ownership, are likely to return, and implicitly understand not only the "what" of the content, but the "why." By combining an open forum for collaboration with the explosive growth of online interactive communications and the Internet, online communities offer a ready conduit for building massive networks of ideas.86
Why Do Discussions Facilitate Community?
World Wide Web content has become very rich, but many Websites lack a sense of people and personality. Enabling online discussions can engender a sense of community for the Web audience. Providing discussions in an online community has several advantages.
• Research has shown that sites with conversation areas draw people back much more frequently than sites that only feature prepared content.
• Discussions provide a new source of fresh ideas and content.
• Including real people and their personalities into a Website helps develop a sense of "place."
• Your audience grows as participants invite colleagues and friends to join their discussions.87
How to Build an Online Community
Online communities flourish when people gather. But attracting people with shared interests is no guarantee that the group will become a community, just as holding a party at your house doesn't automatically turn it into a memorable occasion. Like the golden moment when a group of people becomes a team with an almost audible kerCHUNK, community happens when the participants personally care about one another and demonstrate a commitment to the group.
While you can find plenty of online conversation, there are few real communities on the Web. Even the busier Web-based discussion groups are like the waiting room at the utility company office--everyone taking a number and waiting to get his question answered, then leaving with no further thought to the other people in the room.
Creating a community online is an ability that comes to some people naturally, but it's a learnable skill. Unfortunately, nobody has taken the time to enumerate even the simplest of the rules.
So What Is Community, Anyway?
It doesn't matter what you call it: forum, conference, or bulletin board. The names have changed over the years, but the concept has never wavered: People get together to share experiences, to ask questions, or just to hang out with people who think that quilting is interesting, that Macintoshes are cool, or that it's possible to learn to write a screenplay.
An important key to any online community is the ease with which people can correspond with one another. That's why it's important to make it easy for anyone to find an interesting conversation and why the software must make it easy to dash off a response. User interfaces that slow down this process get in the way of communication; it's like making someone walk to a podium to use a microphone; only the fearless or the extremely opinionated will bother. That awkwardness is a good part of the problem with slow online interfaces and poor message-thread management.
A successful forum is like the TV show Cheers, where everybody knows your name. Whether they're in-person or online, communities happen when the participants begin to care about one another personally. You know that your discussion group has "made it" when participants arrange to have dinner together at COMDEX, or when several members get embroiled in an off-topic conversation about current events or which car to buy. Your discussion group becomes a community when people treat the forum as a place to meet their friends.88
Technology Overview
Choosing the appropriate communication tools for an online community is critical. Communication tools are generally private (one-to-one interactions) or public (simultaneous interactions among multiple people); synchronous (messages are exchanged in real time) or asynchronous (messages accumulate, so you need not be online simultaneously to interact).
E-mail. Because it is ubiquitous on the Net, e-mail is a useful tool for holding your community together. Simple e-mail distribution lists can be incredibly powerful for making announcements or for facilitating communication between users. Open discussion lists (using Majordomo, Listserv, or other mailing-list technologies) can even allow conferencing-style interactions among community members, though mailing lists do not create the same sense of "gathering" in a location with other community members that conferencing-style interaction can provide.
Conferencing. Perhaps the most crucial technology for long-term community development, conferencing systems allow individuals to post messages on the electronic equivalent of a bulletin board, usually sorted by topic, and to read the messages others have posted. This is crucial in establishing gathering places on a site. The hundreds of conferencing technologies include traditional USENET-style news servers, Web-enabled versions of traditional BBS software (WELL Engaged, Caucus, and Spinnaker), custom-developed Web applications (Motet, Post-on-the-Fly, WebCrossing, and Allaire Forums), and custom systems developed in-house at various online publications (c|net's Posting area, and HotWired's Threads). David Wooley's excellent Computer Conferencing on the Web89 site should help you navigate the various choices. As with all community areas, effective hosting of conferencing areas is critical to their success.
Chat. Realtime chat is perhaps the most frequently misused community technology. Everyone wants a chat server, but nothing sends away users more quickly than an empty chat room, or an "interactive event" that doesn't allow them to interact. Operating multiple chat rooms requires substantial resources to plan and staff interesting events and to moderate interactions as necessary. To further complicate matters, the chat-software market is not yet mature. Few currently available technologies combine an excellent user experience and easy integration with stability and scalability. Over time, Java is likely to become the platform of choice for developing chat solutions. Current room-based chat servers include freeware (IRC, ICB) and commercial products (iChat, Quarterdeck Global Chat), as well as avatar-based, graphically oriented systems, MUDs, MOOs, and so on. Regardless of the technology you choose, it is important to establish policies concerning acceptable behavior in your chat areas and have mechanisms in place to enforce these rules before you open the virtual doors.
Instant messaging. With instant-messaging technologies, you keep a "buddy-list" of compatriots who use the same system. At any given moment, you can check which of your buddies are currently online and send an instant text message, initiate a chat session with that user, open a Web page on the other user's screen, or start an Internet telephony session or online videoconference. These systems include AOL's Instant Messenger system (over 43 million users), ICQ (over 40 million registered users90), and Microsoft's MSN Messenger Service (1.3 million users91). Both AOL/ICQ and MSN have proprietary protocols; however, Microsoft announced it will make the MSN Messenger Service protocol available to the industry by the end of August 1999.92
Member database. A member-database system is essential for creating member profiles that evolve over time. Ideally, a single member database should control access to Web pages, mailing lists, conferencing areas, chat rooms, and member profiles. Both hosts and community members should have access to the member database as appropriate.
You can use a standard relational or other database system (like Microsoft SQL Server, Oracle, Informix, or Sybase, or their freeware alternatives), or create a homegrown, customized solution. The Lightweight Directory Access Protocol (LDAP) is an emerging standard in this area, though products that use it (such as Netscape's Directory Server) are not yet mature.
Careful planning and design--of both user interface and user experience--is critical in creating the "fertile soil" for your Web community. Choosing the right platforms critically impacts whether your members will find the community habitable and enjoyable, whether they will return frequently, and whether they will develop the personal relationships that make online communities worthwhile.93
Major Players
Online communities, once a haven for techies and hobbyists, are now big business. A growing number of commercial Websites are adding discussion groups to provide technical support, build brand recognition, and provide a gathering place for users who share common interests. Vendors are meeting this fresh demand with a range of Web-based discussion software tailored for every taste--and every price. More than a dozen companies offer commercial products for building online communities, and any number of shareware and freeware products are also crowding the market.
Instinctive Technology, Inc. (http://www.instinctive.com/). 725 Concord Avenue, Cambridge, Massachusetts 02138. Tel: 617-497-6300; Fax: 617-497-5055.
eShare Technologies, Inc. (http://www.eshare.com/). 51 Mall Drive, Commack, New York 11725. Tel: (516) 864-4700; Fax: (516) 864-0833; Toll Free: (888) ESHARE4.
Ventana Corporation (http://www.ventana.com/). 1430 E. Fort Lowell Road, Suite 301, Tucson, Arizona 85719. Toll Free: (800) 368-6338; Tel: (520) 325-8228; Fax: (520) 325-8319.
iChat (http://www.ichat.com/).
Microsoft Corporation (http://www.microsoft.com/). One Microsoft Way, Redmond, Washington 98052-6399. Tel: (425) 882-8080.
Infopop Corporation (http://www.ultimatebb.com/). P.O. Box 1861, North Bend, Washington 98045.
Netscape World Headquarters (http://home.netscape.com/). 501 E. Middlefield Road, Mountain View, California 94043. Tel: (650) 254-1900; Fax: (650) 528-4124.
Lotus Development Corporation (http://www.lotus.com/). 55 Cambridge Parkway, Cambridge, Massachusetts 02142. Tel: (617) 577-8500.
O'Reilly & Associates (http://software.oreilly.com/). 101 Morris Street, Sebastopol, California 95472. Tel: (707) 829-0515; Fax: (707)829-0104.
Lundeen & Associates (http://webcrossing.com/). P.O. Box 2900, Alameda, California 94501. Tel: (510) 521-5855; Fax: (510) 522-6647.
WELL Engaged LLC (http://wellengaged.com/). 2320 Marinship Way, 2nd Floor, Sausalito, California 94965. Tel: (415) 339-7000; Fax: (415) 332-9355.
Novell, Inc. (http://www.novell.com). 122 East 1700 South, Provo, Utah 84606. Toll Free: (888) 321-4272.
SoftArc Inc. (http://www.softarc.com). 100 Allstate Parkway, Markham, Ontario L3R 6H3, Canada. Tel: (905) 415-7000; Toll Free: (800) SOFTARC; Fax: (905) 415-7151.
New Technology
When it comes to Web conferencing, there is one prediction that's easy to make--it will get better. In particular, user interfaces will improve as Javascript, dynamic HTML, XML, and similar developments free software designers from the HTML straitjacket they have been forced to wear. And performance will improve as bandwidth increases and enhancements to the hypertext transfer protocol are adopted. But the most interesting changes will be in the features that conferencing software offers, and in how it is used.
The biggest challenge facing most Web conferencing sites is simply getting people to visit regularly. Enticing people to take a look at a Website is one thing; getting them to make a habit of returning every day is much more difficult. It takes effort to visit a site to see if there is anything new, and the activity there must consistently be useful and compelling, or most people will fall out of the habit of checking in. Some people never form the habit even if the content is useful, simply because there is nothing to remind them to check the conference.
Discussions that take place over e-mail lists don't have this problem. E-mail discussions come to you, rather than you having to go look for them. Whereas it requires continuing regular effort to check a Web conference, it requires effort to stop receiving messages from an e-mail list. Once you have subscribed to a list, you must take conscious action in order to unsubscribe. For this reason alone, e-mail lists have a natural tendency to accumulate participants over time, while Web conferences have a natural tendency to lose participants.
E-mail lists also have an advantage for applications where the discussion is sporadic. A list can lie dormant for weeks or months, and then spring to life again when one participant posts a new message. But when activity in a Web conference slows, people stop checking in, and any new message that is posted goes unnoticed.
Web conferences have many advantages over e-mail lists. Some of the more important ones:
• Context. E-mail messages arrive in your in-box in random order, with no context. In order to establish context, participants must quote material from earlier messages. Often people quote entire lengthy messages, because e-mail software typically does this automatically. It's not uncommon to see quoting two or three levels deep: quotes of quotes of quotes. All this extraneous material tends to obscure the flow of the conversation. By contrast, a Web conference establishes context for each message automatically. To see what prompted a given reply, it's only necessary to scroll up or click on a "previous message" button.
• Selective reading. A participant in a Web conference can choose which threads of conversation to follow. Often there is a way to "forget" or "ignore" a topic that doesn't interest you, so that future responses to the topic are not displayed at all. But with an e-mail list, it's all or nothing.
• Heavy traffic. Participants in e-mail lists are easily overwhelmed if the amount of message traffic increases significantly, or if a number of topics are being discussed simultaneously. Most people are sensitive to the amount of e-mail they receive. This is why a misplaced "unsubscribe" request, or an off-topic message, frequently generates a torrent of angry replies. Managers of high volume lists sometimes find it necessary to institute rules about how often people may post in order to prevent the list from disintegrating. Web conferences can support high volume discussions much more easily due to the way they organize conversations and their ability to allow selective reading. A bit of off-topic banter in a Web conference is no great cause for alarm because it is so easily ignored.
• Sense of place. Web conferences provide an immersive environment that gives participants a "sense of place." A well designed conference gives its participants visual cues as to what sort of place it is, who is present, and what the expectations are.
But these advantages matter little if nobody shows up. Designers of Web conferencing software are beginning to recognize this, and some have incorporated e-mail features into their products.
One way to get people to return to a Web conference is to notify participants by e-mail when there is new activity in a conference they have joined. This can be done any number of ways; which is best depends on the situation. Some possibilities:
• Once a month, send e-mail to any conference members who have not visited the conference in the past month. The message could include a summary of active topics of discussion.
• Allow conference members to request daily or weekly e-mail summaries of new activity.
• Let members register their interest in specific topics, and notify them by e-mail when new responses are posted to those topics.
• Notify members about new responses to discussions they have personally participated in. (After posting a message, people are almost always interested in seeing what others have to say in response.)
The dominant Web browsers have built-in e-mail capabilities, and even most standalone e-mail software is now "Web aware". Hence, including a URL in any e-mail notification can provide instant access to the conference. Ideally, a single click from the notification message should take you directly to the new messages in a specific discussion topic.
Eventually, notifications could be delivered via techniques other than e-mail. Imagine an icon on your desktop that you could click on to instantly get an overview of what's new at every Web site you have opted to track.
If we can automatically notify people about new messages by e-mail, why not go all the way and send the messages themselves? For that matter, why not let people reply by e-mail, as well?
In fact, a few Web conferencing systems have already done this, and more are sure to follow. The Web conference essentially doubles as an e-mail list server, allowing people to participate fully either via the Web or by e-mail. This is a great boon for people who have e-mail but not graphical Web access, or who find the Web too slow, cumbersome, or expensive to use regularly.
Of course, e-mail participants lose some of the advantages that Web conferences normally offer. In particular, the "sense of place" is lost. Some context is also lost, as new messages arrive with few hints as to what the preceding messages in the thread might have said.
But the overriding fact that e-mail pushes messages out to passive receivers will make this an important capability for Web conferences in the near future. This will likely be a rising trend for the next two or three years. Ultimately, however, full participation by e-mail will probably become irrelevant, as fast Web access becomes cheaper, more convenient, and more reliable. More and more people will have full time, instant access to the Web. When the Web is fully integrated into your working desktop environment, then "going to" a Web conference no longer feels like a chore.
On the other hand, automatic notification of new messages, whether by e-mail or some other means, will continue to be an important feature, even when full participation by e-mail becomes outmoded.
From a conference administrator's viewpoint, the advantage of notification is its ability to catch peoples' attention. The amount of time people have in a day is fixed, but the demands for their attention seem to be growing without limit. The result is that attention is an increasingly precious commodity. Anything you can do to capture your audience's attention more effectively is valuable.
From a conference participant's viewpoint, notification is a matter of convenience. If there are a dozen discussions that you want to keep an eye on, regularly checking them all for new activity is a pain, even if each one is just a click away. And there's no reason you should have to.
Mixed Media
The Web is a multimedia platform, and some existing Web conferencing software takes advantage of this. But even when multimedia capabilities are available, they are used relatively rarely. In the future, nontext media will likely come to play a greater role in conferencing systems. But some media will always be used more than others. Time efficiency is a major factor in the choice of media. In particular, how much time does it take to create a message, and how much time does it take to receive it?
For example, let's compare text with recorded speech. Imagine that all technical obstacles to the use of speech over the Internet are eliminated: every computer in the world is equipped with a microphone and speakers, audio support is built into every Web browser, and plenty of bandwidth is available. Will speech then replace text as the medium of choice in conferencing systems?
From the sender's point of view, speech might well be preferable, because it's faster to speak a message than to type it. But for recipients, the reverse is true: it's much faster to read a message than to listen to it.
A message posted in a conference is created only once but received many times. So as a general rule, efficiency for the recipient matters more than efficiency for the sender. Or to put it another way: the sender presumably has an interest in the message being received and understood. But the potential recipients typically have less at stake, and are likely to skip messages that are difficult or time consuming to receive. The sender has good reason to use a medium that is preferred by the intended audience.
The answer, then, is that speech will never replace text as the primary medium for conferencing even if all technical obstacles are removed, simply because of the time issue. It would take too much time to peruse the messages in an all-speech conferencing system.
Speech recognition systems, capable of automatically converting speech to text, have been improving steadily. As they become more prevalent, some people will find it convenient to use this technology to post messages in conferences. This is especially likely in Asia, because typing Asian languages is difficult. A conferencing system might store both the text and the original spoken version of such a message.
Text has other advantages over speech, including greater precision, searchability, and efficiency of storage. It also has obvious advantages for the deaf and hard of hearing. It has disadvantages, as well, especially the lack of vocal expression that carries so much meaning in speech. And speech has clear advantages for the visually impaired. The bottom line is that speech will be used more often in conferencing as it becomes technically easier to do so, but it will be used mainly for special purposes, and will not displace text as the dominant medium.
Recorded speech is just a special case of recorded audio. What role will audio and video recordings play in conferencing? These media have the capacity to communicate in ways that text can never match. But they run into the same problem as speech: they take a lot of the recipient's time and so are likely to be skipped over, unless the recipient has some reason to believe that the message is especially important or interesting.
They have another problem, as well. Conferencing is a conversational medium, not a publishing medium. Like e-mail, conferencing is used for rapid communication and exchange of ideas; it is not well suited to publishing polished works. Occasionally someone might spend as much as an hour composing a particularly important or detailed response, but most messages in an online conference are dashed off quickly.
What kinds of audio and video messages can be created quickly enough to be a common form of communication? There are really only two possibilities: recordings of the message sender speaking, and clips copied from other sources. Even assuming the production tools are readily available, anything else just requires too much time and effort to be used regularly in everyday conversation. But as the tools for creating and receiving audio and video become easier to use, these media will be used somewhat more frequently than they are now, when their special capabilities are called for.
Images are popping up with increasing frequency in Web-based conferences. There is good reason for this, and the trend will probably continue. Again, the critical factor is time. For a recipient, an image is very efficient: a well designed image can convey a complex concept at a glance. As they say, a picture is worth a thousand words. For senders, too, a picture is sometimes the quickest and easiest way to communicate an idea. This is why lecturers draw on chalkboards, and why engineers discussing ideas over dinner pull out their pens and scribble on napkins.
There are two main obstacles to the widespread use of images in conferencing:
(1) Images take a long time to download compared to text.
(2) The tools for creating images are not common enough and are too hard to use.
The first problem is simply an issue of bandwidth. It will disappear over time, as faster Internet connections become standard. The second problem is more complex: it's an issue of conventions as well as software design and availability.
Today, conferencing systems that allow images within messages do it in one of two ways. The more primitive way involves the message author providing a reference to an image that resides on some other server. This leaves the author at his own devices to somehow put an image on some Web server to which he has access. More sophisticated conferencing software allows uploading images directly to the conference. But even this involves a lot of steps for the author: he must launch a separate drawing utility, create an image, save it in a file, then return to the conferencing site, find the "upload" option, and specify the file name to be uploaded.
It shouldn't be this difficult. It ought to be just as easy to include a sketch in an online message as it is to scribble on a yellow pad during a face-to-face meeting. While typing a message into a text box in your Web browser, you should be able to click on a drawing tool and begin sketching a picture or diagram, or import an image from a digital camera or scanner. The image you create should be treated as an integral part of the message, not as a separate file that requires special handling.
It will be some time before tools for creating and manipulating images are this well integrated into every person's desktop environment, but it will happen eventually.
Discussion Structure: Threaded vs. Linear
Almost as long as conferencing systems have existed, there has been an ongoing debate about how online discussions should be structured. The two main contenders are:
• Threaded, hierarchical tree structures. In this model, a response can be attached directly to any message, so a discussion can potentially branch out infinitely. (The term "threaded" has been in use for many years without being well defined, but recently it seems to have become the accepted term for describing tree-structured discussions.)
• Linear structures, also known as "comb" or "star" structures. In this model, responses are always added to the end of a linear chain of messages. Within a conference, many of these linear discussions can go on in parallel, each about a different topic.
The linear structure is simpler to navigate and more closely resembles face-to-face conversation. In side-by-side comparisons, some conference administrators have found that a linear discussion promotes far more activity than a threaded one.
Nonetheless, many people are familiar with threaded conferences, and feel frustrated with what they view as a lack of flexibility in the linear structure. This has become something of a religious war, but the truth is that both models have their place. In general, threaded structures seem to be better for question-and-answer applications like technical support, while linear structures are more conducive to extended, deep conversation. In the past, every conferencing system has been designed to support one structure or the other fairly rigidly. But the distinction is now beginning to blur a bit.
Some threaded conferencing software now displays each discussion as a continuous stream of responses, making it resemble a linear structure despite the fact that responses can be added at any point. And some conferencing software is now offering administrators a choice of structures, so that some conferences may be linear and others threaded. In some cases, individual users can even choose to view the same conference in either mode. This trend toward merging the linear and threaded structures is likely to continue, as software developers recognize that there is a continuing demand for both.
Real and Unreal Time
Conferencing is an asynchronous medium, meaning that it is independent of time. The advantages of this are obvious. You can participate at your own convenience rather than having to match schedules with other people. Also, you can take as much time as you need to read and digest what others have to say, and to compose your own thoughts before posting a reply.
But it has drawbacks, as well. It takes a lot of calendar time to complete a conversation. It can be difficult to reach consensus on a decision because it's hard to tell when everyone has had their say. Heated arguments can flare up over trivial misinterpretations of words.
Many conferencing systems have added real-time chat to their capabilities. This is a natural development, not only because chat is popular and fun, but because groups working together at a distance need to be able to communicate both asynchronously and in real time.
In the future, additional real-time communication features will be built in, particularly "white board" capabilities that allow participants to sketch diagrams and drawings for each other as they chat. Real-time audio and video conferencing might also be added.
All of these real-time media need to be integrated seamlessly into a conferencing environment, so that participants can move fluidly between synchronous and asynchronous communication. For example, if you miss a scheduled chat meeting, you should be able to find a transcript of the session posted in the conference, along with white board sketches that were exchanged. When you enter a conference, perhaps a corner of the screen will display a list of who else is reading the conference at the same time. Or you might even find an ongoing chat session, which you can monitor as you glance through conference posts, going in and out of real time.
Identity
Conferencing systems today generally have their own proprietary mechanisms for registering participants. This poses some problems:
(1) Organizations that have their own Intranets usually already have some means of registering people so they can log into the network, exchange e-mail, etc. Institutions that offer distance learning through online courses also have their own registration procedures. In either case, making an off-the-shelf conferencing package recognize the existing logins and registration mechanisms can be difficult. But often, the only alternative is to require people to go through a separate registration and use a separate ID for the conferencing system.
(2) People who participate in a number of online conferences at different sites have to have a separate identity at each site. Just keeping track of all those logins and passwords can be an impossible task, let alone keeping your personal profiles up to date at every site you visit occasionally.
What's needed to solve the first problem is a standard method for maintaining and verifying identities. The Lightweight Directory Access Protocol (LDAP) might provide a good set of conventions for this purpose. Registration procedures could become modular components of conferencing systems, so it would be a fairly simple matter to make a given conferencing system use an existing directory of users.
Solving the second problem is more difficult. Eventually, there might be some way for each person to uniquely register their identity on the Internet as a whole. Registering for a new online conference then becomes a matter of setting up a link between that conference's records and your universal identity server.
That would be very convenient, but it also raises privacy concerns. You might not want your identity in a gay chatroom to be easily associated with your identity on your employer's network, for instance. It needs to be possible to control which portions of your personal information are available to whom. This is a very complex issue, which is not likely to be resolved entirely any time soon.
Where's the Action?
At a large conferencing site, a newcomer or occasional visitor is faced with a daunting task: how to find the most interesting and active discussions. There might be dozens of conferences and hundreds of existing discussions, many of them long dormant. But they all tend to look about the same when you're scanning lists of titles.
Why does this matter? We tend to think of conferencing as being independent of time, and to a certain degree it is. But its time independence is not absolute. If you post a reply to an old discussion, you might find that the people you are attempting to engage are no longer reading the conference. Even if they are, they might feel they have already exhausted the subject and have little interest in revisiting it. By not being present when interest in a certain discussion is high, you miss the chance to participate in it. You can read the proceedings later, but that's a very different, less rich experience.
Conferencing systems need to develop easier ways for people to find the "hot spots." These methods need to be highly visual, so you can understand them at a glance. For example, imagine a cluster of dots next to each conference or discussion title. The density and color of the dots might indicate how many people are involved in the discussion and how long it has been since they have visited it. A large cluster of bright red dots could indicate a currently active discussion involving many people; a few violet dots would indicate a recent discussion among a small group; a cluster of blue dots would indicate a discussion that has been dormant for a while.
But this isn't enough. It would also help to know who is participating in a discussion, and whether it matches your interests. If a certain discussion has attracted people whose interests are similar to your own, chances are good that it will be worth your while to read it.
"Collaborative filtering" is a technique that has received a lot of attention recently. Online merchants are already making use of it. For example, a bookseller can keep track of all the titles you have ordered. By matching your list against those of other customers, they can find other people whose interests seem similar to yours. Then they can alert you to other books that have been popular among those people.
A few conferencing systems have dabbled with collaborative filtering by providing ways for participants to rate their interest level in messages or discussions. Such methods are problematic, though. For one thing, being constantly asked to rate things is a burden; it's time consuming and distracting from the discussions at hand. Secondly, it is difficult to get people to distinguish between their interest in a message and their agreement or disagreement with its content.
Future conferencing systems will likely make use of collaborative filtering, but it will have to be done automatically, without relying on participants to rate discussions.
Making Sense of the Discussion
Often, a long discussion will leave the participants feeling a bit lost. The conversation might have taken so many twists and turns that people are unsure of where they have gotten to, or even what the original question was.
It is enormously helpful to have a facilitator occasionally post a summary of what has been said so far. A summary might identify areas where consensus has been reached, and questions that are still unresolved. It might point out the major themes that have arisen, providing a framework for further discussion. It can summarize arguments that have been made, so as to prevent the discussion from retracing the same ground over and over. And the summary can provide links to the full original text of any messages that it references.
A good summary is helpful to the participants, but even more valuable to anyone coming late to the discussion (provided that the conferencing system makes it easy to locate the summary.) In addition, a well-written summary, with links back to the original discussion, can serve as the publishable "product" of a discussion.
It's too much to hope that such summaries can ever be generated automatically. Writing a good summary requires human intelligence; it involves not just comprehending the meaning of individual messages, but recognizing and describing complex patterns and relationships between them.
But conferencing software could make the summarizer's task easier. Existing software provides few tools for digesting and making sense out of the massive quantities of text that are often produced during an online discussion. Consequently, creating summaries involves much more tedious, rote work than it should.
For example, perhaps the system could provide a facilitator with a way to mark key phrases and sections of text while reading through past messages, or to make notes "in the margin." Then the software could generate a display consisting only of the highlighted segments and facilitator's notes, along with message headers and links back to the original text. This would provide the facilitator with a partially digested overview of the discussion, making the major trends easier to spot. And this overview could be imported into a text editor to use as the starting point for a summary.
Even if the facilitator doesn't go on to write a full-blown summary, the overview produced by this process might be very helpful to participants. To date, very little work has been done on such tools. It's an area that is ripe for exploration.94
Machine-Mediated Communication
From e-mail to full-body videoconferencing, virtual communication is growing rapidly in availability and complexity. Although this richness of communication options improves our ability to converse with others who are far away or not available at the precise moment that we are, the sense that something is missing continues to plague users of current methodologies. Affective communication seeks to provide new devices and tools for supplementing person-to-person communications media. Specifically, through the use of graphical displays viewable by any or all members of a mediated conversation, we hope to provide an augmented experience of affective expression, which supplements but also challenges traditional computer-mediated communication.
At the MIT Media Lab, the Affective Computing group is conducting research on sensing and understanding the emotional state of the user for the development of affective interfaces. Part of their research in affective mediation explores ways to increase the "affective bandwidth" of computer-mediated communication through the use of graphical visualization. By graphical visualization, they mean the representation of emotional information in an easy-to-understand computer graphics format that could add emotions to online chat or e-mail. Currently their focus is on physiological information, but it may also include behavioral information (such as if someone is typing louder or faster than usual.) Building on traditional representations of physiological signals--continuously updating line graphs--one approach is to represent the user's physiology in three-dimensional, real-time computer graphics, and to provide unique, innovative, and unobtrusive ways to collect the data. This research focuses on using displays and devices in ways that will help humans to communicate both with themselves and with one another in affect-enhanced ways. For a complete list of current research projects, visit their Website at http://www.media.mit.edu/affect/AC_affect.html.
Collaboration through Wearables
Many of the target application areas for wearable computers are those where the user could benefit from expert assistance. Internet-enabled wearable computers can be used as a communications device to enable remote experts to collaborate with the wearable user. The Human Interface Technology Lab at the University of Washington95 is addressing how the computing power of the wearable computer can support collaboration between multiple remote people. They are exploring the following issues:
• What visual and audio enhancements can aid communication?
• How can a collaborative communications space be created?
• How can remote users be represented in a wearable environment?
These issues are becoming increasingly important as telephones incorporate more computing power and portable computers become more like telephones. They have already developed a prototype wearable conferencing interface and have found that the spatialized audio and visual representations of remote users enables intuitive collaboration.
Forecasts and Markets
Use of network/Web integrated collaborative environment (ICE) software, also known as groupware, leaped to 84 million users and $2.1 billion in revenues worldwide in 1998, according to a new International Data Corporation (IDC) report, Collaborative Applications Software Market Review and Forecast. IDC expects this segment to grow to $2.6 billion in revenues worldwide by 2003. While the email-only software market for enterprises slowed as the result of displacement by ICE solutions, group calendaring/scheduling and real-time (data) conferencing software markets grew at a rapid pace.
"The collaborative software market continues to show stellar growth, but our 20-year market view reveals this will not continue indefinitely. Growth will slow due to rising market penetration levels and competition from outsourced/hosted services that can offer compelling advantages including lower costs," said Mark Levitt, research director of IDC's Collaborative Computing research program. "Software vendors looking to sustain market growth must focus sales and marketing efforts on specific customer and industry segments, including service providers, as well as other country markets in which demand for standards-based collaborative and messaging software is still developing."96
Table 7.9. Forecast Market for Groupware Sales
Source: International Data Corporation
Table 7.10. Forecast Number of E-Mail Users Migrating to Groupware
Source: International Data Corporation
Table 7.11. Forecast Market for Chat and E-Mail Web Customer Service Products
Risk Factors
One of the biggest difficulties Internet collaborators face is the inherent impersonal nature of the medium. Even with the aid of audio and videoconferencing, it is difficult to capture the experience of a face-to-face meeting with a group of colleagues. Try as we may, we have yet to serve up a virtual pizza party with the ambiance of the real thing.
In order for a group of people to work together effectively it is important for them to understand each other. Typically this understanding comes through the type of informal interaction which is difficult to achieve electronically. But once this understanding is achieved it often becomes much easier for group members to reach a consensus, to compromise, to communicate with each other, and to understand each other's concerns.
Members of electronic groups who have never met in person are often unaware of other member' personalities. They tend to have trouble gauging group members' enthusiasm for an idea and easily misinterpret others' ideas. Without subtle visual queues, a miscommunication can easily go unnoticed until someone takes issue with something which nobody meant to imply and a flame war erupts.
And flame wars tend to erupt frequently among Internet collaborators. People who normally behave quite civilly seem to forget that the target of their flame is another person. They routinely say things in their e-mail that they would rarely or never say to someone in person. This may be due to the impersonal nature of the medium or the lack of entrenched social practice associated with online communication. Most adults have developed a sense of what is appropriate to say at a meeting, during a phone call with a colleague, or in a business letter. But many fail to apply similar rules of social practice to e-mail. In the absence of such social rules, Internet collaborators often resort to childish behavior, which goes a long way towards destroying any sense of community that had previously developed.
Some will argue that there are plenty of examples of people who have overcome the barriers of the medium and developed personal relationships over the Internet. However, in most cases these successful Internet relationships are one-on-one social relationships rather than group working relationships. Experience has shown that good group relationships are much more difficult to foster over the Internet than relationships between two people, and that relationships in which the group is trying to achieve a common goal (besides having a good time) are the most difficult to develop.
Groups that Never Meet
While it is certainly feasible for Internet collaborators to hold virtual meetings in a chat format or using audio or video conferencing software, these meetings rarely occur. It may be because of the difficulties involved in finding a convenient meeting time for group members who live in several different time zones. It may be because most Internet collaborators are volunteers who work on the collaborative project on their own time, or at work when their bosses aren't looking. It may be because it is so easy to communicate over the Internet without a meeting that we often forget the value of meetings. But periodic meetings can be valuable, even if they are virtual.
Meetings allow all present to focus on an issue simultaneously--to discuss it, to answer questions about it, and to resolve it. Yet, rarely does anyone in an Internet group get a sense that anything has been resolved. Discussions drag out over days, weeks, or months. If a decision has to be made, a vote is taken or someone makes an executive decision, but rarely do group members consider the decision to have long term consequences. The next time the issue is raised it is likely to be debated again as if it hadn't been previously discussed.
Part of the problem with not having meetings is that decision-making becomes a bursty, asynchronous process. Often someone will introduce an idea for consideration and then promptly leave town for a long weekend. By the time they get back their proposal has been misinterpreted in five different ways and a discussion is ensuing about an issue that the initiator never intended to propose. Eventually the initiator manages to get the debate back on track, and then, after a week or two, all debate stops. The initiator assumes that debate has ceased because there are no more objections to the proposal, and calls for a vote. A handful of votes trickle in, far less than a quorum. At this point nobody is quite sure whether people are not voting because they haven't been checking their e-mail, they don't really care about the issue in question, they don't have enough information to make up their minds, or they are opposed to the proposal and are hoping a quorum is never reached so that the issue won't get decided. Often the group doesn't actually have an official definition of a quorum and thus a debate ensues about whether the vote is binding.97
Security of Information on the Network
For collaboration to be successful, information must be easy to access--but ease of access compromises security. Intranets provide greater security than the Internet through the use of firewalls, servers that control access to the networks. Still, no network is absolutely secure, so companies judiciously select functions to move from the LAN to their Intranets.
The major source of flexibility in the WWW framework is the ability to tailor server and/or client behavior through the use of scripts and helper applications. Unfortunately, the features that provide this flexibility also have the potential to be misused by malicious clients and servers.
In particular, the issue of security must be addressed any time a command shell or interpreter is invoked by and passed data from a potentially untrusted source. This situation occurs when an untrusted client sends requests to a server, or a client receives responses from an untrusted server.98
Challenges to the Adoption of the Technology
Implementing any new system challenges the established patterns of people's working. Introducing collaborative technologies, especially on a broad scale, requires new behaviors as well as expectations.99
Online Privacy
The Internet, more than any other medium, has characteristics--architectural, economic, and social--that are uniquely supportive of democratic values. Because of its decentralized, open, and interactive nature, the Internet is the first electronic medium to allow every user to "publish" and engage in commerce. Users can reach and create communities of interest despite geographic, social, and political barriers. As the World Wide Web grows to fully support voice, data, and video, it will become in many respects a virtual "face-to-face" social and political milieu.
But while the First Amendment potential of the Internet is clear, and recognized by the Supreme Court, the impact of the Internet on individual privacy is less certain. Will the online environment erode individual privacy--building in national identifiers, tracking devices, and limits on autonomy? Or will it breathe new life into privacy--providing protections for individuals ' long held expectations of privacy?
As we move swiftly toward a world of electronic democracy, electronic commerce, and indeed electronic living, it is critical to construct a framework of privacy protection that fits with the unique opportunities and risks posed by the Internet. But as Congress has discovered in its attempts to regulate speech, this medium deserves its own analysis.
Laws developed to protect interests in other media should not be blindly imported. To create rules that map onto the Internet, we must fully understand the characteristics of the Internet and their implications for privacy protection. We must also have a shared understanding of what we mean by privacy. Finally we must assess how to best use the various tools we have for implementing policy--law, computer code, industry practices, and public education--to achieve the protections we seek.
Providing a web of privacy protection to data and communications as they flow along networks requires a unique combination of tools--legal, policy, technical, and self-regulatory. Cooperation among the business community and the nonprofit community is crucial. Whether it is setting limits on government access to personal information, ensuring that a new technology protects privacy, or developing legislation--none will happen without a forum for discussion, debate, and deliberation.100
COTS Analysis
The 1999 U.S. market for integrated collaborative environment software, commonly referred to as groupware, saw its three leading vendors in a close heat (within 1 million new users of one another) during the first calendar quarter of 1999. According to International Data Corporation (IDC) estimates, Microsoft Exchange took an early lead with 1.9 million new users, followed very closely by Lotus Domino/Notes with 1.4 million new users and Novell GroupWise with 1 million new users in the United States.
"A strong showing in Q1 after such a tremendous Q4 1998 defies traditional market wisdom," said Mark Levitt, research director of IDC's Collaborative Computing research program. "A key factor driving Q1 sales was Y2K. For organizations that had not yet replaced older e-mail and groupware solutions, the first quarter was the time for deploying Y2K-ready solutions. We expect Y2K to continue driving sales through the second quarter."
"Microsoft's bundling strategy with BackOffice and enterprise licensing puts Exchange in a strong position as we move into the rest of the year," said Ian Campbell, vice president of IDC's Collaborative Technologies group. "We expect Lotus to benefit from its shipment of Domino/Notes R5 in April, the only new product to ship in recent months, while Novell GroupWise will continue benefiting from the strength of NetWare 5.0. Overall, we expect the market to remain closely competitive among the top three vendors for the rest of the year. Within vertical markets, we expect a greater variation between these vendors."
These estimates may differ significantly from vendor reported numbers due to IDC's estimates including only licenses of software actually deployed by organizations for internal users in 1Q 1999, and not including licenses distributed but not actually used or licenses sold by these and other vendors to ISPs and other service providers to host subscribers.101
eShare Expressions Interaction Suite--a turnkey solution for adding chat, threaded discussion forums and online presentations to web sites. It enables organizations to promote community, collaboration and the kind of dynamic interaction that is crucial for commercial activity. Use it for virtual meetings, live training and conferencing, distance learning, moderated events, and social chat.
Web Crossing--offers threaded discussions, support for Live Events, Internet Tours, and a fully integrated chat feature are part of the latest version. Other new features include newsreader access and e-mail list archiving.
Abrio--Free Web calendar features individual calendaring, public or private group calendaring, task management tools, and a searchable event directory.
AOL Instant Messenger--chat software allows users to send private messages in real time, chat with multiple people, send and receive files via ftp, and keep track of friends using a "Buddy List."
ICQ--With ICQ, you can chat, send messages, files and URL's, play games, or just hang out with your fellow 'Netters' while still surfing the Net.
ichat--software for real time communications, instant messaging, online events, and bulletin boards
Lotus Domino--Download a demo of Lotus's messaging and web-application server platform. Learn about extension and small business products.
Lotus Notes--Communicate with colleagues, collaborate in teams, and coordinate business processes with Lotus's software.
Microsoft Exchange Server--Messaging and collaboration software includes security management and built-in SMP support.
Microsoft NetMeeting--delivers a complete Internet conferencing solution for all Windows users with multi-point data conferencing, text chat, whiteboard, and file transfer, as well as point-to-point audio and video. Read about how some leading businesses and educational institutions are using NetMeeting to save time and money and to increase productivity.
Microsoft MSN Messenger Service--is the Internet messaging service that provides you and your friends instant contact with the greatest number of Internet users and works with your favorite communications tools.
Netmedia--Software communications company provides intuitive e-mail tools. Includes a list of products, FAQs, and ordering information.
Netscape SuiteSpot--Netscape's content management, messaging, and collaboration suite is available in a standard and professional edition from the Netscape store.
Novell GroupWise--Software features e-mail, fax, calendar information, and task capabilities.
Ventana offers GroupSystems, a software suite with a fairly long list of collaborative features: Categorizer helps generate a list of ideas and supporting comments; Electronic Brainstorming distributes a question or issue to participants who then respond with comments; Group Outliner allows the group to create and comment on a multilevel list of topics; Topic Commenter offers participants the opportunity to comment on a list of topics; and Voting provides a variety of methods that help the group develop a consensus. Several add-ons for GroupSystems are also available102
ERoom, a feature-rich offering from Instinctive Technology, offers drag-and-drop file sharing, multithreaded and multi-topic discussions, real-time messaging, lists, polling, version control, data retrieval and enterprise-wide deployment.
FirstClass Intranet Server (FCIS) is SoftArc's open e-mail, collaboration, and Internet publishing server for business. Need more than just simple Internet mail, but don't want a complicated Microsoft or IBM solution? FCIS is a breakthrough all-in-one communications server that's extraordinarily easy to administer and use.
Multimedia Authoring
Technology Background
The computer is an extension of the mind, just as the wheel is an extension of the leg or the telephone an extension of the ear. Multimedia enhances this extension further by incorporating the sensory inputs of the mind, namely sound and visuals, which enriches the way we receive, store, retrieve, and interact with information. Any regular dictionary can tell us what an Oboe is and some even provide a small picture. A multimedia dictionary can do much better--we can actually get to listen to an oboe, watch the great oboe masters in action, and even get a hands-on tutorial session with a virtual oboe!
At the functional level multimedia is a digital integration of multiple media--text + pictures + animation + sound + video. What provides magic and meaning to this amalgam is interactivity, which lets the user interact with the material, to absorb multi-sensory information, to control the pace, to investigate and explore--thus transforming a passive recipient into an active participant.
Authoring
The components of multimedia are integrated into a composite application or program by using an authoring tool--software that integrates media and provides interactive control to the user. The author or a multimedia programmer has to coordinate the work of other members of the multimedia team--animators, graphic artists, audio/video professionals, and content specialists. The author need not be an expert in all these areas but must have a good grasp of the capabilities of the various media tools, along with an ability to understand design issues, and delivery technologies like CD-ROM, DVD-ROM, and the Internet. The author must also keep his eyes open for emerging technologies, file formats and new trends in interface design. Above all, the author must decide on the ideal authoring tool and the interface for the project in hand.
An authoring system is a program which has pre-programmed elements for the development of interactive multimedia software titles. Authoring systems vary widely in orientation, capabilities, and learning curve. There is no such thing (at this time) as a completely point-and-click automated authoring system; some knowledge of heuristic thinking and algorithm design is necessary. Whether you realize it or not, authoring is actually just a speeded-up form of programming; you don't need to know the intricacies of a programming language, or worse, an API, but you do need to understand how programs work.
The interface determines how the user will interact with the content. Creating the interface involves:
• Providing menus and buttons for content navigation.
• Letting users enter and retrieve data.
• Allowing interaction between multimedia applications and supporting applications.
• Providing facilities for printing and a neat way to control audio and video resources.
Zen of Interface Design
Bad multimedia is everywhere--content without focus, irritating interfaces, poor readability, an assault of fonts, terrible audio, distorted video, gaudy animation, and non-existent help, not to mention system crashes and installation blues.
Interface design strikes a fine balance between technology and aesthetics, structure and flexibility, form and function. Good interface design requires balanced creativity, good understanding of the objectives of the production, a passion for harmony, empathy, and compassion for the user.
The four elements of authoring:
• Create--Design, draw, paint, resize images, format text, crop, and trim audio/video.
• Import--Graphics, text, audio, video, and animation.
• Integrate--Sequence, link, sync, script, program, call other modules and share resources, and testing.
• Deliver--Burn CDs, host Websites, configure networks, etc.
Authoring Tools
Authoring programs are classified on the basis of how these tools organize, synchronize, sequence, store, retrieve, and deliver media elements. There are three types of authoring programs:
Timeline-based authoring tools, like Director, Astound and MediaBlitz, organize and present media elements and associated events along a timeline, thus allowing precise control and co-ordination of the when, where, how, and how long of media elements.
Page/screen-based systems, like Toolbook and Hypercard, employ the metaphor of a book, organized page by page or like a deck of reference cards. Content is distributed into related sets of pages or screens, indexed and linked--not unlike the Web pages of the Internet. Users can follow a link and branch off into different sections, view, search, bookmark, and print at their own pace and style.
Flow-line/Icon-based tools, like Authorware and Icon Author, take the visual programming approach to organize media and events. These tools present a flow chart of events and media. Authoring is just a matter of dragging and dropping the appropriate icons along a flowline. Once the organizing is complete, the icons can be customized to suit production requirements. Icon-based systems make rapid application development possible in multimedia with flexibility to update and incorporate (a thousand) last minute changes.
Which Software?
All authoring tools have their bright spots and weak spots, and no single tool is comprehensive enough to stand up to all the possibilities, requirements, and demands of creative multimedia. Selection starts by stating the purpose: Is the application meant for a business presentation, training, gaming, or reference?
Other factors are the level of authoring expertise, the efficiency of team members, complexity of the content and interface design. Last, but not the least, come the issues of budget and deadline.
A corporate presentation with plenty of graphs and charts is best done in Astound; a promotional piece with sizzling animation and sound sync is old hat to Director; a training program is best done in Authorware or Toolbook.
Although most packages allow you to create content using their built-in tools, these tend to be rudimentary when compared with those available in dedicated programs. For more professional output, you should use software dedicated to the creation and editing of that medium, and then import/integrate the content into your multimedia program.
Major content-development packages are likely to include:
• Paint programs for still images (photos, original digital artwork).
• Illustration (draw) programs for still images (modeled and rendered objects).
• Video digitizing/editing programs.
Scripting
Scripting is the authoring method closest in form to traditional programming. The paradigm is that of a programming language, which specifies (by filename) multimedia elements, sequencing, hotspots, synchronization, etc. A powerful, object-oriented scripting language is usually the centerpiece of such a system; in-program editing of elements (still graphics, video, audio, etc.) tends to be minimal or non-existent. Scripting languages do vary; check out how much the language is object-based or object-oriented. The scripting paradigm tends to be longer in development time (it takes longer to code an individual interaction), but generally more powerful interactivity is possible. Since most scripting languages are interpreted, instead of compiled, the runtime speed gains over other authoring methods are minimal. The media handling can vary widely so, check out your system with your contributing package formats carefully.
Some authoring tools allow incorporation of external program controls like VBX controls in Toolbook, providing the power and flexibility of Visual Basic to the program, and Authorware allows Active-X controls, which enhance its Web functionality. Apart from these, custom coding done in any regular programming language like C++ can be simply plugged into the multimedia program.103
Role of Graphic Files
Graphic files fulfill several different functions (some formats fill more than one role).
• Image storage--The most basic function is image storage . This is characteristic of bitmapped formats, which store the image as a bit level representation. In object graphics formats, what is stored is a specification of the image as a set of primitives, each with associated properties (color, line type, fill, etc.)
• Scene storage--In 3D applications, files are used to store the objects that make up a renderable scene, as well as the "environment" of the scene (notably the camera location/viewpoint).
• Interchange--Some files formats are designed specifically to facilitate the transfer of images/scenes between different applications and/or platforms. These are known as interchange formats, and most are metafiles (defined later).
Efficiency vs. Portability
When defining a graphic file format there is a single basic "equation" to be worked out. On the one hand, there is an understandable urge to create a format that is extremely efficient, so that the resulting files are as small as possible. However, this may limit the ability of the files to be moved to another platform, or to be read by another application. (This problem is exacerbated if the file format is proprietary.) Most developers have adopted different approaches:
• Take advantage of available metafile formats (or create a new one).
• Use "filters" that allow the import and export of files in different formats.
Types of Graphic Files
There are a large number of different image formats--almost as many as there are different applications. However, putting aside for the moment the creation and format of video and animation, we can split all computer-generated images and the software used to create and manipulate them into two categories: bitmapped images and systems and object-oriented (also called vector ) images and systems. Bitmapped images are drawn with paint programs or created by scanners. Object-oriented graphics are drawn with illustration software, CAD programs, and the like.
When bitmapped images are stored, the file structure that is used directly reflects their bitmapped origin. (We call all specifications for defining how images are to be stored outside a graphics program as graphics file formats , or just file formats . All applications areas, such as word processing, databases, and spreadsheets, have a diversity of file formats, but none have anything like the variety of formats as computer graphics.)
In general, bitmapped files have two sections (within a single image file). The first section--the header-- contains "meta-information" about the image, including:
• The resolution (image size).
• The number of colors (color depth).
• The structure of the palette.
• The compression method (if relevant).
The second section--the body-- contains the data that makes up the actual image. The structure of this section in particular is almost endlessly adjustable, and devising different ways to better organize the data is a major contributor to the variety of bitmap file formats.
Two specific points need to be emphasized about bitmapped graphics files. The first is, that being scale-dependent, they do not scale effectively. This means that changing the size of the image when it is displayed will invariably produce undesirable visual effects. This is true of reducing the size but is most noticeable when increasing the size. The necessary process of generating "new" pixels generates artifacts, or "jaggles," by interpolating between the original ones.
The other general point that needs to be made about bitmapped files concerns their size. Just as large amounts of memory are needed for the internal representation of these images, so the external versions are also (at least potentially) very large. A 24-bit image in its "raw" form at 800 by 600 resolution will occupy 1.3 megabytes, but because of its header, it will actually be slightly larger than the equivalent internal representation.
There is, however, one important difference between the internal and external representations: the internal version has to be in "full" form, but the external version need not be. In other words, the internal version has to be complete, that is every pixel must be included to its full bit depth (assuming there is enough memory). But such images often include considerable redundancy-- large portions of an image may be repetitive. This may be only on a bit-by-bit level (adjacent pixels have the same "color"), but it may also appear at larger scales (repeated "blocks" of the same color, perhaps of different sizes). An extreme example would be a small yellow sun in the center of a sky of a constant blue.
Numerous methods have been developed to minimize the size of images (or any electronic file) by identifying the redundancy structures (if any) and compressing the file to remove them. Depending on the actual image, this can produce significant size reductions, but complex images will still produce large files.
The external storage of images by object-oriented graphics systems reflects the way in which objects are manipulated just as clearly as do bitmapped files formats, and with almost as great a diversity of choices. Here all that needs to be stored is the set of objects that make up the image, and their attributes. With geometric objects (and any combinations of them) this is likely to be a small set of numbers that define the objects' sizes and locations, and a set of codes (part of the file specification) for their attributes. Consequently, these files contain minimum redundancy and, as they are usually stored in binary code format, there is usually little benefit in compressing them. Like bitmap files, vector graphics file formats combine the header and the image data within the same file.
Metafiles
There is a third category of image files that are not directly related to any particular application type, but whose origin and purpose need to be understood, namely the metafile . In principle a metafile can contain either bitmap or vector data, or both. In practice the two most widely-used metafiles formats--the Computer Graphics Metafile (CGM) and the Windows Metafile (WMF) in Microsoft Windows--are used to store vector images.
Metafiles were proposed in the 1970s as a way of dealing with the problem (evident even then) of the device-dependence of most image file formats. The idea was to define a "super" format that could encompass the needs of many similar, but different existing formats. When required (as in moving images between platforms), the metafile would be used to provide an independent medium of interchange.
One of the major problems with persuading software designers to incorporate metafile support has been the relative complexity of such formats. In order to be able to deal with many different formats the metafile specification has to be much more complex ("richer") than that of a single format. This means that software to read and write metafiles is complex and hard to write (the WMF is an exception, as support for it is included in Windows development systems) and the resulting files tend to be larger and more difficult to handle.
The other major problem with creating effective metafile specifications has been the difference in the pace of development between the commercial computing world and the process by which international standards are formulated and ratified. It took nearly a decade to develop and ratify the CGM format, by which time a new "generation" of formats had been created in the PC and Macintosh arena that the CGM format could not deal with.
As worthwhile as standards are, the reality will probably always be that computer-generated images come in many different formats. As Murray and Vanryper note "...file formats never die...." As long as images in "old" formats are being used (even if the software that was used to create them has disappeared) the format will live on.
Major File Formats
MacPaint. Most of the graphics formats that have originated on the Apple Macintosh are to some extent device-dependent. MacPaint, for example, was originally a black-and-white and fixed resolution (576 × 720) format: the specification of all Macintosh display systems up to the introduction of the high-resolution color displays in the Macintosh II in 1988.
PCX. The PCX format was developed in the early 1980s by Zsoft for their PC Paintbrush program, which became popular when it was "bundled" with Microsoft mice, and later with Windows. It uses a basic RLE compression system, so its compression is not particularly efficient. It is also internally organized to be most effective on display systems (like the IBM EGA and VGA adapters) that support pixel planes. Although later versions of the specification have been extended to include support for 24-bit images, it is rarely used for storing these (JPEG or TIFF are used instead).
BMP. The Microsoft Windows Bitmap was derived from the MSP file format of the (black and white) Paint program in the earlier versions of Windows. It shares many of the characteristics (both good and bad) of the PCX format: simple RLE compression, late addition of 24-bit support, and some degree of device-dependence. Supported by all Windows development environments, it is universally used (often in conjunction with other formats) as a sort of "lowest common denominator" by Windows applications. A device-independent extension (the D evice I ndependent B itmap, or DIB) has been much less widely adopted.
GIF. The G raphics I nterchange F ormat was designed for efficient storage and transmitting of images on the commercial CompuServe network. As such, a key design aim was minimum size (to minimize transmission time and hence cost) and LZW compression is always used. Originally limited to a maximum resolution of 320 × 200, the format was expanded to cover an almost-indefinite size range (actually up to 64K × 64K). The major limitation remains its lack of color depth; it stores only 8 bits per pixel, so is limited to a maximum of 256 (albeit selectable) colors. It is probably the most widely used of all graphic formats. In recent years it has received something of a new lease on life as one of the two file formats (the other being JPEG) used on Web pages.
TIFF. Reflecting the specific problems associated with managing scanned images, Aldus created the T ag I mage F ile F ormat (TIFF) in 1986 and, in cooperation with Microsoft, have continued to develop it since then. Initially aimed at black and white scanned images, the format was designed to be extensible, and now supports color depths up to 24-bits. Unusually, the format allows multiple compression systems to be used, depending on the circumstances. This makes it arguably the most flexible of all bitmapped formats and, consequently, one of the most common. Its lack of device-dependence means that it is found on all platforms.
TGA. Originally developed as a "local" file storage format for the Truevision Targa-Vista and NuVista video capture and display boards, the format is still used in high-end rendering systems and in still-video editing. The format allows for color-depth up to 32-bits, but uses only RLE compression. Linked to the original Truevision hardware, the format is to some extent device-dependent, but this is rarely a problem. It is worth noting that it is not used much in the Macintosh environment, but the same is true of most other formats that originated on Intel-based PCs.
Kodak Photo CD. The Photo CD format was invented by Kodak as part of its Photo CD-ROM image storage system, in which photographs (slides or prints) are digitized and written onto a CD-ROM. This can be done in a series of separate write operations (unlike other CD-ROMs), requiring a multi-session CD-ROM player to retrieve the images. The format is proprietary and unpublished, but Kodak supplies a development kit that can be used to incorporate Photo CD support into applications. The major attraction is that all images are 24-bit; the maximum size of "only" 2048 by 3072 is not usually a limitation. The format is used primarily for distributing large-scale photographic images for use in presentation and display applications.
JPEG. The JPEG format was developed to facilitate lossy compression (see below) of large images (up to 64K by 64K) with high color depth (24-bits). The system does not actually define a file format (that is, how the compressed data should be written into a disk file). An extension to the basic specification (the J PEG F ile I nterchange F ormat, or JFIF) was created for this purpose.
Object-Oriented (Vector) Images
Most vector graphics formats are proprietary and designed to work with a specific application. For example the CorelDraw CDR format was created by Corel Corporation to store images created by their program, and the company has changed the format as they feel appropriate as the program has developed. Other systems can choose to support the format, but it is essentially "local" to CorelDraw. The same situation applies to the majority of object-oriented graphics systems; any need to interchange data with other systems is handled either by the program having the ability to read and write ("import" and "export") other formats, or the use of a metafile.
HPGL. The H ewlett- P ackard G raphics L anguage is less a file format (although "images" can be said to be stored in this form) than a plotter control language. As such, it has parallels with modern Page Description Languages (such as Adobe's Postscript and Hewlett-Packard's own PDL) that are used to define output to laser printers. HPGL is built from a set of plotter control commands ("pen down," "pen up," "move to point (3427,721)," "pick up pen 5"). While it includes commands that can define "solid" components (using various fill patterns), it is at its most useful when used with images that are made up mostly of lines.
PICT. The Macintosh Picture (PICT) format has some parallels with the older pen plotter control languages (such as HPGL and the venerable Plot10) and the newer Page Description Languages in that it describes an image by the QuickDraw commands that would be required to generate the image on a Macintosh screen. (QuickDraw is the Macintosh internal screen generation "graphics language," and is part of the Macintosh ROM.)
Interchange and Metafile Formats
EPSF. As the desktop publishing market developed on PCs in the mid-1980s, and the laser printer became widely used, Postscript became the most commonly used PDL in this environment. However, given its origins, Postscript is unsuitable as a means of transferring documents (combining text and images) between applications and platforms. To deal with this Adobe developed the E ncapsulated P ost s cript (EPS) format. EPS files include a Postscript description of a "page," and a low-resolution bitmap that can be used to represent the "page" when incorporated into other documents (or shown on a different, non-Postscript display system).
CGM. Designed by a group representing the International Standards Organization (ISO) and the American National Standards Institute (ANSI), the Computer Graphics metafile (CGM) was intended to be a platform-independent format for interchange of vector and bitmap images between different systems. The bitmap capacity is so rarely used that is effectively irrelevant; it was strongly linked to the raster "object" found in GKS (the G raphical K ernel S ystem), the standard graphics programming library of the early 1980s. Today, the CGM format is invariably used with object-oriented images.
Like other "true" metafiles (which excludes, for example, the Windows-based WMF), the CGM specification is complex and rich, which means it needs to support a large number of primitives and attributes in order to be useful in various environments. Unfortunately, this means systems that write CGM usually employ only a subset of the system, and systems reading them can't always be sure what this subset includes. This sometimes results in changes to colors, line styles, or fonts when an image is saved in CGM format and read into a different application.
DXF. The first major PC-based graphics application to have wide commercial currency was Autodesk's CAD program AutoCAD, and it remains the dominant software in its field (at least on PCs). Because CAD systems already existed on workstations (and to some extent on larger machines), Autodesk needed to define an image format for storing CAD drawings that also facilitated file interchange between PCs and other systems. The D rawing E x change F ormat (DXF)--and its binary version, DXB--was created to achieve this. Despite it limitations (notably its complexity) the dominance of AutoCAD has ensured the widespread adoption of this format, obviously among CAD software but also by other object-oriented systems.
WMF. While developed for, and to some extent device-dependent with, Microsoft Windows, the enormous popularity of Windows has led to the W indows M etafile F ormat (WMF) being widely used outside the Windows system. Like CGM it supports both vector and bitmap data, but is rarely used for storing the latter. The system has some features in common with PICT, in that an image is encoded (in binary form) as a series of "instructions" for generating the image on a screen using the Windows Graphical Device Interface (roughly equivalent to QuickDraw in the Macintosh system). Using the resulting files on other platforms requires a "mapping" between the GDI and the host's graphic system; this is not too difficult to do on any system that can create on-screen graphics by an equivalent system (such as the Macintosh and X-Windows).
IGES. Somewhat like CGM, the I nitial G raphics E xchange S pecification (IGES) was designed by a group of graphics organizations (led by the American National Computer Graphics Association) as an interchange format for graphic images that needed to be transferred across networks. The design was dominated by certain characteristics of the networks of the early 1980s, particularly their low bandwidth. This, combined with the fact that the specification is only available to members of certain groups (affiliated with NCGA) has limited its acceptance, despite its technical merits.
FLI, FLC. Autodesk's Animator, the first low-cost, widely-used non-professional 2D animation system used a file format that was device-dependent, as it was based on inter-frame coherency between a series of GIF images, each up to 320 by 200 by 256 colors. The resulting format (FLI) has become widely used, particularly for animation and image morphing on Intel-based PCs. The format has been extended to much larger resolutions (up to 64K by 64K) and greater color depth in the newer FLC format.
QuickTime. QuickTime is the basis for storing (and playing) all forms of motion video and sound on Apple Macintosh systems. It combines a storage format with tools for creating, editing, and playing video. It is a highly flexible format that allows the storage of multiple audio and video tracks in the same file and supports a variety of compression techniques.
Versions of the system are also available for Microsoft Windows, but on non-Macintosh systems the basic QuickTime movies (at least, all those actually created on a Macintosh) have to be "flattened." This involves removing the resource fork that is part of all Macintosh files (the other part is the data fork , which contains the "real data") which is not understood by other systems.
AVI. Microsoft's multimedia support in Windows is based on an extensible set of specifications called the R esource I nterchange F ile F ormat (RIFF). This includes support for sound data in two formats: waveform (general audio) with the WAV format, and MIDI (music) with the RMI format. Video/audio support is provided by the A udio/ V ideo I nterleaved (AVI) format, as implemented in the Video for Windows (VfW) extension to the Windows Media Player. As with QuickTime, the VfW system is a combination of a multimedia file format (AVI) and a "toolkit" for creating and editing such data.
MPEG. The development of the Moving P icture E xperts G roup (MPEG) matches that of the JPEG group, but with a few years time lag. The MPEG specification was designed for efficient storage of compressed audio and video data, specifically on CD and Digital Audio Tape (DAT). (The newer MPEG-2 specification deals with transmission of such data across television and cable networks.)
MPEG-encoded sequences can be displayed with standard hardware, however, the algorithms involved are most effective when used with specialized hardware, usually in the form of an add-in board for a PC or (more rarely) a Macintosh. The system is tied to existing television standards, so has to support the three major television formats, namely NTSC, PAL, and SECAM. It is expected that the specification will change over time to encompass new television standards as systems such as high-definition television (HDTV) are developed and adopted.
Image Compression
The problem of graphics image size is an escalating one. The enormous volume of image data generated by satellites and space probesand the time taken to transmit them back to Earth in "raw" formhas led NASA, for example, to underwrite significant research into the development of improved compression techniques. On a smaller and more local scale, the availability of inexpensive, high-quality (especially TrueColor) scanners is leading to the rapid generation of huge numbers of large images that have to be stored and manipulated. Image compression has come to be seen as at least one part of the answer.
Generally speaking, compression is the process of transforming raw data (in binary form) to compressed (or encoded) format, the resulting data being somewhat smaller than the original. The ratio between the two sizes is called the compression ratio; if the original is 200 kilobytes, and the compressed is 50 kilobytes, then we say a compression ratio of 4:1 has been achieved.
Most compression systems are symmetric, in that the same algorithm that is used to compress the data is used "in reverse" to uncompress it.
JPEG. The public domain system for lossy compression was created by a group that grew out of recognition of the need for improved formats for the electronic transmission of color and gray-scale data, particularly by facsimile. Out of this came the Joint Photographic Experts Group (JPEG), who in turn created the JPEG compression process, made it publicly available, and continue to develop it. The group includes industry representatives but is essentially an international standards organization.
Fractal Image Format. The proprietary method of lossy compression is based on the mathematical systems called fractals that have aroused considerable public interest in recent years. A group based at the Georgia Institute of Technology developed a new type of fractal that they called iterated function systems (IFS). Among other things, these fractals have the property of being able to reduce complex objects (notably bitmap images) to a small number of fractal parameters which, when "run through" the proprietary algorithm, will re-produce the original image. Using them, one can reduce an image of several megabytes to a few kilobytes of fractal parameters. As with JPEG, the smaller the compressed image in IFS format, the greater the loss of image quality. Again, the trade-off is left to the user. To make this system more attractive to users (speed is a problem) it can be implemented on a PC add-in board, which greatly increases the algorithm's speed at relatively modest cost.104
The Art of Editing
Editing is like the grammar of this language--the language of the moving image. Editing concerns itself with the connection of shots. Each shot is like a word in a sentence, and editing is the structural "glue" that holds them together.
Sewing is actually a very good analogy for video editing, because in many respects your main goal is to hide the seams--to make the edits look invisible. In the aesthetic of traditional, Hollywood-style editing (as opposed to experimental/avant garde editing, which often takes the opposite direction), anything that makes the viewer more aware that an edit occurred is considered bad, while anything that distracts the viewers from the edit by getting them interested in the new shot is considered good.
Linear Editing
Linear editing systems are hardware-based and require edits to be made in a linear fashion; i.e., in a 1-2-3 sequence. In a typical project this would mean that you would start by editing in the countdown leader, followed by scene one, followed by scene two, etc.
This type of editing can be likened to writing a term paper with a typewriter (remember typewriters?). You must have your material well organized before you start, because once committed to paper, changes are difficult to make. As we will see, non-linear editing is more like working with a sophisticated word processor.
The concept behind linear editing is simple: one or more tapes containing the original footage are transferred (recorded) segment by segment onto a tape in a video recorder. In the process, the original segments can be shortened and rearranged, bad shots can be removed, and audio and video effects can be added.
The source machine(s) contain the original footage and the edit recorder, which is controlled by an edit controller, is used to record the final edited master. (A lot of terms here, but they make sense, if you think about it.) The person doing the editing uses the edit controller to shuttle tapes back and forth to find the beginning and ending points of each needed segment. These reference points are then entered as either control track marks or time code numbers. You then turn things over to the edit controller, which uses the precise beginning and ending points you've entered, to roll and cue the tapes and make each edit.
In simple linear editing systems the in and out points are referenced by pulses recorded on the tape30 per second in NTSC video. The method of editing that locates and marks segments based on a count of control track pulses is referred to as control track editing.
Control track editing has two major shortcomings. First, it relies on equipment to maintain an accurate count of thousands of control track pulses. For basically mechanical devices this can be difficult. During editing you are constantly shuttling tapes forward and backward at varying speeds as you find and mark in and out points for edits. If equipment loses count just for a fraction of a second an edit point will end up being off by a few video frameswhich will destroy a carefully timed edit.
Savvy editors keep an eye on the digital tape counter as tapes are shuttled back and forth. If the counter freezes for a split second when the tape is moving, the equipment has momentarily lost an accurate count of control pulses. Problems generally come down to either less-than-perfect videotapes or a less-than-perfect control track.
The second disadvantage of control track editing relates to the ability to replicate (and make adjustments to) your original edit decisions at a later time. Since the control track count is kept in the volatile memory of computer chips, when the machine is turned off or reset, all edit decision information is lost. Since these counter references on control track editing systems are "relative" (to where you started the counter) and not "absolute" (i.e., recorded on the tape itself) they do not remain accurate when tapes are changed, etc.
The only way to insure accuracy is when the exact locations on the tape become permanent information on the tape. This is possible with SMPTE time code. When time code is used exact scene locations remain consistent--even when tapes are used in different machines at different times.
As you can see, control track editing has a number of shortcomings. Even so, it remains the quickest way to assemble (edit) a simple video project.
There are two types of edits you can make in linear editing.
When you use assemble editing you add video and audio segments, one after another like links on a chain, complete with the associated control track. As we've noted, the control track is difficult to record with unerring precision with each and every edit. Any mistiming during this basically mechanical process results in a glitch in the video. For this reason, assemble editing is not the preferred approach. It's used primarily when a few segments need to be spliced together in a hurry.
Insert editing requires an extra step; you first must "lay down" (record) a stable control track over the entire area of the edited master tape you plan to use. If you think that your final project will be five minutes, you record six or more minutes (just to be sure) of a video signal (generally just black). You then have a consistent (uninterrupted) control track on your final tape that should translate into a stable playback. During editing, you "insert" the video and audio segments you want into areas represented by the pre-recorded control track. Since you are not trying to record a new control track as you add each video segment, the process results in a more stable playback.
Within the time constraints of whatever audio and video has been recorded on the edited master, it's also possible to insert (substitute) new video and audio at a later time. It's not possible, however, to lengthen or shorten parts of the edited master, something you can easily do with non-linear editing.105
Non-Linear Editing
Non-linear editing involves transferring all the raw video to a computer hard drive, and then editing the video with computer software in much the same way that a word processor edits text. The clips can be inserted into the sequence at any point during the edit in a non-linear fashion, and so the non-linear edit suites are ideal for creative video editing. At the professional level, the most well known systems are the Avid, Data Translation, and Video Toaster Flyerbut these cost upwards of $15,000. You can experiment with non-linear editing on a lower budget, using software such as Adobe Premiere (available for both Windows and Mac) along with a video input board (such as the Video Spigot), but note that the picture quality won't be nearly as good, using low-budget non-linear editing, as if you used traditional videotape-based editing equipment.106
Design Issues
In the past, selecting a nonlinear editing system was just a question of evaluating just a few parameters. Turnkey, black-box systems were primarily bought on the basis of image quality with some simple functional criteria (like EDL support and batch digitizing) thrown in.
Now that most nonlinear systems exceed the data rate requirements needed for transparency and have more functionality than any A/B roll suite ever had, choosing a system has gotten a little more complicated.
First of all, nonlinear systems don't just edit video any more: They're compositing machines which take a variety of media: animations, stills, video, etc. and layer/edit them with considerable sophistication. And the output isn't just to videotape: Users also want interactive CD-ROMs, video, and stills for Web pages and even hard-copy paper output made from the same media. Finally, these systems are no longer isolated digital islands of production technology in an analog sea: They're multimedia computers, which need to interface with existing applications, networks, and workflows.
Editing systems also don't come in a single box anymore. Like the radio that grew up into a stereo, nonlinear software and hardware components are mixed and matched from a dizzying array of possibilities.
Some users want to edit video, plain and simple. For this, the ability to play back edits immediately so that timing can be checked is critical. For those who want to load lots of footage onto the machine and make decisions during the editing process, the ability to batch digitize is important. They can load lots of low-data-rate video into the computer during the weeding-out stage, then batch digitize the stuff they need for the final edit in at a higher quality.
Another issue for video editors is what signal types the system supports. Just about all systems can handle composite and Y/C, and many of them can handle component Betacam. But few can handle serial digital video, and none can currently input/output the new DV format in native form, although that's likely to change soon. Some users may want to be able to edit in PAL, the European TV standard.
A lot of nonlinear users want to do extensive amounts of special effects. Here, the ability to see them in real time makes the creative process a lot faster. But special hardware is required and the software has to be able to use it.
Many nonlinear system users are incorporating large amounts of animation, this introduces a number of issues. If the animations are of a technical nature, such as 3-D models of machinery or buildings, a great deal of time can be saved if the animation package can use the CAD files that are often used to design these objects to create the 3D animated models. Only a limited number of packages can do this, which in turn affects nonlinear editing package selection, since it's important that the animation and nonlinear hardware be maximally compatible.
Long, complex video edits need the ability to database clips and sequences. That way, one can sort and flag clips according to various criteria as well as arrange them into storyboards. Some applications allow you to save completed sequences as clips, which you can then cut-and-paste into larger units while still retaining the ability to modify them. Database management functions which allow you to move media around (for example, to put stock footage into special folders) and to automatically delete all footage that isn't in use is very handy and goes a long way towards preventing crippling user mistakes.
Multimedia
CD-ROM and Website creation has a wholly different set of requirements. Image quality is much less important, the ability to export the appropriate file format is crucial. This is not just an issue of having both Video-for-Windows (.AVI) and QuickTime (.MOV), but of having the appropriate compression algorithms and the ability to set things like data rates and sector padding so they play smoothly on whatever hardware they're supposed to work on. Otherwise, you may have to go through lots of file-format acrobatics to get what you need, which can be very time and disk-space consuming.
Few nonlinear editing systems can export MPEG files. Although viewers need special MPEG playback hardware in their computers, it's currently the only way to get VHS-quality video playback off a CD-ROM. Some nonlinear applications (like Avid MCXpress for NT) have MPEG exporting built into them, others can interface with separate software encoders. But software MPEG compression is very time-consuming, therefore, a lot of users get specialized hardware that can do it in real-time.
All these multimedia files have a problem with long blanking times. There is no CRT frame to hide the black edge around the image. Nonlinear editing packages used for multimedia production need to be able to trim this off.
Reliability is a big issue with all CD-ROMs. A large proportion of them is returned, the main reason is that they don't work in the particular customer's computer. It pays to develop CDs on the same platform as it will be played onæit's easier to debug when you can constantly try it out.
A lot of nonlinear users want hard-copy paper stills of some of the material, either for packaging, user-guides, or publicity. This requires much greater image quality than is normally used for video, and the different proportions of the printed page create layout problems for artists who want to reuse video-oriented graphics on printed matter. In these situations, nonlinear systems not only need to be able to handle desktop-publishing file formats, as much of the artwork as possible needs to be made with high-quality bitmaps or vector-based object-oriented elements that can be easily rearranged for different proportions and resized for the varying resolutions of video and print. For full-page stills, it may be necessary to scan photographic film images into the system with a high-resolution scanner. Hi-res output is also an issue, the files are usually way too big to fit on a floppy and may need to be carried to the imaging station on special media, such as a Zip or Jazz drive.
Film
Many people are surprised to learn that the video-image-quality of film-editing nonlinear editors can be pretty poor. The reason is that the film negative will be used to make the prints and the video display is merely for editing purposes. Film runs at 24 frames/second as opposed to 30 frames/second for video, so special provision has to be made to accommodate this. In addition, film uses edge numbers rather than SMPTE timecode to keep track of frames, therefore, the editing application needs to be able to calculate these from the SMPTE timecode on the video transfer. Other necessary features are the ability to generate a list of all footage that is used more than once (so that an inter-negative can be made) as well as all optical effects. A separate SMPTE timecode edit list is usually required for the audio cut.
Representative Authoring Systems
(This list is not meant to be exhaustive, merely illustrative of what is currently available at various levels of performance.)
For the Hobbyist
Adobe Premiere. I'll say it right here: Premiere can do more than any other nonlinear program out there: More video tracks, audio tracks, effects, filters, etc. than anyone else. It's also the only fully open-system application on the market: It runs on any hardware that supports Video-for-Windows or Quicktime. But everything, absolutely everything is done in software, including playback of Video-for-Windows and QuickTime files, and this makes for some big inconveniences. Most serious is the need to render out a file of the complete program before smooth playback can take place on most hardware. This can take hours, even days, for a half-hour program! The only capture/playback card that doesn't suffer from this limitation is the Interactive Images Plum card, which is strongly recommended for anyone who wants to edit video with Premiere. A complete system (including computer) can be assembled for $7,000 and up, and it'll do a lot. The main limitation is that the system can only handle composite and Y/C video and is limited to data rates of about 180KB/frame.
But if you're doing multimedia production, Premiere really shines and the rendering requirement isn't as onerous. All multimedia files need to be rendered anyway and Premiere can export more file types and gives you more control over their settings than most other applications. The only file type it can't export is MPEG. Many people with more expensive systems have a copy of Premiere on their system to handle multimedia stuffit's that useful. And Premiere comes in both Mac and PC versions.
For the Corporate/Online Producer
Avid MCXpress. This little-known program is perfect for the mid-range video editor who wants high image quality and a quick, efficient interface. The NT version actually has the highest data rate capability of ALL Avid products (over 330KB/frame), and it runs on a variety of capture hardware. When used with the Truevision Targa 2000RTX, some two-channel effects like dissolves, picture-in-picture, and keys can take place in real time. This is a real boon because these are the effects that typically take longest to render: dissolves because they're so common, keys and picture-in-picture because the durations tend to be longer than a second or two. MCXpress has pretty decent databasing capabilities including keyword search, sequence storage, storyboarding, and unused-footage elimination. The object-based character-generator (Inscriber) is something of a standard in the industry. A very object-oriented package with the ability to precisely position titles over video, etc. The NT version of MCXpress runs on a variety of boards and even comes with an MPEG encoder. Complete systems cost from $15,000 on up.
For Real-Time Special Effects
Scitex Videosphere. Scitex makes unique nonlinear systems that have a substantial amount of special real-time effects hardware. They can do a variety of DVE, chromakey, color-correction, and other effects in real time with a very interactive, real-time interface that makes adjustment easy and intuitive. Midrange systems run in the $40,000 to $45,000 range.
For Top-of-the-Line Post Facilities
Avid Media Composer 8000. This is Avid's top-of-the-line machine and has all sorts of bells and whistles. Among them: full range of film, video, and audio-editing tools, a real-time multicamera play option that's handy for editing TV shows, lots of interactivity, audio EQ, lots of real-time effects, and more. But it's expensive, about $150,000 for a system.
Film
People are often surprised to find out that film-based nonlinear editing systems are not only cheap, they hold lots of media! That's mainly because the image quality isn't very important and the image can be highly compressed. There are three main systems in use, the Lightworks and Avid high-end applications, and the D-Vision PRO, which generates not only film/audio cut lists, but also video EDL's that were found to be rock-solid reliable. It starts at the amazingly low price of $7,000!
Other Add-Ons
Today's open-system designs allow for lots of extra tools on nonlinear systems, many of which you are likely to have heard of or be familiar with:
Adobe PhotoShop--PhotoShop is a general-purpose paint/processing program. It's not only useful for generating graphics, it's also indispensable for color-correction of stills. There are very few prints and slides that can't do with a little improvement in PhotoShop, not only to remove dust and scratches, but also to make the colors more vibrant, reduce contrast (video can't reproduce photo contrasts) and compensate for color differences between images.
CorelDraw--This is a vector-based drawing package. Unlike PhotoShop "bitmap" images, which are stored as pixels and have built-in resolution, CorelDraw "vector-based" images are stored as shape algorithms and can be enlarged indefinitely without any loss of detail or smoothness. The individual elements can be rearranged and resized as desired without any loss of quality. This makes CorelDraw ideal for graphics that will exist in multiple versions or be repurposed in print.
CorelDraw also comes with a large library of clip-art (such as models of people, animals, symbols, etc.) and an automatic chart-making function that you only need to type data into and it will automatically draw pies, bars, and graphs to the appropriate dimensions.
QFX--This is a video-oriented package with the paint and image-processing capability of PhotoShop and the drawing capability of CorelDraw. The main attraction is the queuing, which allows you to have the program memorize a series of steps and then perform them over and over. A typical application would be to take a few hundred PhotoCD images with black edges on them (a common occurrence) and to automatically crop them and save the images on the computer drive. Just the savings in labor alone on a job like that is enough to pay for the program many times over.
Animator PRO and Studio--These programs produce Bugs-Bunny-type of 2-D animations. Animator PRO is the DOS version and has a limit of 256 colors. Animator Studio, the Windows version, can handle sound, but is a little slower. Although these programs are very simple, a surprising amount of work is being generated on them, for example, Dr. Katz, Professional Therapist, which runs on Comedy Central and is made in Boston by Tom Snyder Productions, is made with Animator PRO and edited on Avid MCXpress.
3D Max--This and its DOS version, 3D-Studio, is the standard in 3D animation. (More people use this application than Alias, Wavefront, and SoftImage combined). Its strength is the sophisticated modeling tools that allow you to make complicated shapes quickly and easily. It can also be used to animate humanoid forms as well as import designs from CAD packages like AutoCAD. It's a complicated package, though, and takes a while to learn.
There are really two options on CD distribution: To make an interactive program or to use HTML and allow people to browse the CD with Netscape or a similar browser. Many word processors allow you to generate HTML scripts, but to generate more sophisticated presentations, one needs a program like MacroMedia Director. This not only allows you to position and animate a variety of objects, one can also make all of them sensitive to mouse clicks that can send the user to another part of the CD. Interactive presentations are often the best way to present reference material or lots of information that not everyone will want (or be able) to sit through at any one time. Users can click their way through the topics that interest them and leave the rest for later.107
Markup Languages
Markup languages have been with us for a long time. The term markup comes from the printing and publishing industries. In order to turn plain text into a final printed product complete with bold, italics, different typefaces, headings, structured tables, and so on, editors marked up copy with standard notations telling the typesetter how to format each element on the page.
A markup language is a set of rules for adding formatting instructions (copyeditor "marks") to text so that a typesetter can create an easily read document. It gives the author control over the logical structure of a document. The marks explain which bits of text belong together, which bits are titles and headers, which are lists, and which bits need emphasis for various reasons. The typesetter chooses the actual fonts, the spacing, the margins, etc. to conform to the publisher's guidelines for appearance and to produce a document whose appearance assists the reader in comprehension.108
HTML
As far back as the 1960s, IBM scientists were working on a generalized markup language (GML) for describing documents and their formatting. In 1986, the International Standards Organization (ISO) adopted a version of this standard called standard generalized markup language (SGML). SGML offers a highly sophisticated system for marking up documents so that their appearance is independent of specific software applications. It is big, powerful, filled with options, and well suited for large organizations that need exacting document standards.
But early in the game, it became apparent that SGML's sophistication made the language quite unsuitable for quick and easy Web publishing. For that, we needed a simplified markup system, one at which practically anyone could quickly gain proficiency. Enter hypertext markup language (HTML), which is little more than one specific SGML document type, or document type definition (DTD). Because it is so easy to learn and to implement, and because early Web browsers supported it, HTML quickly became the basis of the burgeoning Web. In fact, if SGML had been the Web's essential markup language, the Web probably wouldn't have attained the enormous popularity it now enjoys.
The problem with HTML, however, was that it quickly proved to be too simple. It was superb for the early days of the Webwith text-based documents that featured headings, bulleted lists, and hyperlinks to other documentsbut as soon as Web authors started demanding multimedia and page design capabilities, the language started experiencing severe growing pains. Straightforward in-line graphics were fine, but you couldn't do much to place them, so page design suffered. And image maps (images with embedded hyperlinks) created new problems and needed new solutions. Then came blinking text, tables, frames, and dynamic HTML. Every time we turn around, it seems, someone's trying to add something new to HTML, and every time that happens we end up with new incompatibilities and the need for new standards.
Why is this happening? Because, quite simply, HTML isn't extensible. Over the years, Microsoft has added tags that work only in Internet Explorer, and Netscape has added tags that work only in Navigator, but you, as a Web author, have no way to add your own.
Apart from the strife engendered by non-standard HTML implementations, HTML has been suffering from another problem. As a markup language, HTML's original job was to define the structure of Web documents. But in the rush to produce a more riveting experience on the Web, this purpose has been lost. HTML as it now stands is being used to control presentation as well as structure.
Web designers, faced with the total lack of tools for controlling the layout of their pages, have forced HTML way beyond its bounds. The italics tag has replaced the emphasis tag; tables are used to position text and graphics; spacer graphics (1-pixel invisible GIF files) are used to create space between page elements.
The situation is exacerbated by the addition of incompatible implementations of scripting languages and controls (JavaScript, VBScript, and ActiveX) used to add a degree of interactivity to Websites.109
Admittedly, artists and hackers have been able to work miracles with the relatively dull tool called HTML. But HTML has serious drawbacks that make it a poor fit for designing flexible, powerful, evolutionary information systems. Here are a few of the major complaints:
• HTML isn't extensible . An extensible markup language would allow application developers to define custom tags for application-specific situations. Unless you're a 600-pound gorilla (and maybe not even then), you can't require all browser manufacturers to implement all the markup tags necessary for your application. So, you're stuck with what the big browser makers, or the W3C (World Wide Web Consortium) will let you have. What we need is a language that allows us to make up our own markup tags without having to call the browser manufacturer.
• HTML is very display-centric . HTML is a fine language for display purposes, unless you require a lot of precise formatting or transformation control (in which case it stinks). HTML represents a mixture of document logical structure (titles, paragraphs, and such) with presentation tags (bold, image alignment, and so on). Since almost all of the HTML tags have to do with how to display information in a browser, HTML is useless for other common network applicationslike data replication or application services. We need a way to unify these common functions with display, so the same server used to browse data can also, for example, perform enterprise business functions and interoperate with legacy systems.
• HTML isn't usually directly reusable . Creating documents in word-processors and then exporting them as HTML is somewhat automated but still requires, at the very least, some tweaking of the output in order to achieve acceptable results. If the data from which the document was produced change, the entire HTML translation needs to be redone. Websites that show the current weather around the globe, around the clock, usually handle this automatic reformatting very well. The content and the presentation style of the document are separated, because the system designers understand that their content (the temperatures, forecasts, and so on) changes constantly. What we need is a way to specify data presentation in terms of structure, so that when data are updated, the formatting can be "reapplied" consistently and easily.
• HTML only provides one "view" of data . It's difficult to write HTML that displays the same data in different ways based on user requests. Dynamic HTML is a start, but it requires an enormous amount of scripting and isn't a general solution to this problem. (Dynamic HTML is discussed in more detail below.) What we need is a way to get all the information we may want to browse at once, and look at it in various ways on the client.
• HTML has little or no semantic structure . Most Web applications would benefit from an ability to represent data by meaning rather than by layout. For example, it can be very difficult to find what you're looking for on the Internet, because there's no indication of the meaning of the data in HTML files (aside from META tags, which are usually misleading). Type red into a search engine, and you'll get links to Red Skeleton, red herring, red snapper, the red scare, Red Letter Day, and probably a page or two of "Books I've Red." HTML has no way to specify what a particular page item means. A more useful markup language would represent information in terms of its meaning. What we need is a language that tells us not how to display information, but rather, what a given block of information is so we know what to do with it.
• Easy to use with low-cost software (ranging from zero to $150 in most cases for HTML converters/editors). The latest word processing upgrades have limited HTML converters and editors included in the upgrade.
• Both HTML authors and users can be trained easily and inexpensively.
• HTML documents can be stored in cache such that the server is not tied up every time the client user wants to return to an HTML file (files can be stored in the browser's cache for short periods of time even if the user does not formally download and save the HTML file in a designated directory).
• HTML documents can be easily printed using browser menu choices (linked graphics appear on pages as if they were pasted onto the document itself).
• It is very easy to modify sizes of graphics images. A stored gif or jpg file can be viewed in a wide range of sizes (although increasing the size beyond the stored image size may result in pixelization).
• HTML documents are easy to search and have given rise to popular web search engines (e.g., Yahoo, Altavista, Lycos, HotBot, etc.).
• An HTML document can be viewed on multiple platforms (Windows, Macintosh, UNIX workstations, etc.).
• HTML on the Web can be networked across existing Internet networks.
• HTML documents can contain links to graphics, audio, video, and animation files.
• HTML documents are easy to access with modern browsers and save to client machines with minimal or no virus risks (relative to say virus risks of downloading word processor documents such as DOC files. Browsers, however, are no longer risk free.).
• HTML source codes are easy to view and modify--usually with the menu choice (View, Source) in a browser.
• HTML is "document" rather than "data" centered and does not facilitate distributed network computing or relational database management utilities.
• HTML is static and cannot make arithmetic calculations, date/time operations, perform Boolean logic, or revise data on the client or host computers. You cannot add 2+2 in HTML code.
• HTML cannot be coded to conduct searches (although other software can be programmed to search HTML documents).
• HTML cannot be made to tabulate survey responses (even though surveys can be conducted using forms in HTML documents).
• HTML cannot perform security operations (authorize password clearances, authenticate servers or clients, encode and decode transmissions, etc.).
• HTML cannot be made to react to signals such as the reaction of replying to messages.
• HTML on the Web requires connectivity to the Web, which, in turn, requires monthly or annual fees and frustrations of delays caused by clogged networks having insufficient bandwidth (especially for users that must use slow modem connections) .
• HTML generally leads to too many hits when using search engines. The XML and RDF solutions to this problem are on the way.110
• SGML was created for general document structuring, and HTML was created as an application of SGML for Web documents. XML is a simplification of SGML for general Web use.
Style Sheets
Since the beginning of the Web just a few short years ago, HTML designers have had to serve two audiences. On the one hand, the prime audience for Web pages is, rather obviously, people. Yet the HTML language syntax is geared more towards creating machine-readable text rather than text meant to look good for readers. For example, there are HTML commands for declaring that a text chunk is a definition, an ordered list, or a table; there aren't commands for setting margins or font types, or sizes.
There is a way out of this trap-- style sheets . Style sheets allow page authors to cleanly split structure and content away from form and appearance. Just as HTML is the language to describe structure and content, so form and appearance will be described by a style sheet language.111
Style sheets allow you to control the rendering, e.g. fonts, colors, leading, margins, typefaces, and other aspects of style, of a Web document without compromising its structure. CSS is a simple style sheet mechanism that allows authors and readers to attach style to HTML documents. It uses common desktop publishing terminology, which should make it easy for professional as well as untrained designers to make use of its features. Visual design issues, such as page layout, can thus be addressed separately from the Web page logical structure.112
Style sheets (also known as cascading style sheets or CSS) are groups of styles, which in turn are groups of properties that define how an HTML element appears in a Web browserfor instance, green, italic, and Arial. You can define styles either within an HTML document or in an external file attached to the HTML document. As an external file, a single style sheet can affect multiple pageseven a whole site. This makes page-wide or site-wide changes much easier to implement.
A style sheet language offers a powerful and manageable way for authors, artists, and typographers to create the visual effects they want, e.g. margins and indents, line spacing and length, background images and colors, fonts, font sizes, font colors, and much more.
As the term cascading style sheets implies, more than one style sheet can be used on the same document, with different levels of importance. If you define conflicting styles for the same HTML tag, the innermost definitionthe one closest to the tagwins. For example, an in-line style takes precedence over a span, which has priority over a style defined in the head of the document, which in turn wins over an attached style sheet. If conflicting styles are defined at the same level, the one occurring later wins.
Style sheets allow you to add real presentation to your Web pages. If you've ever become annoyed that HTML could not perform even the most basic word-processing functions, then style sheets are for you. Ever wanted to indent a paragraph? Change its leading? Increase the amount of space between paragraphs? You can't do that in HTML without doing sneaky things with images or using tags in ways for which they were not intended. Style sheets let you do all those things without breaking your code for existing browsers.
Apart from the design advantages, style sheets also have an edge over plain HTML in terms of maintenance. Because style sheets allow you to collect presentation information at the top of a page or in a different file altogether, you can change the look and feel of a whole set of pageseven a site with hundreds of thousands of pagesby editing just one file. Remember when the Communications Decency Act passed, and Net activists urged us to turn our page backgrounds black in protest? If you had thousands of pages to change, that might have been a daunting task. If you used style sheets, however, there would have been only one file to edit and one line to change. If you're working with a large site with a strict design, using style sheets is a tremendous advantage over using individual HTML tags to determine the design of a page.113
You can embed a style sheet inside an HTML document, or insert a link to an external style sheet that can influence any number of documents. CSS is implemented in several browsers, including Microsoft Internet Explorer, and Netscape Navigator.
CSS is backward compatible to the extent that viewing a style-enhanced site with an older browser causes no problems at all. Of course, the user doesn't see the stylistic enhancements made possible by CSS (e.g., multiple fonts and indented margins), but the text of the page will be readable and will be presented in a reasonable default style. In contrast, a page designed with frames is useless for a user with an old browser.
CSS is orthogonal to other features in Web browsing. When multiple style sheets become supported in future releases of the mainstream browsers, users might want to learn the command to switch between styles, but they won't have to. Even if users do learn this new command, it will not interfere with or change their understanding of earlier commands and operations. In contrast, frames destroy bookmarks, change the meaning of established commands like "print" and "view source," and in general make a mess of the user's prior understanding of the Web.
CSS builds on the philosophy of the Web : cross-platform design and simple-to-understand codes that are precisely documented in public specifications. In contrast, frames are hard to learn for authors, poorly documented, and have no chance of working on anything except desktop computers with relatively large screens (try fitting frames on a Pilot palmtop and you will see what I mean).
CSS alleviates a widely felt weakness of prior Web technology : authors used to have too little control over the presentation of their content and had to stoop to unseemly hacks and improper HTML to get the effects they needed. Frames admittedly address the often-requested desire to keep a part of the page from scrolling, though this one useful effect of frames can be achieved much simpler with the <BANNER> tag proposed in HTML 3.0. Most of the features offered by frames are of relatively little utility compared with the effects offered by tables and style sheets.114
• Style sheets allow you to separate the style and layout of your HTML files from their informational content. You can define the look of a site in one file, and change the whole site by changing just the one file. But be careful of unexpected effects! You can make all of your HTML layout and formatting changes in one location, either in an external file referenced by any number of pages, or the style can be applied to a specific section of text within the body of a page. The HTML code becomes simpler and more manageable because you don't have to keep repeating tricks to control rendering in your HTML files (except that you will need for a while to maintain good presentation for older browsers).
• Using relative measurements in your style sheet, you can make your documents look good on any monitor at any resolution. You have finer and more predictable control over presentation. CSS has been designed to deal with issues which HTML was not. Older browsers will simply ignore your style sheets so they will not break existing pages.
• The CSS style sheet mechanism allows readers to influence the presentation of HTML documents. Style sheets allow both document authors and readers to specify rendering rules for HTML documents. Cascading means that if both parties supply style sheets then the browser will apply both, using further rules for resolving conflicts. Style sheets will allow companies to easily adopt a house look and feel, and this will help give readers a sense of where they are and what they are reading. Style sheets can be pointed to from Web documents via hyperlinks and this will dramatically simplify the maintenance of Websites. If the company later changes the house style they only need to make changes in one place.
• The main document format on the Web, the Hypertext Markup Language (HTML), was intentionally designed as a simple language that favored document structure over document presentation. The enormous commercial interest in the Web has created an enormous demand for enhanced presentations. The definition of a common style sheet format for HTML documents offers significant advantages over the many proprietary solutions which currently exist.
• Style sheets will also improve the printing of Web documents. Paper has different properties than a computer screen and the differences can be accounted for in a style sheet. Web authors should be confident that their documents will look as good on paper as they do on computer screens.
• People with disabilities have better access to your pages. Visually impaired Web users may need increased font sizes and were among the first to benefit from style sheets. CSS provides a framework for speech style sheets. A style sheet can produce rich aural presentations by describing pauses, intonation, and other components of speech along with non-speech sound cues.115
Most browsers these days (Netscape 4 and above, Internet Explorer 3 and above, Opera 3.5 and above) implement CSS pretty consistently for HTML. You'll be reading a lot in the next few months about CSS and XML availability in browsers. Also, keep in mind that CSS could be used to apply style to documents on the server and serve "straight HTML" without the CSS markup.
As powerful as CSS is, it has one major limitation: It can't "transform" the data it's styling. CSS can make an HTML or XML document look different, and even hide elements, but it can't reshuffle, cross-reference, or restructure them. For example, say you wanted to transform the XML recipe in Listing 3 to the HTML in Listing 1. Notice that you want the title to appear both in the browser's title bar (in an HTML <TITLE> element), and as a heading on the page (in a <H3> element). CSS can't do that; all it can do is apply style to an existing structure.
XML
As the Web exploded in popularity and people all over the world began learning about HTML, they fairly quickly started running into the limitations outlined above. Heavy-metal SGML wonks, who had been working with SGML for years in relative obscurity, suddenly found that everyday people had some understanding of the concept of markup (that is, HTML). SGML experts began to consider the possibility of using SGML on the Web directly, instead of using just one application of it (again, HTML). At the same time, they knew that SGML, while powerful, was simply too complex for most people to use.
The Web's many developers have recognized for quite some time that whereas HTML offers no extensibility, its parent system, SGML, is fully extensible. To create a fully customized set of documents in SGML, authors develop a DTD that will control all documents in that set. This is time-consuming and can be extremely complex, but it works. The question, then, is how to capture SGML's extensibility, which serious HTML authors require, without retaining the complexity, which almost nobody wants. In other words, the issue is how to bridge the gap between SGML and HTML.
The answer is Extensible Markup Language, better known as XML. Proposed in late 1996 to the World Wide Web Consortium (W3C), its intention is to offer some of SGML's power while avoiding the language's complexity, enabling Web authors to produce fully customized documents with a high degree of design consistency. It can offer these things because XML is SGML. Whereas HTML is merely one SGML document type, XML is a simplified version of the parent language itself.
XML is more than a markup language. Like SGML, it's a meta-language, or a language that allows you to describe languages. HTML and other markup languages let you define how the information in a document will appear in an application that displays it, but SGML and XML let you define the markup language itself. In this sense, XML can actually control HTML documents. Think of HTML as a description system and XML (like SGML) as a system for defining description systems and you get the idea. One benefit of SGML is that you can use it to define and control an unlimited variety of description systems, HTML being only one of these, and XML offers this advantage as well.
One of XML's greatest strengths is that it lets entire industries, academic disciplines, and professional organizations develop sets of DTDs that will standardize the presentation of information within those disciplines. To an extent this works against the much-ballyhooed universality of the Web and HTML, but if you work in a specialized area, you're probably aware of the need for systems that let you produce documents enabling you to communicate efficiently with your colleagues. Specialists often need to display formulas, hierarchies, mathematical and scientific notations, and other elements, all within well-defined parameters. SGML's DTD system lets you do so, and XML picks up on the DTD system without all the complexity.
One example of XML's advantage over HTML lies in its linking possibilities. HTML's linking, even though it is the basis of the entire Web, is extremely limited. You can link to internal or external documents, but the links are unidirectional and always connected to a hard-coded address. That's why you get so many "Document not found" errors.
HTML's redirection capabilitieswhich automatically forward the browser to another locationtake care of some of these issues, but the proposed XML standard takes linking much further. With XML, Web authors can establish multidirectional links, which not only link to a destination location but also provide information about links to the current location from other locations. As an example, an author can provide a link that will take users to a particular resource; a cross-reference link will then show all the links that lead to that resource, and the user can follow these links to their sources. XML authors can also specify what happens when a link is found, such as whether or not the link will be followed automatically, and even whether or not the linked document will be displayed within the original document. As XML linking options find their way into general use, the Web will become a much more capable hypermedia system.
The DTD system is only one method of creating XML documents. DTDs offer the greatest possible flexibility and extensibility, but one of the XML team's design goals has been to eliminate the need for building them. As a result, there are two types of XML document, those with DTDs and those without. Those with DTDs that conform to the SGML standard are called valid files. Documents that exclude DTDs must be well-formed; that is, they must conform to a specific set of standards. Valid files must be well-formed too.
A valid XML document, like a valid SGML document, opens with a Document Type Declaration, through the <!doctype ..> element. In addition, the document might have an XML Declaration before the DTD to specify the version of XML in use, but this isn't strictly needed. If present it takes the form
with 1.0 replaced, of course, by whatever version is in effect. The XML version must be available locally or over the Net, and the XML Declaration will state its location.
The Document Type Definition's purpose is to specify the structure for the content of all documents of a certain type; thus the Document Type Declaration represents the core of SGML. It might seem strange or even impossible, therefore, that XML could let you dispense with the >!doctype< element completely. It does so by demanding that files be well formed, which lets the viewer interpret them as SGML. Instead of having a DTD, the XML document must follow a series of rules, none of which are difficult for authors to master.
First, a document must begin with a Required Markup Declaration (RMD) stating that the document lacks a DTD (the code is "NONE"). This RMD occurs in the same line as the XML Declaration, in the form
<?XML VERSION="1.0" RMD="NONE">
Second, all values for attributes must be enclosed in quotation marks. Third, all elements must have opening and closing tags, unlike some elements in HTML. Other requirements dictate the type of attributes available, as well as some restrictions on the data itself. As long as you adhere to these rules you may omit the DTD, and that simple fact goes a long way toward making XML more accessible than SGML.
So what about HTML? Are your current HTML documents invalid or poorly formed or both? Not necessarily. Remember that HTML is simply one SGML DTD; as long as a document conforms to the HTML 3.2 standard, it will be all or at least mostly well-formed. All you have to do is ensure that it adheres to the XML rules for well-formed documents and you're set. You can also run your HTML files through an SGML-aware authoring tool such as SoftQuad's HoTMetaL Pro (www.sq.com/) or turn to parsing software such as Lark (www.textuality.com/Lark/).
Unless XML offers the ability to produce new kinds of applications, it won't be of great value to the Web authoring community. Much of the early development work is still in progress, but XML appears to be extremely well suited to several advanced application types.
First, because of its data structures, XML provides a good way to develop applications that let the user view data from various perspectives. Such applications can make documents more useful by sorting data according to various criteria (by name, by number, and so on) or by providing a way to toggle different information on and off. For instance, a listing that contains program information for all flavors of Windows could display only the user's version at the click of a mouse.
XML can also be applied to an Intranet (a site restricted to users inside an organization) or an extranet (a site restricted to select users outside an organization). If an organization needs to present extensive amounts of data in particular formats, complete with strong database linkages, XML offers a solution. From an extranet standpoint, organizations can make their information available to clients through XML browsers, and entire industries can band together to produce an XML standard for information presentation.
XML is also much better than HTML at drawing data from heterogeneous database types and displaying that data in a consistent format. Of course, SGML already makes all of this possible, but XML is easier to use and faster to implement.116
To take an existing XML structure and produce a new structure of something else (in this case, HTML), you need XSL: the Extended Style Language.
Fortunately, the W3C committees discussing style, HTML, and XML have included in their design the Extensible Style Language, or XSL. XSL is based on DSSSL (and DSSSL-O, the online version of DSSSL), and also uses some of the style elements of CSS. It's simpler than DSSSL, while retaining much of its power (much like the relationship between XML and SGML). XSL's notation, however, may be surprising: it's XML. The simplest way to say it is: XSL is an XML document that specifies how to transform another XML document.
Why XSL is so useful . XSL is immensely powerful. It can be used to add structure to a document (as in CSS), and it can also completely rearrange the input elements for a particular purpose. For example, XSL can transform XML of one structure into HTML of a different structure. XSL can also restructure XML into other document formats: TeX, RTF, and PostScript.
XSL can even transform XML into a different dialect of XML! This may sound crazy, but it's actually a pretty cool idea. For example, multiple presentations of the same information could be produced by several different XSL files applied to the same XML input. Or, let's say two systems speak different "dialects" of XML but have similar information requirements. XSL could be used to translate the output of the first system into something compatible with the input of the second system.
These last few reasons are of special interest to Java programmers, since XSL can be used to translate between different languages in a distributed network of subsystems, as well as to format documents. Understanding how to use XSL in simple applications, like transforming XML to HTML, will help a Java developer understand XSL in general.
Additional XSL capabilities. XSL isn't limited to just producing HTML. XSL also has complete support for "native" formatting, which doesn't rely on translation to some other format. Nobody has yet implemented this part of XSL, though, primarily because page formatting and layout is very tough to wrangle.
XSL's design also includes embedded scripting. Currently, IBM's LotusXSL package (written in Java) provides the functionality of almost all of the current draft specifications of XSL, including the ability to call embedded ECMAScript (the European standard JavaScript) from XSL templates.
Of course, as always, with power comes complexity. Learning to write XSL isn't a piece of cake. But the power's there if you want it.
XML is more than just content management . XSL, like CSS, can be used on either the client or the server in a client/server system. This fact provides immense flexibility and organization to Website designers and managers. So much so, in fact, that many people think of XML, CSS, and XSL as another set of technologies for "content management" for their Websites. It makes styling Web documents easier and more consistent, facilitates version control of the site, simplifies multi-browser management (think of using a style sheet to overcome the many differences between browsers), and so forth. CSS is also useful for Dynamic HTML (which we'll discuss a bit below), where much of the user interaction occurs on the client side, where it belongs. From the point of view of people managing Websites, XML, CSS, and XSL are indeed big wins. And yet, there's a whole world of applications that have nothing to do with browsers and Web pages. The map of that world is called the Document Object Model.117
VRML
Virtual reality modeling language (VRML) is a standard language for the animation and 3D modeling of geometric shapes. It allows for 3D scenes to be viewed and manipulated over the Internet in an interactive environment. Using a special VRML browser , the user can connect to an online VRML site, choose a 3D environment to explore and move around the "3D world." It is possible to zoom in and out, move around, and interact with the virtual environment. VRML is also intended to be a universal interchange format for integrated 3D graphics and multimedia.
There are two major versions of VRML:
(1) VRML 1.0 worlds are static environments where you can navigate and click on objects to link to information. The first version of VRML allows for the creation of virtual worlds with limited interactive behavior. These worlds can contain objects which have hyperlinks to other worlds, HTML documents, or other valid MIME types. When the user selects an object with a hyperlink, the appropriate MIME viewer is launched. When the user selects a link to a VRML document from within a correctly configured WWW browser, a VRML viewer is launched. Thus VRML viewers are the perfect companion applications to standard WWW browsers for navigating and visualizing the Web.
(2) VRML97 is the informal name of the International Standard (ISO/IEC 14772-1:1997). It is almost identical to VRML 2.0, but with many editorial improvements to the document and a few minor functional differences. (VRML97 is also the name of the VRML Technical Symposium that took place in February 1997 in Monterey, CA.) It provides these extensions and enhancements to VRML 1.0: Enhanced static worlds; Interaction; Animation; Scripting; Prototyping. VRML 2.0 takes VRML and extends it with animation, behaviors, sensors and sounds. There are also some new geometry primitives as well as support for collision detection. The VRML 2.0 scene graph has also been modified to support PC rendering systems more efficiently.118 6
VRML has been designed to fulfill the following requirements:
• Authorability--Enable the development of computer programs capable of creating, editing, and maintaining VRML files, as well as automatic translation programs for converting other commonly used 3D file formats into VRML files.
• Composability--Provide the ability to use and combine dynamic 3D objects within a VRML world and thus enable re-usability.
• Extensibility--Provide the ability to add new object types not explicitly defined in VRML.
• Be capable of implementation--Capable of implementation on a wide range of systems.
• Performance--Emphasize scalable, interactive performance on a wide variety of computing platforms.
• Scalability--Enable arbitrarily large dynamic 3D worlds.
VRML is capable of representing static and animated dynamic 3D and multimedia objects with hyperlinks to other media such as text, sounds, movies, and images. VRML browsers, as well as authoring tools for the creation of VRML files, are widely available for many different platforms.
VRML supports an extensibility model that allows new dynamic 3D objects to be defined allowing application communities to develop interoperable extensions to the base standard. There are mappings between VRML objects and commonly used 3D application programmer interface (API) features.119 The leader in three-dimensional (3D) technology for the Internet produces WorldView 2.0, the fastest VRML 2.0 plug-in application for Netscape Navigator Web browsers. WorldView 2.0 for Microsoft Windows 95 and Windows NT is designed with the industry standard VRML 2.0. WorldView 2.0 empowers users to easily navigate 3D spaces with more animation, multimedia, and interactive capabilities. WorldView 2.0 is available from the Intervista Website.
New Technology
Advanced Authoring Format
The Advanced Authoring Format, or AAF, is an industry-driven, cross-platform, multimedia file format that will allow interchange of media and compositional information between AAF-compliant applications. These applications are primarily content creation tools such as Adobe Premiere, Photoshop, and AfterEffects, Avid Media Composer and Cinema, Sonic Foundry's Sound Forge, and SOFTIMAGE|DS, to name a few.
The Advanced Authoring Format helps the content creation and authoring process by addressing the shortcomings of other formats. In this way, AAF will allow creative energies to be more focused on the quality of the media compositions rather than dealing with unnecessary and painful interchange issues, and allows software development to focus on improvements to the authoring application's feature set.
The Advanced Authoring Format defines authoring as the creation of multimedia content including related metadata. In the authoring process, it is important to record both the editing and scripting decisions that have been made. It is also important to record the steps used to reach the final output, the sources used to create the output, the equipment configuration, intermediate data, and any alternative choices that may be selected during a later stage of the process.
The Advanced Authoring Format's unified interchange model enables interoperability between applications. This offers distinct advantages over the current model of separate formats and authoring tools for each media type:
• The authoring process requires a wide range of applications that can combine and modify media. Although applications may have very different domains, such as an audio editing application and a 3-D graphics animation application, the authoring process requires both applications to work together to produce the final presentation.
• Applications can extract valuable information about the media data in an AAF file even when it does not understand the media data format. It can display this information, which allows the user to better coordinate the authoring process.
By enabling interoperability between authoring applications, AAF enables the user to focus on the creative production processes rather than struggling with conversions during the authoring and production phases of the project. Although there are many other issues related to completely transparent interoperability, the significant benefit that AAF provides to end users is assurance that compositions output by AAF-compliant applications will be accessible by the right tool for the job, without risk of being "stranded" by proprietary file format restrictions.
The authoring applications that can use AAF for interchange include:
• Television studio systems, including picture and sound editors, servers, effects processors, archiving, and broadcast automation systems.
• Post-production systems, including digitization, off-line editing, graphics, compositing, and rendering systems.
• Image manipulation applications, including palettizing tools.
• Audio production/engineering systems, including multitrack mixers and samplers.
• Multimedia content creation systems, including scripting, cataloging, titling, logging, and content repackaging and repurposing applications.
• Image and sound recording equipment, including cameras and camcorders, scanners, telecines, sound dubbers, disk recorders, and data recorders.
The Advanced Authoring Format provides applications with a mechanism to interchange a broad range of media formats and metadata, but applications may have interchange restrictions due to other considerations. For this reason, it is important to understand the different kinds of interchange possible and to describe the various levels of interchange between authoring applications. The following is a general description of the levels of AAF interchange that applications can adopt.
• Interchange of limited sets of media data.
• Interchange of broad sets of media data with some related metadata.
• Interchange of media data and rich sets of metadata including compositions but having limited support for some media types.
• Full interchange of all media types and all metadata described in this specification and preserving any additional private information stored in the AAF file.
The Advanced Authoring Format is designed to be a universal file format for interchange between systems and applications. It incorporates existing multimedia data types such as video, audio, still image, text, and graphics. Applications can store application-specific data in an AAF file and can use AAF as the application's native file format. AAF does not impose a universal format for storing media content data. It has some commonly used formats built-in, such as CDCI and RGBA images, WAV and AIFC audio, but also provides an extension framework for new formats or proprietary formats. As groups such as the Society for Motion Picture and Television Engineers (SMPTE) and the Audio Engineering Society (AES) adopt standard formats for media, AAF will provide built-in support for these formats.
At its most basic level, AAF encapsulates and identifies media data to allow applications to identify the format used to store media data. This makes it unnecessary to provide a separate mechanism to identify the format of the data. For example, AAF can encapsulate and label WAV audio data and RGB video data.
The actual audio, video, still, and other media data makes up only part of the information involved in authoring. There is also compositional information, which describes how sections of audio, video, or still images are combined and modified. Given the many creative decisions involved in composing the separate elements into a final presentation, interchanging compositional information as well as media data is extremely desirable, especially when using a diverse set of authoring tools. AAF includes a rich base set of media effects (such as transitions or chroma-key effects), which can be used to modify or transform the media in a composition. These effects use the same binary plug-in model used to support codecs, media handlers, or other digital processes to be used to process the media to create the desired impact.
One of AAF's strengths is its ability to describe the process by which one kind of media was derived from another. AAF files contain the information needed to return to an original source of media in case it needs to be used in a different way. For example, when an AAF file contains digital audio and video data whose original source was film, the AAF file may contain descriptive information about the film source, including edgecode and in- and out-point information from the intermediate videotape. This type of information is useful if the content creator needs to repurpose material, for instance, for countries with different television standards. Derivation information can also describe the creation of computer-generated media. If a visual composition was generated from compositing 3-D animation and still images, the AAF file can contain the information to go back to the original animation sources and make changes without having to regenerate the entire composition.
The Advanced Authoring Format is not designed to be a streaming media format, but it is designed to be suitable for native capture and playback of media and to have flexible storage of large data objects. For example, AAF allows sections of data to be broken into pieces for storage efficiency, as well as inclusion of external references to media data. AAF also allows in-place editing; it is not necessary to rewrite the entire file to make changes to the metadata.
The Advanced Authoring Format defines extensible mechanisms for storing metadata and media data. This ensures that AAF will be able to include new media types and media data formats as they become commonly used. The extensibility of the effects model allows ISVs or tool vendors to develop a rich library of new and engaging effects or processes to be utilized with AAF files. The binary plug-in model gives AAF-compliant applications the flexibility to determine when a given effect or codec has been referenced inside of the AAF file, determine if that effect or codec is available, and if not, to find it and load it on demand.
In contrast to authoring systems, delivery systems and mechanisms are primarily used to transport and deliver a complete multimedia program. Although it would be ideal to use a single format for both authoring and delivery, these processes have different requirements. With authoring as its primary focus, AAF's metadata persistence enables optimal interchange during the authoring process. By allowing the content files to be saved without the metadata (i.e. "stripping out the metadata" or "flattening the file"), AAF optimizes completed compositions for delivery, without restricting features needed for authoring.
From a technical standpoint, digital media content delivery has at least two major considerations: (1) target playback hardware (TV, audio equipment, PC) and (2) distribution vehicle (film, broadcast TV, DVD and other digital media, network). When content is delivered, the delivery format is usually optimized for the particular delivery vehicle (DVD, DTV, and others), and the media data is often compressed to conserve space or enable fast download.
We expect that the content created using AAF in the authoring process will be delivered by many different vehicles including broadcast television, packaged media, film, and over networks. These delivery vehicles will use data formats such as baseband video, MPEG-2 Transport Stream, and the Advanced Streaming Format (ASF). These formats do not need the rich set of metadata used during the authoring process and can be optimized for delivery by stripping out this metadata or "flattening" the file.
The Advanced Authoring Format is a structured container for media and metadata that provides a single object-oriented model to interchange a broad variety of media types including video, audio, still images, graphics, text, MIDI files, animation, compositional information, and event triggers. The AAF format contains the media assets and preserves their file-specific intrinsic information, as well as the authoring information (in- and out-point, volume, pan, time and frame markers, etc.) involving those media assets and any interactions between them.
To meet the rich content authoring and interchange needs, AAF must be a robust, extensible, platform-independent structured storage file format, able to store a variety of raw media file formats and the complex metadata that describes the usage of the media data, and be capable of efficient playback and incremental updates. As the evolution of digital media technology brings the high-end and low-end creation processes into convergence, AAF must also be thoroughly scalable and usable by the very high-end professional applications as well as consumer-level applications.
Structured storage, one of the technical underpinnings of AAF, refers to a data storage architecture that uses a "file system within a file" architecture. This container format is to be a public domain format, allowing interested parties to add future developments or enhancements in a due process environment. Microsoft is specifically upgrading the core technology compound file format on all platforms (Microsoft Windows, Apple Macintosh, UNIX) to address the needs of AAF, for instance, files larger than 2 gigabytes and large data block sizes.
Other important features of AAF include:
• Version control, allowing an AAF file's data to be edited and revised while retaining the history of the changes such that an older version of the file can be recalled, if necessary.
• AAF files will retain information about the original sources, so that the resulting edited media can be traced back to its original source.
• References to external media files, with files located on remote computers in heterogeneous networks.
• An extensible video and audio effects architecture with a rich set of built-in base effects.
• Support for a cross-platform binary plug-in model.
The Advanced Authoring Format is the product of seven industry-leading companies, each contributing valuable solutions and technologies. The AAF task force members include Microsoft, Avid Technology, Adobe, DigiDesign, Matrox, Pinnacle Systems, Softimage, Sonic Foundry, and Truevision. As the Advanced Authoring Format specification evolves, the promoting companies will concurrently integrate AAF support with their product offerings. In addition, the Advanced Authoring Format Software Development Kit (AAF SDK) will enable other adopting companies to readily provide AAF support in their own products.120
Coping with HTML
The World Wide Web's explosive growth has put the software industry through eons of change in just a few years, and the tools for designing and creating Web pages are no exception. The good old days are gone forever; using Windows Notepad or a similar bare-bones text editor to code HTML by hand no longer cuts it in cyberspace.
Technologies such as JavaScript, Cascading Style Sheets (CSS), and Dynamic HTML have made hand coding of Web pages difficult and time-consuming. The new generation of Web-page creation tools speeds these tasks with WYSIWYG interfaces and automatic text markup, while retaining access to the underlying HTML code with an interface that lets the user switch smoothly between the two modes.
The HTML standards process is perhaps the most visible casualty of the Internet. The rapid growth of the Web has completely outstripped any organization's ability to define and standardize it, leaving the ever-changing HTML standard to serve the role of Web archive, documenting aspects of HTML that have long fallen into disuse by the time each new version of the standard is approved. Still, the HTML standard serves a useful purpose, especially as the scope and features of HTML begin to settle.
If you've tried to keep up with the changes in hypertext markup language over the past three years, you might be under the impression that this vital coding language--the heart of the Web itself--is nothing more than a cobbled-together pastiche of the good, the not-so-good, and the nice-but-only-one-browser-supports-it. And you wouldn't be far wrong. New HTML tags and containers appear with each browser release, and it seems to take forever (in Web terms, at least) for the World Wide Web Consortium (W3C) to incorporate these items into the official HTML specification.
However, HTML 4.0 was released as a formal standard in 1998. It defined a version of HTML that all browsers can support, making it easier for authors to know what to use in their documents. 4.0 adds some useful table extensions that make page breaks and printing somewhat easier to manage, and it formalizes frames, which were sorely missed in HTML 3.2.
While questions about XML are being raised by the technical Web community, HTML is showing no signs of disappearing immediately. According to the W3C, HTML is here "for several years to come." HTML 4 won't be the last version, and we'll see HTML and XML coexist for some time. Hopefully during that time Microsoft and Netscape will get in sync with one another and with the developing HTML and CSS standards.121
In 1996, W3C issued the standard for HTML 3.2. The main purpose of this release was to collect and approve many of Microsoft's and Netscape's proprietary codes, simply because they were being widely used anyway. But it was quite clearly a stop-gap measure for use while a more revolutionary HTML version was being developed. The new version, which for several months was code-named Cougar, was designed in part to end the proprietary nature of HTML enhancements. This version won't succeed fully, of course, because it's too important for Microsoft and Netscape to be the first and only kids on the block with new HTML design toys, but at least the potential for controlled expansion of the Web's main authoring code now exists.
Still, that kind of controlled expansion was only one of the issues surrounding the development of HTML 4.0. The other was the increasing need to provide improved page layout and programmability features. These needs have been attended to as well, and the result is an HTML that, even on first reading, the specification seems more mature than before. This version may cause XML to gain a slower, measured foothold, and the two might very well find a happy coexistence.
The main problem with HTML so far has been that its list of available tags and containers (a container is a matched set of tags, such as <CENTER> xxx </CENTER> for centering) has been fixed from one version to the next. Page authors have had access to an increasing range of design and programming capabilities, but the most advanced authors have always wanted more, and they've wanted that quickly.
Simply put, HTML has never been easily extensible. Extending it has required first developing the new elements (itself not a difficult task) and then designing or redesigning a browser to display those tags properly (a far harder task). Effectively this problem has made extending HTML possible only for Microsoft and Netscape, since browser share over the past couple of years has gone almost exclusively to those companies. But neither company sets HTML standards, so the de facto process has been for Microsoft and Netscape to introduce their extensions and then submit them for adoption into official HTML by the W3C. HTML 3.2 was largely a case of bundling the best of such existing tags into an official setting.
HTML 4.0 takes a different tack. Here, the idea hasn't been to include as many existing but unofficial elements as possible into the official specification, but rather to enable developers to extend HTML themselves, at least to a degree. Although not nearly as extensible as XML, HTML 4.0 at least makes this possible. And it does so quite simply, through a new element called an object. The OBJECT container tells the browser that it is about to encounter one of several types of elements, usually multimedia-based. The container will also tell the browser whether it should attempt to render the object or hand over the rendering to an external application.
The OBJECT container can include three main pieces of information:
(1) The location of the application that will render the object.
(3) Any parameters that apply to the rendering.
The browser must first attempt to adhere to the full rendering instructions, but if that's not possible, it must try to render the element itself.
One example of an OBJECT type is the image file. Until now, the IMG tag has handled image files, and that need not change. But for the sake of consistency, images are now also object types, and possibly the IMG container could eventually be phased out. Comparing the two shows the difference:
<IMG SRC="http://www.mycomputer.com/
<OBJECT data="http://www.mycomputer.com/images/1997/
meeting01.jpg" type="image/jpg">
Another example shows the new means of including applets in HTML 4.0. Again, either sample is acceptable to HTML 4.0, but the APPLET element could eventually be phased out:
<APPLET code="songviewer.class"
width="550" height="600">Click here to
view the sheet music in a Java applet</APPLET>
<OBJECT codetype="application/octet-stream"
classid="java: songviewer.class" width="550"height="600">
Click here to view the sheet music in a Java applet</OBJECT>
Now, it's clear that in both cases, the pre-4.0 method is shorter and requires less coding. So why bother with the OBJECT container? First, and not insignificantly, treating objects in this way gives HTML greater consistency: All non-HTML file types can be treated as objects, and this means less of a need to learn a host of HTML element names. That makes HTML authoring considerably more structured.
Second, and equally welcome, users will be less likely to see the download dialog when clicking on a link to a file type not established with the operating system. Since the OBJECT container specifies the MIME type, the operating system doesn't need to know how to treat the file type. The browser can be configured to deal with specific OBJECT types through the helper applications area, and ideally Microsoft and Netscape will increasingly perform this configuration in new browser upgrades.
Finally, the OBJECT container makes HTML officially extensible. Browsers need not be rewritten to display new tags; they need only execute the OBJECT tag as designated, and that's a matter of configuration, not source code programming. Note, however, that this new feature does not make the browsers themselves more capable. They can still display only certain file types, so external applications will still be necessary. But it will be more possible than ever for a developer to come up with a new file type, produce a viewer that will display it, offer the viewer as a download, and include links to the viewer, through HTML's OBJECT container.
It's important, however, not to overstate this case. HTML still isn't anywhere near as extensible as XML, which actually defines markup languages, or Document Type Definitions (DTDs); in fact, all of HTML is just a DTD. XML's ability to define new DTDs means it can offer a much stronger variety of parameters than HTML's OBJECT tag ever will. But OBJECT is a start and may ease the flood of proprietary, browser-specific tags.
Compared with the forms in office applications, HTML forms are primitive. They look simplistic and offer little functionality. Designers of HTML forms have had no means of providing features we've come to expect in advanced applications, including such niceties as keyboard shortcuts, interfaces that change as form fields are filled in, labeled buttons, and so on.
HTML 4.0 goes a long way toward offering far more capable forms. Through the access key attribute, for example, designers can provide keyboard shortcuts to each fielda feature that will eliminate some of the constant mouse clicking into fields required in earlier HTML forms. Buttons are now possible beyond Submit and Reset (with the BUTTON element), and you can now gray out buttons through the disabled attribute, a fact that will make filling in forms more intuitive. You can now label form buttons with the LABEL element and use the FIELDSET element to group associated fields together. You can set form fields as read only as well. One extremely useful new attribute is onchange-INPUT, which lets a form verify input strings.
Of course, features like input verification were possible before HTML 4.0, but only through a data exchange with the server. Users had to press the Submit button, then wait for a response telling them whether the input was valid. Forms in HTML 4.0 can assess the input locally, making form use faster and less frustrating.
Like forms, HTML tables have been far more restrictive than tables in databases or spreadsheets. HTML 4.0 offers both considerable flexibility in table layout and enhanced usability. For example, the align attribute offers the standard options for aligning right and left and for centering and justifying, but it now also includes char for aligning text in relation to a character. For instance, using align char, you can line up numbers around decimal points. The frames and rules attributes give you further control over table appearance. Framing is possible around a specified combination of a table's sides (right and left sides only, for instance), and you can place rules between cells, rows, or groups of cells.
In fact, a new element called COLGROUP lets you group columns to apply common width, text direction, style information, alignments, and event instructions. And groups of rows support fixed heads and feet, so that tables can scroll while keeping column headings in place. Furthermore, by placing the THEAD and TFOOT containers before the TBODY container, you cause a table's head and foot to appear before the cells are filled in, helping users understand the table as it is rendered in the browser.
The new <SCRIPT> container gives HTML 4.0 scripting capability. Such a container includes the URL of the script to be rendered plus the scripting language the browser is to use. The two essential scripting languages are JavaScript and VBScript; a document's META element can specify a default language for all scripts in the document, or it can specify the language as a script appears. Scripts can be executed either when the document loads or, using the intrinsic event attributes, whenever a certain event takes place (a mouse click, for example).
The SCRIPT element offers several design possibilities. You can build scripts into forms so that form fields are automatically filled in when a user selects or types a specific value in a field. For instance, date fields could assume a one-day duration, in which case the script would automatically fill in the end-date field after reading the value in the start-date field. You can also use scripts to change the contents of a document as it loads, based on consecutive loading of specified elements. In addition, you can link scripts to buttons, so that an interactive page can have a button-based interface. Because scripts are executed locally, connection with the server isn't necessary.
Frames are an important design element in HTML, but to date they've been restricted to the borders of documents. With HTML 4.0, you can insert a frame inside a block of text, a feature that effectively lets you put one HTML document in the middle of another. The syntax is simple. Here's an example:
<IFRAME src="info.html" width "300"
You can see this example in Figure 7.21. Placed in an HTML document, this code instructs the browser to call the source document (src=filename.html) and display it in the document as a frame of the specified size. All frame attributes are available except "noresize," because in-line frames can't be resized.
HTML 4.0 offers more than described here. One focus has been on internationalization. The global nature of the Web has meant documents in many different human languages, but until now representing international characters has been difficult. HTML 4.0 adopts the internationalization conventions of RFC 2070, "Internationalization of the HyperText Markup Language," and it adopts the standard ISO/IEC:10646 as the document character set. Thus it allows for a larger array of non-Roman characters.
In addition, HTML 4.0 incorporates the Cascading Style Sheets (CSS) initiative. The W3C's goal is to make CSS so attractive that designers will eventually stop using tables for page layout. Even in its earliest incarnation, CSS shows more than enough power to fulfill that goal. Entire document sets can share the same font information, colors, alignments, and other formatting features, and the result is Websites that offer consistent design throughout.
These features suggest a nearly brand-new take on HTML. Version 4.0 lifts many of the old restrictions on extensibility, page layout, interactivity, and indeed the client/server relationship. All of this means that using the Web should start to feel, at last, like a newer, richer experience.122
XHTML
Apparently there won't be an "HTML 5." Why not? Well, bear in mind that HTML was originally designed for a very different environment than today's very demanding hi-tech Internetnamely, exchange of data and documents between scientists associated with CERN, the birthplace of the Web. Since then the language has been hacked and stretched into an unwieldy monster, and the prevalence of sloppy markup practices makes it hard or impossible for some user agents (e.g., browsers, spiders, etc.) to make sense of the Web.
There are increasingly new kinds of browsers: Digital TVs, handhelds, phones and cars, that won't have the processing power of desktop PCs and they will be less able to cope with malformed markup. So there's pressure to subset HTML for simple clients, and there's also pressure to extend HTML for "richer clients" (W3C's terminology for more powerful computers and browsers, not customers with a lot of money). Desires to extend the functionality of the Web will lead to combining HTML with other tag sets: math, vector graphics, e-commerce, metadata, etc. XHTML 1.0 provides the basis for a family of document types that will extend and/or subset XHTML, in order to support a wide range of new devices and applications.
Efforts are underway to define modules and specify a mechanism for combining them. End-users and authors alike will benefit from work on describing the capabilities and user preferences for particular devices, e.g., display characteristics and information on the kinds of graphics formats supported, the HTML modules used, and style sheets support, etc.
The usual reason for upgrading to a new language version is to be able to take advantage of new bells and whistles (and possibly also because problems with the earlier version have been fixed). However, XHTML is a fairly faithful copy of HTML 4, as far as tag functionalities go.
The reasons offered by the World Wide Web Consortium(W3C) are extensibility and portability :
• Extensibility-- XML documents are required to be well-formed (elements nest properly). Under HTML (an SGML application), the addition of a new group of elements requires alteration of the entire DTD. In an XML-based DTD, all that is required is that the new set of elements be internally consistent and well-formed to be added to an existing DTD. This greatly eases the development and integration of new collections of elements.
• Portability-- There will be increasing use of non-desktop devices to access Internet documents. By the year 2002 as much as 75% of Internet access could be carried out on these alternate platforms. In most cases these devices will not have the computing power of a desktop computer, and will not be designed to accommodate ill-formed HTML as current browsers tend to do. In fact, if these non-desktop browsers do not receive well-formed markup (HTML or XHTML), they may simply be unable to display the document.
While HTML isn't completely lacking those attributes, we're all too familiar with how painfully slow the evolution has been (relative to the pace of Internet development), and how hard it can be to make your pages work on a wide range of browsers and platforms. XHTML will help to remedy those problems.
The real benefit of moving to XHTML is a longer-term one than having new gizmos to play with. HTML has been stretched way beyond its original design goals by browser manufacturers who were more interested in proprietary advantage than standards. Also, the language was not that good in the first place, but it served brilliantly to ignite the Web (as did some of those browsers). Much has been learned, and now we have a new meta-language--XML--within which to define new language applications for the web. XHTML is one of them.
XHTML will be most suitable to the construction of new sites where you would like to drop legacy baggage such as the intertwining of content and presentation in HTML, and you want to be well-prepared to move into the 21st century web.123
XML
Since XML was completed in early 1998 by the World Wide Web Consortium, the standard has spread like wildfire through science and into industries ranging from manufacturing to medicine. The enthusiastic response is fueled by a hope that XML will solve some of the Web's biggest problems. These are widely known: the Internet is a speed-of-light network that often moves at a crawl, and although nearly every kind of information is available online, it can be maddeningly difficult to find the one piece you need.
The solution, in theory, is very simple: use tags that say what the information is, not what it looks like. For example, label the parts of an order for a shirt not as boldface, paragraph, row and column--what HTML offers--but as price, size, quantity, and color. A program can then recognize this document as a customer order and do whatever it needs to do: display it one way or display it a different way, put it through a bookkeeping system, or make a new shirt show up on your doorstep tomorrow.
The unifying power of XML arises from a few well-chosen rules. One is that tags almost always come in pairs. Like parentheses, they surround the text to which they apply. And like quotation marks, tag pairs can be nested inside one another to multiple levels.
The nesting rule automatically forces a certain simplicity on every XML document, which takes on the structure known in computer science as a tree. As with a genealogical tree, each graphic and bit of text in the document represents a parent, child, or sibling of some other element; relationships are unambiguous. Trees cannot represent every kind of information, but they can represent most kinds that we need computers to understand. Trees, moreover, are extraordinarily convenient for programmers. If your bank statement is in the form of a tree, it is a simple matter to write a bit of software that will reorder the transactions or display just the cleared checks.
Another source of XML's unifying strength is its reliance on a new standard called Unicode, a character-encoding system that supports intermingling of text in all the world's major languages. In HTML, as in most word processors, a document is generally in one particular language, whether that be English or Japanese or Arabic. If your software cannot read the characters of that language, then you cannot use the document. The situation can be even worse: software made for use in Taiwan often cannot read mainland-Chinese texts because of incompatible encodings. But software that reads XML properly can deal with any combination of any of these character sets. Thus, XML enables exchange of information not only between different computer systems but also across national and cultural boundaries.
An End to the World Wide Wait
As XML spreads, the Web should become noticeably more responsive. At present, computing devices connected to the Web, whether they are powerful desktop computers or tiny pocket planners, cannot do much more than get a form, fill it out, and then swap it back and forth with a Web server until a job is completed. But the structural and semantic information that can be added with XML allows these devices to do a great deal of processing on the spot. That not only will take a big load off Web servers but also should reduce network traffic dramatically.
What XML does is less magical but quite effective nonetheless. It lays down ground rules that clear away a layer of programming details so that people with similar interests can concentrate on the hard part--agreeing on how they want to represent the information they commonly exchange. This is not an easy problem to solve, but it is not a new one, either.
Such agreements will be made, because the proliferation of incompatible computer systems has imposed delays, costs, and confusion on nearly every area of human activity. People want to share ideas and do business without all having to use the same computers--activity-specific interchange languages go a long way toward making that possible. Indeed, a shower of new acronyms ending in "ML" testifies to the inventiveness unleashed by XML in the sciences, in business, and in the scholarly disciplines.
For users, it is what those programs do, not what the descriptions say, that is important. In many cases, people will want software to display XML-encoded information to human readers. But XML tags offer no inherent clues about how the information should look on screen or on paper.
This is actually an advantage for publishers, who would often like to "write once and publish everywhere"to distill the substance of a publication and then pour it into myriad forms, both printed and electronic. XML lets them do this by tagging content to describe its meaning, independent of the display medium. Publishers can then apply rules organized into "style sheets" to reformat the work automatically for various devices. The standard now being developed for XML style sheets is called the Extensible Style Sheet Language, or XSL.
The latest versions of several Web browsers can read an XML document, fetch the appropriate style sheet, and use it to sort and format the information on the screen. The reader might never know that he is looking at XML rather than HTML--except that XML-based sites run faster and are easier to use.
People with visual disabilities gain a free benefit from this approach to publishing. Style sheets will let them render XML into Braille or audible speech. The advantages extend to others as well: commuters who want to surf the Web in their cars may also find it handy to have pages read aloud.
Although the Web has been a boon to science and to scholarship, it is commerce (or rather the expectation of future commercial gain) that has fueled its lightning growth. The recent surge in retail sales over the Web has drawn much attention, but business-to-business commerce is moving on-line at least as quickly. The flow of goods through the manufacturing process, for example, begs for automation. But schemes that rely on complex, direct program-to-program interaction have not worked well in practice because they depend on a uniformity of processing that does not exist.
For centuries, humans have successfully done business by exchanging standardized documents: purchase orders, invoices, manifests, receipt,s and so on. Documents work for commerce because they do not require the parties involved to know about one another's internal procedures. Each record exposes exactly what its recipient needs to know and no more. The exchange of documents is probably the right way to do business online, too. But this was not the job for which HTML was built.
XML, in contrast, was designed for document exchange, and it is becoming clear that universal electronic commerce will rely heavily on a flow of agreements, expressed in millions of XML documents pulsing around the Internet.
Thus, for its users, the XML-powered Web will be faster, friendlier, and a better place to do business. Web site designers, on the other hand, will find it more demanding. Battalions of programmers will be needed to exploit new XML languages to their fullest. And although the day of the self-trained Web hacker is not yet over, the species is endangered. Tomorrow's Web designers will need to be versed not just in the production of words and graphics, but also in the construction of multilayered, interdependent systems of DTDs, data trees, hyperlink structures, metadata, and style sheets--a more robust infrastructure for the Web's second generation.124
New Dialects: CDF, CML, SMIL, SpeechML
Because it can be used to define other languages, XML provides almost limitless scope. Already, it has been used by Microsoft as the basis for its push content format, Channel Definition Format (CDF). XML has also been used to create chemical markup language (CML), a markup language which lets scientists and researchers publish documents containing chemical symbols and formulae. In April of this year the W3C released MathML (mathematical markup language) as the first application of XML that it has recommended.
Yet another XML by-product, synchronized multimedia integration language (SMIL), is waiting in the wings. SMIL will allow developers to produce multimedia presentations on the Web. It lets developers separate text, audio, static images, and video into separate streams, and then combine them. SMIL provides control over the timing of the display of the various streams, much like current presentation software provides in desktop applications.
CDF, CML, MathML, and SMIL signal the beginning of what may turn out to be a flood of XML applications, which will bring new capabilities to the Web. XML languages will offer enormous benefits to vertical markets and specialized industries.
IBM is also talking up a new markup language for speech-enabled browsers. When mature, SpeechML will let Web authors write content for speech-enabled browsers using simple markup tags. Conversational access could broaden Web access from automobiles and telephones and facilitate Web access for the visually impaired. SpeechML, like other XML-based markup languages, attempts to make complicated technologies usable by ordinary Web authors through simple and universally recognized tags. It can parse data from multiple Web sources so that users can go back and forth between speech-enabled and traditional interfaces.
IBM's alphaWorks posting includes a blueprint of the markup language, a conversational browser, and demonstrations.125
If you've tried to keep up with the changes in hypertext markup language over the past three years, you might be under the impression that this vital coding language--the heart of the Web itself--is nothing more than a cobbled-together pastiche of the good, the not-so-good, and the nice-but-only-one-browser-supports-it. And you wouldn't be far wrong. New HTML tags and containers appear with each browser release, and it seems to take forever (in Web terms, at least) for the World Wide Web Consortium (W3C) to incorporate these items into the HTML official specification.
At the same time, there's a danger that these specialized applications will undo one of the key features of the Web as we know it: its broad accessibility.
If the main browser vendors have trouble producing fully HTML-standard-compliant browsers, what will happen when there are dozens of specialized XML-based languages? What will browser vendors themselves do in response to the huge flexibility of XML. If we're bothered by tag proliferation now, what happens when vendors have a tool like XML in their hands?
Style Sheets: Surely but Slowly
At the June 1999 WWW8 session, Bert Bos of the World Wide Web Consortium (W3C) gave a talk in which he discussed the future direction of the Cascading Style Sheet (CSS) specification. First and foremost will be the modularization of CSS. This will entail splitting CSS into several mini-specs, each of which covers a specific topic, such as "Colors and Backgrounds," "Selectors and Syntax," or "Printing."
The benefits of this approach, as described by Bos, are an increased responsiveness on the part of the CSS Working Group, and greater flexibility for implementers. Splitting CSS into modules will allow implementers to tackle a module at a time, and then claim support for that module once they've correctly implemented the properties and behaviors described in a given module.
For example, with positioning in its own module, implementers can claim support for CSS positioning or aural styles, without necessarily having to worry about other modules. This will free implementers from worrying that the lack of a single property (or set of properties) will keep them from being able to claim, for example, full CSS2 support. Of course, there won't be as much pressure to claim full and complete CSS2 support because the focus will be more on who has implemented which modules.
The other advantage, which is mentioned above, is that the working group can be much more responsive to market changes and user demand. At the present time, the only way to make changes or additions to any part of the CSS specification is to get a new level out the door. For example, if everyone agreed that a new printing property should be added to CSS, it would have to wait until CSS3 were finished and released--in other words, lots of new features wait for the completion of the entire specification.
And what new changes might be in the works? In his talk, Bos mentioned two things which seemed likely to be added to CSS. First was transparency (or opacity), which is the ability to set a degree of transparency on the foreground of elements. In other words, you could make the text in a paragraph semi-transparent, allowing the background to "shine through" the text (or be composited together, if you prefer graphic-design terminology). The other was multi-column text, although there were no details given on how this feature might be accomplished.126
XSL (extensible stylesheet language) is being developed as part of the W3C Style Sheets Activity: "W3C continues to work with its members, evolving the Cascading Style Sheets (CSS) language to provide even richer stylistic control, and to ensure consistency of implementations. W3C is also developing the Extensible Stylesheet Language (XSL), which has document manipulation capabilities beyond styling." The W3C Style Sheets Activity is itself part of the W3C User Interface Domain.
"The XSL specification--at present [July 1999] in Working Draft stage--has been split into two separate documents. The first deals with the syntax and semantics for XSL, applying `style sheets' to transform one document into another." To quote from the XSLT Working Draft: "XSLT is a language for transforming XML documents into other XML documents. XSLT is designed for use as part of XSL, which is a style sheet language for XML. In addition to XSLT, XSL includes an XML vocabulary for specifying formatting. XSL specifies the styling of an XML document by using XSLT to describe how the document is transformed into another XML document that uses the formatting vocabulary. XSLT is also designed to be used independently of XSL. However, XSLT is not intended as a completely general-purpose XML transformation language. Rather it is designed primarily for the kinds of transformation that are needed when XSLT is used as part of XSL."127
"Meanwhile the second part is concerned with the XSL formatting objects, their attributes, and how they can be combined." XSL is a far more sophisticated style language than is CSS. XSL draws on earlier specifications including CSS and DSSSL. According to the W3C's XSL page, Extensible Style sheet Language (XSL) is a language for expressing style sheets. It consists of two parts:
(1) A language for transforming XML documents.
(2) An XML vocabulary for specifying formatting semantics.
An XSL style sheet specifies the presentation of a class of XML documents by describing how an instance of the class is transformed into an XML document that uses the formatting vocabulary." In other words, a style sheet tells a processor how to convert logical structures (the source XML document represented as a tree) into a presentational structure (the result tree). Note that an XSL style sheet is actually an XML document!
It is important to understand that the transformation part can be used independently of the formatting semantics. Common transformations include converting XML to HTML, changing the order of elements, and selectively processing elements. In fact, as of early 1999, most XSL implementations support only the transformation part of the Working Draft; they do not address the formatting objects at all! This may be confusing if you view XSL as mainly for rendering style.128
"The formatting objects used in XSL are based on prior work on CSS and DSSSLthe Document Style Semantics & Specification Language. XSL is designed to be easier to use than DSSSL, which was only for use by expert programmers. Nonetheless, in practice it is expected that people will use tools to simplify the task of creating XSL style sheets." A separate working draft specification, XPath (XML Path Language) "is a language for addressing parts of an XML document designed to be used by both XSLT and XPointer. XPath is the result of an effort to provide a common syntax and semantics for functionality shared between XSL Transformations and XPointer."
According to the Activity description [July 1999], "XSL is a language quite different from CSS, and caters for different needs. The model used by XSL for rendering documents on the screen builds upon many years of work on a complex ISO-standard style language called DSSSL. Aimed, by and large, at complex documentation projects, XSL has many uses associated with the automatic generation of tables of contents, indexes, reports, and other more complex publishing tasks."
Why Two Style Sheet Languages?
"The fact that W3C has started developing XSL in addition to CSS has caused some confusion. Why develop a second style sheet language when implementers haven't even finished the first one?... The unique features are that CSS can be used to style HTML documents. XSL, on the other hand, is able to transform documents. For example, XSL can be used to transform XML data into HTML/CSS documents on the Web server. This way, the two languages complement each other and can be used together. Both languages can be used to style XML documents. CSS and XSL will use the same underlying formatting model, and designers will, therefore, have access to the same formatting features in both languages. W3C will work hard to ensure that interoperable implementations of the formatting model is available."129
Beyond XML
From the outset, part of the XML project has been to create a sister standard for metadata. The Resource Description Framework (RDF), finished this past February, should do for Web data what catalog cards do for library books. Deployed across the Web, RDF metadata will make retrieval far faster and more accurate than it is now. Because the Web has no librarians and every Webmaster wants, above all else, to be found, we expect that RDF will achieve a typically astonishing Internet growth rate once its power becomes apparent.
One of the drawbacks of HTML is that HTML tags relate only symbols rather than attributes of what the symbols depict. For example, HTML tags tell us how to display the word "eyes" in a Web document but there are no tags related to attributes such as eye color, eye size, vision quality, and susceptibility to various eye diseases.
For example, HTML tags relate only to formatting and linking tags on words red and purple appearing in a document. HTML tags do not disclose that both words depict colors, because HTML does not associate words with meanings. Metadata, on the other hand, attaches meanings to the data by attaching hidden attribute tags. For example, attached to the word "petal" might be an invisible tag that records information that the petal has color coded numbers for color hue and color saturation for rose petals. When any petal's invisible tags are read in a meta search engine, it would be possible to identify types of roses having a range of hue and saturation commonalties. Poppies would be excluded because they do not have rose tags. Red herrings (a term for false leads in a mystery) would be excluded because they do not have a tagged attribute for color .
In a sense, metadata is analogous to genetic coding of a living organism. Attributes in hidden tags become analogous to attributes coded into genes that determine the color of a flower's petals, degree of resistance to certain diseases, etc. If we knew the genetic "metadata" code of all flowering plants, we could quickly isolate the subsets of all known flowering plants having red petals or resistance to a particular plant disease. In botany and genetics, the problem lies is discovering the metadata codes that nature has already programmed into the genes. In computer documents and databases, the problem is one of programming in the metadata codes that will conform to a world wide standard. That standard will most likely be the RDF standard that is currently being developed by the World Wide Web Consortium.
The core of RDF will be its "RDF Schema" briefly described below:
This specification will be followed by other documents that will complete the framework. Most importantly, to facilitate the definition of metadata, RDF will have a class system much like many object-oriented programming and modeling systems. A collection of classes (typically authored for a specific purpose or domain) is called a schema. Classes are organized in a hierarchy, and offer extensibility through subclass refinement. This way, in order to create a schema slightly different from an existing one, it is not necessary to "reinvent the wheel" but one can just provide incremental modifications to the base schema. Through the sharability of schemas RDF will support the reusability of metadata definitions. Due to RDF's incremental extensibility, agents processing metadata will be able to trace the origins of schemata they are unfamiliar with back to known schemata and perform meaningful actions on metadata they weren't originally designed to process. The sharability and extensibility of RDF also allows metadata authors to use multiple inheritance to "mix" definitions, to provide multiple views to their data, leveraging work done by others. In addition, it is possible to create RDF instance data based on multiple schemata from multiple sources (i.e., "interleaving" different types of metadata). Schemas may themselves be written in RDF; a companion document to this specification describes one set of properties and classes for describing RDF schemas. (Emphasis added).130
The term "metadata" is not synonymous with RDF. There were various metadata systems before RDF was on the drawing boards. Microsoft's Channel Definition Format (CDF) used in "Web Push Channels" and Netscape's Meta Content Framework (MCF) preceded RDF. These technologies describe information resources in a manner somewhat similar to RDF and can be used to filter Web ites and Web documents such as filtering pornography and violence from viewing. Metadata systems can be used to channel inflows of desired or undesired Web information. CDF, for example, carries information not read on computer screens that perform metadata tasks.131
Web Agents: Data that Knows About Me
A future domain for XML applications will arise when intelligent Web agents begin to make larger demands for structured data than can easily be conveyed by HTML. Perhaps the earliest applications in this category will be those in which user preferences must be represented in a standard way to mass media providers. The key requirements for such applications have been summed up by Matthew Fuchs of Disney Imagineering: "Information needs to know about itself, and information needs to know about me."
Consider a personalized TV guide for the fabled 500-channel cable TV system. A personalized TV guide that works across the entire spectrum of possible providers requires not only that the user's preferences and other characteristics (educational level, interest, profession, age, visual acuity) be specified in a standard, vendor-independent mannerobviously a job for an industry-standard markup systembut also that the programs themselves be described in a way that allows agents to intelligently select the ones most likely to be of interest to the user. This second requirement can be met only by a standardized system that uses many specialized tags to convey specific attributes of a particular program offering (subject category, audience category, leading actors, length, date made, critical rating, specialized content, language, etc.). Exactly the same requirements would apply to customized newspapers and many other applications in which information selection is tailored to the individual user.
While such applications still lie over the horizon, it is obvious that they will play an increasingly important role in our lives and that their implementation will require XML-like data in order to function interoperably and thereby allow intelligent Web agents to compete effectively in an open market.132
XML really only began in 1996. It is young and immature. And important associated specifications such as eXtensible Style Sheets (XSL) and the Resource Description Framework (RDF) Model are younger still.
The common mantra of XML is that it separates content from presentation. That is a major difference vs. HTML. You can use XML to direct a markup language to, in effect, define in-house data handling methods. It allows you to "normalize" varied data input sources to allow complex data handling. You can also band with others to define standards. Or you can use accepted vertical or horizontal standards that industry groups or vendors manage to agree upon. Acting as a meta format, and perhaps residing in style sheets sitting in "the great repository in the sky" (the World Wide Web), XML allows you to change the definitions of tags as you go forward. Because it is so fluid and decentralized, it is powerful.
And while flexibility is an XML strength, it can also be a weakness. The idea that XML is a revolutionary paradigm shift will naturally be challenged. Any notion that all existing middleware will suddenly give way to XML is silly.
The Object Management Group (OMG), Framingham, Massachusetts, for example, points this out in a recent white paper on XML. "Every now and then, the computer industry gets swept up in a wave of enthusiasm for some new silver bullet that's apparently going to solve everyone's problems overnight," writes the OMG. "[XML] isn't going to replace solutions like CORBA." The paper outlines XML's roots in markup languages, and notes that because document content in XML applications are generally human-readable scripts, XML is likely "a rather inefficient way of storing information that only ever needs to be machine-readable."
This is a real issue. Truly, it seems early in the game to begin to measure how good XML performance may be. But the XML effort is, at heart, an attempt to make the World Wide Web more machine understandable. And the type of stricture that CORBA-style object programming brings to the table is not widely found in legacy systems. "Objects are structured. Much of the world isn't. A lot of what we have to do is apply structure to data that doesn't have it," said Dave Robertson, product marketing manager at Redwood Shores, California-based Constellar Corp., a data hub middleware maker.
Even within the OMG, some use of XML is proposed, at least as a meta data mechanism. OMG members IBM, Unisys and Oracle are suggesting use of XML (integrated with another "ML," the UMLthe Unified Modeling Language) and the Meta Object Facility (MOF) as an information interchange model for application developers. In fact, this use of XML in a metadata format (this particular proposal is known as XMI), is one of the first big signs of XML's use in application development.
"There is a broad spectrum of descriptive data that we have to handle," said Peter Thomas, product manager for repository technology at Redwood Shores, California-based Oracle Corporation. "XMI is an extensible format, so it can be used to handle [new] cases. We think it will expand over time." An IBM representative said XML use means software developers no longer have to resort to proprietary mechanisms to format the data they are storing in databases or passing between applications.
It is rather forgotten at times that Tim Berners-Lee had a background in object software technology well before he invented the World Wide Web in 1990. And his goal, in great part, was to allow information sharing within dispersed teams of advanced physics researchers and support groups. Much of his work today as the director of the World Wide Consortium (http://www.w3.org) centers on XML as a means of extending the exchange of data on the Web.
At the recent Seybold Publishing '99 Conference in Boston, Application Development Trends asked Berners-Lee what application developers should know about XML. He responded: "Application developers should be using XML and RDF not just for Web pages, but also for storing internal files such as configuration files and, in general, data for exchange."
He continued: "This will allow users to reduce their lock-in to proprietary formats, and allow them to customize parts of their system while retaining off-the-shelf products for other parts."
And there is no need to put off some initial work on this effort, maintains Berners-Lee. "...They should also be looking at the upcoming XHTML specification as a transition from HTML 4.0 to HTMLas XML." In February, the Consortium formally released its RDF specification as a W3C Recommendation.
In the past, complex object models for both development and deployment have stumbled in finding suitable repository technology. Berners-Lee would be undeterred. At last year's DCI World e-Business Conference in Boston, he noted: "When people say we need a repository, we say we have the Web." A repository should be decentralized, he said. Based simply on his success with the Web, his statement is hard to counter.
At that same conference, Berners-Lee described XML as "a great pressure-release valve." This is by way of testament to its ability to support change.
XML's potential has not been lost on industry playersbig or small. Among the lot of large vendor XML initiatives are twofrom IBM and Microsoftthat might prove helpful in propelling XML forward.
Microsoft has helped move XML to the forefront via its new browser technology. Internet Explorer 5.0 is said to support XML as well as the XSL that allows developers to apply style sheets to XML data. While it is now out of beta, browser makers and document builders are still working from fresh specs, and a shaking out period should still be expected as folks try to get XML to work consistently. Among early beta users of Microsoft's XML implementation is Merrill Lynch & Co., which is using XML to improve development time, usability, data mining, and software distribution.
For its part, IBM continues to produce a variety of tools. Editors, transformers, parsers, and Bean makers are just a few of the offerings available as downloadable technology previews at the IBM alphaWorks Web site (http://www.alphaworks.ibm.com/). Last month, IBM added Xeena, a syntax-smart Java application for editing valid XML according to a chosen DTD. XML tools will reportedly become part of future IBM WebSphere development environments, with application integration as one of its uses. Last month, IBM announced a deal with The Sabre Group and Noika to build an interactive service. Sabre is writing a Java application to translate its travel data into XML so that streams of data can be defined and presented as individual objects such as airline reservations. (Wireless house Noika will use IBM software to translate the XML into what is described as a Wireless Markup Language or WML.)
While support of big players is important, it is a cast of smaller companies that have set the XML industry in motion. These can be divided, somewhat arbitrarily, into text-document specialists, data and application development specialists, and (proving that miscellany still rules) XML- or Web-centric start-ups.
Among text specialists are Arbortext Inc., Interleaf Inc. (which just bought XML specialty house Texcel Research Inc.), OmniMark Technologies Inc., OpenText Corp., Softquad Software Inc., and many more.
Among the new breed of companies formed to exploit Web-technology opportunities that are finding XML a means to that end: DataChannel Inc., LivePage Corp., Perspecta Inc., Sequoia Software Corp., UWI.com, Vignette Corp., WebMethods Inc., and others.
Among data and application development specialists, Bluestone Software Inc., Cloudscape Inc., Inference Corp., Kinetic Technologies Inc., Object Design Inc., Poet Software Corp. and others are joining daily. Among this last camp, some notable XML application development-oriented tools have already been released this year. In February, Mount Laurel, New Jersey-based Bluestone released Bluestone XML-Server. And in March, Burlington, Massachusetts-based Object Design announced general availability of eXcelon, an XML data server.
"eXcelon makes it easier to work with XML," said early eXcelon user Srini Sankaran, president of Global Automation, a Palo Alto, California-based system integrator specializing in distributed application integration. "It provides mapping and some validation. Moreover, it provides scalability."
Is XML revolutionary, we asked. "I don't think it's revolutionary," replied Sankaran. "It's really an evolution of SGML for the Web. But its impact is going to be pretty significant. It's a very natural solution for the problems of the Web industry."133
Going Forward
Everyone recalls creating their first Web page by adding a few HTML tags to an ASCII file using a text editor. Within five minutes, they had created and published a document that could be read by people all over the world. That experience was inspiring, pointing immediately to the importance of the Web, but it was deceiving. We now expect professional quality user interfaces for even static Websites, and developing realistic interactive applications is as difficult on the Web as in-house. We need increasingly powerful development tools and comprehensive general-purpose application servers as applications become complex.
Applications have become more numerous as well as more complex. We have progressed from our first "hello world" test pages to vast Websites with many applications, documents, developers, versions, locations, languages, etc. Furthermore, the value of the information assets we are managing has increased dramatically and continues to rise. Such an environment can quickly get out of control without tools to organize and manage development.134
The Web-authoring tool market is fiercely competitive, which is good news if you're looking to replace outdated software. Most of these products sell for around $100, an easy price to swallow, especially if you are responsible for buying multiple copies for your company's Web team. You'll need to fork out more cash for NetObjects Fusion and Dreamweaver, but these tools offer extra sophistication and features that justify the steeper price tag. All of these companies except Corel let you download a demo version of their product from the vendor's Website so you can check it out before you buy.
The HTML authoring tool market is maturing, and authoring tools are finally offering sufficient features to alleviate the need to dip into underlying HTML code. Even better, some tools are beginning to take a more global view of Web pages, providing ways to manage an entire site as a collection of related documents. The bottom line with the new generation of Web-authoring tools is a wider array of much higher-quality products. Companies and coders alike can no longer regard these tools as toys.135
Forecasts and Markets
Multimedia has been in development since the mid-1980s, but it was not until the first half of the 1990s that the concept became reality. A marketplace full of tools has emerged which enable applications developers to integrate text, graphics, video, animation, and sound into a computing environment.
The marketplace has had a chance to evolve, and end-users are now aware of the impact multimedia can have on a range of applications such as training, education, business presentations, and home entertainment. As end-users embrace multimedia, hardware and software vendors can lower prices and put more effort into research and development. The cycle of supply and demand necessary for a market to grow rapidly is in place.
Figure 7.22. Forecast Revenue for Multimedia Applications, By Category
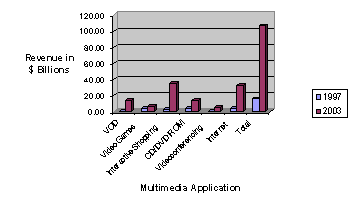
Source: New Media Insight Research (March 1, 1999)
Figure 7.23. Forecast Market for Multimedia Services, Including Internet Access and
Online Services
Source: Computer Reseller News (August 24, 1998)
Figure 7.24. Forecast Market for Multimedia Software, U.S.
Source: Computer Reseller News (August 17, 1998)
Table 7.14. Windows-Based Web-Authoring Software Shipments and Revenue, 1997, Worldwide
Table 7.15. Macintosh-based Web-Authoring Software Shipments and Revenue, 1997,
Worldwide
Source: IDC 136
Industry/Technology Roadmaps
Rapid Changes Drive Internet Deployment137
If you are a business or information technology executive, you may feel as if the Internet has hit you broadside with its panoply of new technologies and possibilities. Unless you, or somebody in your department, can interpret these fast-paced innovations, you may find yourself quickly overwhelmed.
Do you find yourself suffering from "paralysis by analysis" merely trying to keep up with the newest developments? An analysis of over 5,200 Internet-related developments over the first two months of 1996 revealed that only 14% of them were significant enough for business executives and Internet professionals. To add to the confusion, here is a list of technologies you need to stay on top of:
• Client browsers and viewers.
• Java & Java accessories and add-ons.
• Payments and electronic currencies systems.
• Web servers collection: commerce, security, publishing, transaction, merchant, communications, catalog, mail, news, proxy.
• Web applications development tools.
• Security software and hardware (including firewalls, tunnels, routers, etc.).
• Multimedia authoring tools and publishing tools.
Demystifying Internet Market Players
Another approach is to break down the Internet into general market players segments, which allows you to develop the most appropriate strategy for each segment you plan to target. The following three segments include all players:
Enablers and developers: These are the organizations that provide the tools and capabilities to enable the creation of valuable content and information services for the Internet. This includes Internet-infrastructure building and management, applications development languages and tools, security and payment mechanisms, and computer and networking hardware. They primarily consist of software and hardware companies, access providers, telephone companies, systems integrators, and consultants.
Figure 7.25. Internet Market
Players
 Providers and Sellers: These are the organizations and businesses that treat the Internet like a market. They use the tools and capabilities of enablers and developers by introducing Internet services of value to their customers. These services are tuned for each industry like manufacturing, retail, financial services, media/entertainment, publishing, real estate, government, etc... There is also a flurry of new businesses that are so co-dependent on the Internet that they would not exist in their current forms without it. These include buyers/sellers services like Industry.Net, directories like Yahoo!, InfoSeek, and OpenText; information publishing engines like NewsPage and Quote.Com; shopping malls like the Internet Shopping Network, marketplaceMCI, or Barclay Square; and storefronts set-up directly by manufacturers like Digital Equipment, Sun Microsystems.
Providers and Sellers: These are the organizations and businesses that treat the Internet like a market. They use the tools and capabilities of enablers and developers by introducing Internet services of value to their customers. These services are tuned for each industry like manufacturing, retail, financial services, media/entertainment, publishing, real estate, government, etc... There is also a flurry of new businesses that are so co-dependent on the Internet that they would not exist in their current forms without it. These include buyers/sellers services like Industry.Net, directories like Yahoo!, InfoSeek, and OpenText; information publishing engines like NewsPage and Quote.Com; shopping malls like the Internet Shopping Network, marketplaceMCI, or Barclay Square; and storefronts set-up directly by manufacturers like Digital Equipment, Sun Microsystems.
Users and buyers: First, on the consumer side, are home consumers, employees at work, and students at schools and universities accessing the Internet to buy something or use the Internet for research purposes. Second, on the corporate side, are the organizations that are conducting business-to-business transactions over the Internet.
Having figured out what technologies exist, and who is playing in this marketplace, it is your turn to get serious and plan for your own strategy. Without being overwhelmed or intimidated by the flood of new Internet technology and jargon, business managers should treat Internet planning with the same discipline they bring to corporate planning.
Where do you start and how much do you spend in which areas? What are the various stages of evolution for Internet deployment within your organization? We suggest an evolutionary approach that grows according to an organization's maturing, and increased facility capabilities with the Internet, coupled with the return on their investment expectations.
Access: If you are serious about the Internet, you must first and foremost provide Internet access to all your employees. Depending on the size and type of organization you are, this may be as simple as going with a local Internet access provider, or as complex as building a corporate-wide infrastructure based on the public Internet, but with private gateways and access areas secure enough to maintain privacy. Basically, you would be allowing your employees to begin to understand and get educated about the possibilities and capabilities of the Internet. You will have more informed employees that will in turn begin to imagine the many ways that the Internet can help them specifically in their organizations. The goal here is simple: connect everybody! This is the minimum acceptable today.
Presence: In this stage, somebody in your organization has awakened to the World Wide Web, and decided that it is time to keep up with the WWWs, and develop a corporate presence on the Internet. The short-term goal, in this case, is to create beautiful Web pages, and overachieve on the creative artistic talents of graphic designers. Most of these efforts are usually driven by the marketing or PR departments, and even though valuable to an organization, do not exploit the Internet to its maximum potential, because it is treated like a medium as opposed to like a market. Many organizations fall in this trap, stay in it, and don't know how to evolve the strategy into the next phase, which is critical turning point.
Figure 7.26. Seizing the Internet for the Long Term
 Services introduction: An initial approach is to recognize that the Internet can be used as a delivery vehicle for replacing an existing process more efficiently. For exam-ple, disseminating company infor-mation to employees over an "Intranet" platform is quicker and more cost effective than printing, mailing and waiting for the information to arrive. In other cases, a company such as FedEx can decide to simplify the package tracking process for their clients by linking this information to them and making it available over the Internet as a point of entry. FedEx is avoiding thousands of daily calls to their 1-800 call centers, therefore avoiding costs.
Services introduction: An initial approach is to recognize that the Internet can be used as a delivery vehicle for replacing an existing process more efficiently. For exam-ple, disseminating company infor-mation to employees over an "Intranet" platform is quicker and more cost effective than printing, mailing and waiting for the information to arrive. In other cases, a company such as FedEx can decide to simplify the package tracking process for their clients by linking this information to them and making it available over the Internet as a point of entry. FedEx is avoiding thousands of daily calls to their 1-800 call centers, therefore avoiding costs.
Business process integration: The goal here is to really begin to integrate the Internet within the enterprise by seriously allowing specific implementations to permeate the organization and change older processes. Citing the Federal Express example, they have recently evolved the Internet capabilities for their clients by allowing them to even prepare and request shipping a package straight from the Internet. This step is an important entry into electronic commerce.
Business transformation: Finally, here the Internet becomes mission-critical to the business and generates a substantial revenue base. The applications that drive this stage have been specifically written from the bottom up for the Internet. This being an advanced stage of Internet integration, it carries prerequisites and is a long-term objective that organizations can strive towards. This exemplifies the creation of entirely new and different businesses that wouldn't exist before, without the internetworked capabilities of the Internet.
Roadmap for Java Software Products
Sun Microsystems, Inc. today (December 8, 1998) announced a roadmap for its Java software products leveraging the Java 2 platform. The Java 2 platform, formerly code-named "JDK 1.2," is a stable, secure, and powerful environment for the development and deployment of mission-critical solutions.
Sun's enterprise software products supporting the Java 2 platform include a complete line of servers and tools. Together, they enable customers to build more scalable, flexible, and open enterprise applications that scale from embedded devices to mainframes and create enterprise portals for competitive business advantage in the new, networked economy.
"With the addition of support for the Java 2 platform, Sun's end-to-end solutions have never been stronger," said Jonathan Schwartz, director of enterprise products for Sun Microsystems, Inc.'s Java Software. "With a complete product line--spanning a powerful application server suite, pervasive legacy access, right down to the browser--we're leading the market in delivering next-generation business systems."
Enterprise Java products leveraging the Java 2 platform and date of availability are shown in Table 7.16.
Sun's NetDynamics application server is a Java- and CORBA-based application server that provides high performance, scalability, and high availability for distributed network applications. Sun's NetDynamics Studio is a complete development environment tuned to the NetDynamics application server's extensive Java component framework and automatically generates client or server-side Java applications from a visual development environment.
The Java Web Server offers servlet development for creating dynamic Websites, alleviating the need to port old CGI scripts in addition to providing complete extensibility, maximum security, and easy-to-use administration. The Java Embedded Server, a new class of server that resides on the device, is the latest in the evolution of intelligent devices. It provides dynamic, real-time, life-cycle control for the creation, deployment, and installation of applications and services, and redefines the deployment and use of services in the new technological paradigm of embedded intelligent systems.
The HotJava Browser is a lightweight, highly customizable solution for OEMs and developers creating Web-enabled devices and applications. HotJava Browser's small footprint makes it an ideal, scalable solution for a variety of devices.
JavaLoad software is the industry's first and only cross-platform testing tool to enable end-to-end load testing of enterprise applications across large heterogeneous computing environments. Since JavaLoad is written in the Java programming language, system developers and quality assurance engineers can easily test both native and Java applications at every tier of the system.
The award-winning Java WorkShop software is a powerful, integrated development tool that provides a complete, easy-to-use tool set for building JavaBeans, Java applets, servlets, and applications quickly and easily.
Java Blend software provides enterprise customers with powerful Java technology for simplifying database application development. Java Blend contains a tool and a runtime environment that makes it easy to build business applications that integrate Java objects with enterprise data.138
Risk Factors
High-end, rich content authoring is a delicate struggle, a wrestling together of highly disparate source media and arranging all of these elements to form a coherent whole. Consider the scenario of putting together all of the audio elements for a film soundtrack: this involves transferring all of the music tracks, the ambient sound tracks, the performer's dialogue, and the Foley effects from their original source, remixing or editing all of them, and doing split-second synchronizations to the motion picture elements. This process requires a lot of information about each audio source element, as well as information about other media associated with it at the moment of playback. The media industry uses a wide range of source materials, as well as a set of highly varied capture tools with very different constraints (cameras, keyboards, audio input sources, scanners). This wide variety leads to a great deal of time and effort spent converting media into formats that can be used by the wide variety of authoring applications. Other issues include synchronization accuracy for time-based media (film, video, audio, animation), operating system and hardware dependencies for interactive media titles, and download, streaming, and playback performance in Internet media applications.
The Society of Motion Picture and Television Engineers (SMPTE) has addressed these problems in the dedicated hardware world by creating a set of standards that has worked very well through its history. Computer-based media tool vendors have come up with many varied, mostly proprietary approaches that all have many strengths as well as weaknesses. As digital technology for media capture, editing, compositing, authoring, and distribution approaches ubiquity, the industry demands better interoperability and standard practices.
Digital Media File Formats and Issues
Rich media authoring often involves manipulating several types of digital media files concurrently and managing interactions and relationships between them. These types of media generally fall into the following categories:
Despite the relatively small number of categories, the sheer number of available digital media file formats, each with its own strength or specific quality (i.e., preferred compression codec, optimized file size, preferred color resolution, support for transparency, support for sequential display, analog-to-digital fidelity, or operating system platform), results in many file-format-to-file- format conversions to produce a high-quality end product. The following formats are just a few of the many in use today:
AVI and WAV files are widely used Microsoft media containers for video and audio, but they do not support the storage of compositional information or ancillary data such as SMPTE timecode. Microsoft DirectX files are optimized for 3-D images, but do not support other time-varying media formats as well as AVI and WAV. Open Media Framework Interchange files (OMFI), developed by Avid Technology, Inc., is a good step in the direction of interchange, but it has not been widely adopted by other imaging tools vendors.
The Advanced Streaming Format, or ASF, is a new file format developed by Microsoft for the delivery of streaming media programs over limited-bandwidth connections. While it meets many of the needs of this market, content creation file formats have differing needs. The Adobe Photoshop (PSD) file format is used for storage of still image compositions and related metadata information. While being recognized by many content-creation applications for images, it has limited capabilities for other media data types.
The multimedia content authoring process generally involves 1) opening one or more source media files, 2) manipulating or editing the media, and 3) saving the results. Multimedia authoring applications read and manipulate certain types of data and save the resulting file to their own proprietary format, usually specific to a particular hardware platform or operating system. This closed approach generally makes the reuse or repurposing of media extremely difficult. In particular, the compositional metadata (the data that describes the construction of the composition and not the actual media data itself) is not transferable between authoring applications.
For example, using DigiDesign's Pro Tools, an audio engineer might be recording, editing and mixing the sound for a video. She could record or load the source media tracks, do gain normalization, and then mix the tracks while applying pan, volume, and time compression transforms to the individual tracks. When the work is complete, she can save the files in two different formats. One format is Pro Tools' native file format, the Sound Designer 2 audio file (SD2F), which is the transformed output file information (with a little bit of metadata available in the resource fork such as number of channels or sampling frequency). The second format is the Pro Tools Session Files format, which saves the metadata information (edit decisions, volume gradient transforms, audio processing) separate from the original source media, allowing for additional changes to be made to the sound output in a non-destructive fashion.
If the authoring application saves the resulting media information as a single, "flattened" file, then changes cannot be made without going through all of the steps and processes involved (edits, etc.) Users may spend much time and energy re-converting and transferring information and reentering instructions, and ultimately rewriting the entire file.
If the authoring application saves the editing and transform data separately from the media data, then the media can be changed directly by a sound editing application without having to open the authoring application. However, the metadata (data used to describe any compositional positioning, layering, playback behavior, editing cut lists, media mixing or manipulation, etc.) is not accessible without opening the authoring application.
In an ideal environment a user would be able to use many different applications and not be concerned with interchange. The media data and the decisions made in one application would be visible to a user in another application.
COTS Analysis
Adobe
In the page layout realm, Adobe announced they will release their new cross-media publishing solution, InDesign (formerly codenamed "K2"), this summer. InDesign is aimed straight at Quark's page-layout jugular and features an open architecture and seamless integration with other Adobe products like Illustrator and Photoshop. The core program of InDesign takes up only 1.6MB of RAMmost functions are available through plug-ins that are added to the program.
InDesign will be geared toward professional users and will go head-to-head with QuarkXPress, while PageMaker 6.5 Plusreleased in mid-Marchis now aimed at businesses with no graphic design departments. PageMaker 6.5 Plus features stock illustrations and photos, and professionally-designed templates. It comes with a limited edition of Photoshop. The Windows version offers several enhancements not available in the Mac version, such as a picture palette and template browser.139
Composer
Composer is part of the Netscape Communicator suite, which includes the popular Navigator 4.0 browser. Composer is the most basic of the page editors reviewed. In fact, it's too basic; Composer can only create the simplest Web pages consisting of text and an image or two, and there is no room for expanding a user's knowledge of HTML or the Web.
The interface is simple and clean enough, much like that of a basic word processor. There are a bunch of text buttons at the top of the screen for inserting elements such as "target" (for an anchor), link, table, and "h line" (for horizontal rule). Unfortunately, you can't insert more complexyet vitalitems such as frames and forms, and the product only lets you work on one page at a time; like a browser, it opens a new editor each time you load a page. Documentation is scarce as well.
Because of these drawbacks, and because the general feel of the product is that of an add-on to Communicator rather than an essential part like Navigator, it's hard to imagine either a beginner or pro using Composer as a primary HTML editing tool. Instead, it might be more useful as an updated version of Windows Notepad: for typing in text to get instant HTML, for instance, or making "sketches" for a Web page design that will get fleshed out elsewhere.
The HTML that Composer generates is usable enough; the demo page we put together, though lacking frames and forms, didn't turn up any mysterious tags or attributes. The tables the program created were smooth enough, though some indentation in the HTML code would make it easier to read and work with. Composer easily passed the test of creating a table that holds images to touch exactly. Changing the background color of table cells is as easy as right-clicking your mouse.
Ultimately, Composer just isn't robust enough to compare with the other tools in this roundup. Unless your taste in Web pages runs to the most basic, you're better off looking elsewhere.
Dreamweaver
Dreamweaver, from Macromedia, Inc., is one of the newest entries in the Web-authoring market. The tool is aimed at experienced designers and HTML coders who want fine control over their code as well as cutting-edge features like CSS and DHTML.
Dreamweaver is attractive to page builders who use non-WYSIWYG editors like BBEdit or HomeSite. When you're working on a page in Dreamweaver, a mouse click takes you to the external HTML editor of your choice (or one of the products bundled). Upon exiting the external editor, your code is imported back into Dreamweaver and your page updates automatically.
Another lure of Dreamweaver is that the tool is highly customizable. A group building a Web site, for instance, can create a library of common elements, called "repeating elements," that can be easily shared. A "behavior" feature creates interactive JavaScript without writing code; designers can add their favorite chunks of JavaScript so that anyone in a group can use the code when needed. The tool also has powerful CSS support that lets you create style sheets to use over an entire site without any code-crunching.
FrontPage 98
Unlike some of the other products in Microsoft's Internet family, FrontPage isn't playing catch-up; it is clearly one of the leaders. This product is robust, featuring a variety of detailed dialog boxes that give you precise control over page layout as well as access to some of the most current features available on the Web.
Creating a page with all of the elements on our test page is quite easy with FrontPage 98, whether you are a power user or a novice. When creating frames, FrontPage gives you a slew of choices on different layouts. Once you select a frameset, a simple right mouse click lets you edit the frames' properties. The right mouse click is very powerful throughout FrontPage; it brings up a contextual menu for whatever page element your mouse has highlighted.
FrontPage has the best table creation of any of the tools tested. You can put together a graphical "quick table" by selecting the number of columns and rows you want on a basic grid. The more interesting, and versatile, way to create a table in FrontPage is with a "pencil" tool that allows you to draw the table you want (an "eraser" tool deletes unwanted cells). The tool also has buttons to merge and align cells and to distribute space equally. In the test we used to create a table that holds images that touch exactly, FrontPage did a flawless job.
Besides covering the basics, FrontPage also supports next-generation Web page features like CSS and DHTML that are indigenous to Internet Explorer 4.0. The software offers a number of ActiveX controls that you can insert into your page to add multimedia effects. FrontPage also has advanced Java applet insertion control. The only major caveat with these whiz-bang features is that they target Microsoft's Web browser, leaving you guessing as to which ones work with Netscape or other browsers.
Fusion 2.0.2
Fusion from NetObjects, Inc. is aimed at designers who don't want to look at HTML code or deal with potentially hairy issues like Unix file structures. The product works best when you want to create an entire Web site, such as a large corporate site with many repeating elements and complex site navigation, rather than individual pages. To create a single page or two (such as our test page), you have to steer clear of many of Fusion's site-layout features.
One of the most important good news/bad news aspects of this tool is its "master borders" feature. For example, if a site has a navigation bar at the left side of each page, you can create that navigation bar once and use a master border to have it repeat on every page you create. Fusion also automatically creates links throughout all the documents in your site. Understanding and using master borders is paramount to creating pages with Fusion, as its easy to accidentally create pages with unwanted elements if you forget to change one or more of the master borders. While it is easy to create snappy site navigation in Fusion, the product's esoteric interface issues make it far more complex than single-page-oriented programs such as PageMill.
Fusion's page-editing setup is straightforward, however; it has a brightly colored interface modeled after traditional print page layout tools like QuarkXpress. Each page has a clearly marked area for its master border; Fusion will not allow you to drag an image or text to sit between the master border and the main layout section of your page.
When we imported hand-coded (and perfectly Web-legal) HTML into Fusion, it made a mishmash of the tables. All text layout is done with text boxes, a setup that mimics QuarkXpress and PageMaker. This is not how HTML text naturally works (Fusion is actually creating tables that hold the text to correspond to boxes in the layout tool) and becomes a problem when you import HTML pages you have created by hand; the text boxes tend to overlap and cause problems with other elements on the page.
Fusion is a powerful tool, but it has a major flaw: It assumes that WYSIWYG editing and dialog boxes can save users from ever facing HTML. In the real world, any Web site larger than a page or two requires at least some tweaking.
Home Page 2.0
Like Netscape Composer and Adobe PageMill, Claris Home Page is best suited for less- experienced Web authors. Home Page covers the basics, but its support for power features consists of dialog boxes that include "extra HTML," snippets to be added to existing tags. Most experienced HTML coders will want to pick a more advanced editor or do the coding by hand.
Creating and using frames with Home Page is not a pleasant experience. The program prefers that you first create the separate pages that make up the frameset, then select New Frame Layout from the File menu. Alternatively, you can create the frameset first and link the pages later. Either way, all you see is a white layout that indicates which HTML files are linked to which frames. Home Page does not offer a preview mode, which would be a big help for beginners.
Table creation is fairly straightforward, though we had problems when we tried to create the table that holds images touching exactly. When we looked at the HTML, we found the following code in the table's image tags: X-SAS-UseImageWidth X-SAS- UseImageHeight. While removing strange bits of code like this is no big deal for a veteran designer, a novice who barely knows HTML might be thrown for a loop. We also had some difficulty choosing background colors for the table cells.
Home Page has a few nice touches in its interface. The program uses the right mouse button to give the designer access to the object editor (a generic set of dialog boxes for whatever you have highlighted) as well as the ability to edit and follow links. The program also makes importing QuickTime videos a snap; it loads the first frame as a placer graphic.
Home Page is not the answer for professional HTML editors who need a WYSIWYG tool. For novices, Home Page offers a gentle introduction to HTML in some areas, but other aspects such as frame support need improvement.
HotMetal Pro 4.0
HotMetal Pro (SoftQuad, Inc.) began as one of the early commercial HTML editors, before WYSIWYG became a standard for Web-authoring tools. The 4.0 version of the product adds a powerful WYSIWYG editor to the tag-level editing capabilities found in earlier versions of the software.
HotMetal Pro's interface has three main components: a WYSIWYG editor, a "tags on" editor, and a pure HTML editor. The WYSIWYG editor allows you to activate up to nine different toolbars that you can drag off to float a la Word or Excel. The WYSIWYG toolbars can also be used to insert HTML tags, a real time-saver. The straight HTML editor is pretty basic, though there are some useful options for formatting and coloring your source code.
The "tags on" view is reminiscent of HotMetal's non-WYSIWYG versions. This mode offers the ability to view formatted text, images, and tables, while at the same time checking the position of the most important tags in your layout.
Switching among these three modes is easy, using icons at the bottom of the screen or command keys. A nice touch to this common interface is a browser toolbar you can use to preview your work, with icons representing each browser.
HotMetal Pro shows off its roots as a coding tool by generating some of the cleanest HTML seen in this review. Tables are spaced nicely, without the mysterious (and annoying) custom tags you get from other tools such as Adobe PageMill. HotMetal Pro also has a fast HTML checker that lets you validate code you've written.
Another nice HTML feature that you can use in non-HTML modes is the "insert element" button, which gives you a long list of tags to choose from and helpful descriptions about what those tags do.
Still another important feature that bridges the gap between WYSIWYG and HTML editing is the "attribute inspector," which is activated from a pull-down menu using the right mouse button. The inspector has a huge list of attributes, such as a table's cellpadding and targets for link tags, which makes editing page elements and changing HTML in WYSIWYG mode much easier.
Creating a frameset in HotMetal Pro is a bit primitive, however, and will be intimidating to the novice. The setup is similar to that of Claris Home Page; there is no real preview of the actual frameset, but rather a "frame editor" that allows you to customize, but not view, your frames.
We also had some problems creating our sample table in HotMetal Pro that holds images touching exactly; we found it necessary to use the attributes inspector to edit the cellpadding and cellspacing.
Overall, HotMetal Pro is a solid tool with a robust interface that gives the HTML expert lots of control over page design. The easy-to-grasp WYSIWYG interface also makes it well suited for novices who want to make the transition between WYSIWYG designing and HTML coding.
PageMill 2.0
PageMill 2.0, from Adobe Systems, Inc., has a well-designed interface that is especially friendly to users who have spent a lot of time with word processors. The tool's editor also offers enough features to satisfy hard- core HTML coders.
The interface displays two windows, the "inspector" and the "pasteboard," that complement the main page. The pasteboard is basically a holding area for page elements such as images, sounds, movies, and links. You can drag and drop these files onto the pasteboard and sort through its contents to evaluate and organize your assets. You can also import images, sounds, and movies directly onto the page by dragging and dropping them.
Once the desired elements have been created or imported, you use the inspector to modify their properties and attributes. Highlight an element and it automatically appears in the inspector, a nice touch. Less accommodating are the inspector's many tabs, with their ambiguous, and sometimes confusing, icons. For example, when you have text inside a table, it is sometimes hard to determine which tab will let you access the properties of the table cell and which handles the text's properties.
PageMill had other difficulties with tables, stumbling in our test in which images must touch exactly. Upon inspecting the code, we found that PageMill had inserted a group of non-HTML NATURALSIZEFLAG="3" tags, the kind of coding that only makes a mess of things. We also had trouble getting the frame border to equal zero for a borderless frame.
PageMill does a nice job of allowing you to create an image map right on the page by setting the image's properties to "map" and then drawing hot areas and assigning links. It also has a floating-colors palette that gives you 16 colors to liven up drab page objects.
The program's "preview" mode is intended to simulate how your page will look and function in a browser, but it fails to render the nuances of Web page design in either Navigator 4.0 or IE 4.0. A better option is PageMill's "switch to" mode, which connects you with the actual browsers.
QuickSite 2.5
QuickSite's powerful site-creation features give a big boost to users who know nothing about HTML, let alone Unix. The Site Technologies, Inc. product concept is similar to that of NetObjects Fusion: Provide a tool to designers and business people that lets them create a fully functional Web site without dealing with HTML or the Unix file structures involved in setting up navigation paths.
Unfortunately, QuickSite's flaws are similar to Fusion's: Without direct access to the HTML, precision code tweaking is impossible until after the site is published. The HTML the program generates is heavily laden with tables and hidden placer GIFs, making it difficult to edit. For example, the right-hand frame of our test page was originally 3K; the HTML generated by a re-creation of the page with QuickSite was more than twice as large at 7K.
Though QuickSite is targeted at beginners, its unusual interface is probably better suited for more advanced users because of its lack of similarity with word processors or other WYSIWYG packages. QuickSite's page layout tool has some nice touches, though, like a pop-up palette that offers the 216 Web-legal colors. You drag these colors onto table cells or text to apply them. Another nice touch that even novices can appreciate: When you double-click on a text box, a text-editing window appears. However, the changes to color or point size that you make in the text-editing window apply to the entire text box, rather than just a section.
Though QuickSite has some advantages on the site level, it is difficult to ignore its problems with handling HTML, and its pages will not import smoothly into other WYSIWYG programs.
Visual Page 1.0
Visual Page from Symantec is a solid entry in the Web-authoring market, with a comprehensive list of features. The product's straightforward interface doesn't get in the way; for instance, its seven toolbarswhich allow you to insert form items, edit image maps, create links, and perform other tasksare easy to turn on or off. You can also customize your workspace by pulling the toolbars from the main window and positioning them on the sides or corners of the screen.
Visual Page is well suited for designers who want all the ease of use of WYSIWYG but need solid HTML support as well. The program lets you open two windows for each page you are working on; one shows you the WYSIWYG view, while the other displays pure HTML. While Visual Page doesn't give you any formatting preferences on your HTML beyond setting colors for tags and attributes, the default layout style is workable with standard indentation for tables.
The main advantage of being able to view the HTML and layout windows simultaneously is that changes in one are instantly updated in the other. This is perfect for less experienced authors who are trying to learn HTML, as they can see which tags are created when they add new elements to the page. Conversely, the experienced HTML user can keep a close eye on code while using the WYSIWYG tool, switching back quickly to HTML to modify details.
If your site relies heavily on Java applets, Visual Page has an advantage over many of the other tools we tested. Unlike most programs in which you must embed a Java applet in a predetermined space while you are laying out your page, Visual Page lets you play the applets in preview mode before they go into the layout.
Visual Page is a quality product at a very attractive price. It's solid, not flashy, and has something to offer novices and experts alike.
Web.Designer 1.1
Web.Designer 1.1 is part of Corel's WebMaster Suite, which includes a plethora of tools, clip art, and other extras that attempt to comprise a complete Website solution in a single box. Web.Designer covers the standard page-authoring features fairly well, but has some sticky interface ramifications that will slow down the power user.
Web.Designer's interface is almost identical to that offered by HotMetal Pro, Visual Page, and several other tools. Like the others, it features a gaggle of toolbars that you can hide, activate, and drag around your window to customize the screen.
However, the interface gets a bit clunky when you want to edit HTML source code. There is no command key to quickly bring you to the raw HTML (you have to search for a button on one of the toolbars). When you are in "document source" mode, you are presented with plain, black-and-white HTML code with little or no formatting. When you are in this mode, all of the useful toolbars disappear, so you can't use them to insert HTML as you can in HotMetal Pro. In HTML mode, there are only three options: "keep changes," "discard changes," and "print source."
Web.Designer generally does a good job of creating and editing tables; the right mouse button gives easy access to every conceivable table option. Adding color to specific table cells, however, proved a bit awkward. The software handles frames effectively, though experienced designers will want an alternative to using the frames wizard every time they create a new page with frames.140
Multi-Authoring: Change and Version Management
Technology Background
The WYSIWYG paradigm, very useful when editing a traditional document, is not applicable for multimedia documents. Past years have seen numerous attempts to design the perfect hypermedia/multimedia system. The ever-increasing growth of the Internet and expectations from the information highway promote the interests of using distributed hypermedia systems. Widely known information systems like WAIS, Gopher, and WWW can be perceived as first generation hypermedia systems, however, the shortcomings of these systems cannot be overlooked. All of them were designed as stand-alone applications that use scripting languages to define the navigable structure for including multimedia content. In other words, they only offer original authoring and storing of rigid, inflexible multimedia material in a way similar to the original programming of multimedia applications. They do not fulfill the demands of modern hyper/multimedia technologies. This is the reason for developing a new generation of hypermedia authoring tools.141
In the early days of application development, simple version control programs were sufficient for keeping track of changes. However, as project teams grew larger and distributed development environments and applications became more complex, effective project development required greater version control so configuration management software was introduced. Configuration management tools added support for work areas and building management. With the need for greater control and an interest in reusable components, software change management software replaced task-based with file-based configuration management and introduced several other important capabilities:
• Change request tracking and management.
• Problem tracking and management.
• Team collaboration and management.
Today's enterprise-wide development requirements demand more than these point solutions can offer, particularly in the area of scalability. Development efforts may now encompass hundreds of teams and thousands of developers distributed around the globe, all working concurrently on multiple revisions and versions of the same program.142
Versioning in Hypermedia
Versioning is the management of multiple copies of the same evolving resource, captured at different stages of its evolution. Versioning is a well-known technique whenever there is data to be authored: it provides for the verification of progress in authoring, it guarantees fail-safe baselines for exploratory changes, and it supports verification and comparison of the individual efforts in a multi-authoring situation.
Yet, versioning adds (sometimes heavily) to the authoring efforts, in terms of both system resources, and most importantly of the conceptual overhead for authors. Dealing with versions affects the straightforwardness of the work with quite a number of chores unrelated to the main writing task. Just like backing up data, versioning requires constant awareness for just possible usefulness, and its advantages are sometimes appreciated only when it is already too late.
It is not surprising, therefore, that often versioning is seen as an optional commodity, and sometimes a burden, rather than an essential apparatus of the authoring environment. Only in some specialized and highly sophisticated authoring communities, such as software engineering and database management, has versioning become part of the routine chores of the practitioners.
In hypermedia, insofar as it is viewed as an authoring situation, the problems connected to version management have been frequently examined and discussed. Of course, most of the problems that apply to other authoring environments also apply to hypermedia. Yet, there are peculiarities in versioning inter-linked content that at the same time pose some new problems, and propose an elegant solution to an important issue, referential integrity of links, that is specific of hypermedia.
Several important systems throughout the long history of hypermedia have discussed, implemented, or even relied on versioning functionalities, from Nelson's Xanadu to the current IETF standardization efforts of WebDAV, ranging through well-known systems such as SEPIA, Hyperform, and Microcosm.
Advantages of Versioning for Hypermedia
In many cases, being able to access older versions of a resource (e.g., a set of related documents) is downright necessary. For instance in the software process, where it is important to maintain (i.e., verify and modify) the deployed releases even while someone else is creating a new one. Or, in most legal systems, the law to be applied is the one that is valid at the moment of the affected event, although its content may have changed in the meantime. In situations where the authoring is managed and controlled within a workflow, the accounting and verification of the authoring activities provide additional motivations for accessing older versions of the artifact. In these cases, it is useful to compare the current state of the resource with older versions in order to determine the changes, keep a record of them, and evaluate the progress of the development. Furthermore, versioning helps in exploratory authoring. A good and reliable baseline version makes authors more confident in doing experiments and trying out new development paths with their documents, even if they eventually turn out to be unviable or unacceptable, since they can return to the baseline at any time and re-start experimenting from there.
Also, distributed and collaborative authoring may profit from version support. Verification and evaluation of others' contribution is eased by the possibility to compare their work with previous baseline versions of the resource. If we allow the chain of subsequent versions to fork into independent branches, then multiple authors can work on the same resource at the same time with no risk of overwriting, since each author would work on an independent version of the same resource. It has been noted that in many creative authoring situations (including hypermedia) long transactions are crucial because operations in hypertext environment are often long-lived.143 Relying on locking for concurrency control, even fine-grained user-controlled locking, may be excessively exacting in certain situations. It may be preferable to allow the development path of a resource to diverge into two or more independent branches that can be merged into a single, final state in a later stage of the development. Branching versions could even allow collaboration to emerge without planning. Emergent collaboration happens when readers of a published resource provide the original authors with suggestions, modifications, additions, additional links, etc. These can then be put into a separate branch of the official version tree of the resource, and can be accepted and accessed by readers without requiring integration or officialization by the main authors.144 Versioning provides an additional advantage for hypermedia, providing an easy solution to an old problem of hypermedia: that of the referential integrity of links. In the words of Ted Nelson, "But if you are going to have links you really need historical backtrack and alternative versions. Why? Because if you make some links to another author's document on Monday and its author goes on making changes, perhaps on Wednesday you'd like to follow those links into the present version. They'd better still be attached to the right parts, even though the parts may have moved." The problem can be summarized as follows:145
• In many situations, it is useful to link not just whole resources, but specific locations within the resource (the so-called point-to-point links).
• There are very good reasons to store links outside of the resources they connect rather than embedded inside them à la HTML. For instance, external links allow linking into resources that we have no write access for, that are stored in a read-only medium, or that have been heavily linked by other users for other purposes we are not interested in. Furthermore, external links allow private links, specialized trails, and multiple independent link sets on the same document set. Hypertext systems that implemented external links are too numerous to mention, but it is worth noting that XLink,146 the linking protocol for the XML language, also allows external links.
• Whenever a linked resource changes, external links risk pointing to the wrong place because of the changes themselves: whatever the method for referring to a specific location of a resource (e.g., counting, searching or naming), there may be a change that messes up the reference.
• Fixing dangling references can be performed by having a human retrieve the new position and update the reference, applying "best bet" heuristics, whereby the current link end-point is determined by finding the most similar content to the old end-point, or by position tracking, that is, by following change after change of the evolution of reference, thus determining its current position.
Of these solutions, only position tracking requires no human effort and guarantees a correct solution in all cases. Position tracking, on the other hand, requires that the resources being linked are versioned, since it implies accessing subsequent versions of the same resource, comparing them in a sufficiently fine-grained detail and following version after version of the evolutions of the interested position.
Versioning Issues in Hypermedia
The adoption of a versioning mechanism within a hypertext system raises several important issues. An important concept is that of version models. Haake147 identified two basic version models: state-based versioning maintains the version of an individual resource, while task-based versioning focuses on tracking versions of complex systems as a whole.
These concepts are similar to those of state-based and change-based versioning as known in software engineering.148 State-based versioning does not support the tracking of a set of changes involving several components of a hypertext network, while task-based approaches provide system support for maintaining the relationships between versions of resources that have been changed in a coordinated manner during the performance of a task. Holistic, task-based approaches to versioning are especially sensible in hypermedia, given the complex, multi-dimensional aspects of modifying a complex hypermedia network. Østerbye149 raises a pair of important structural problems in versioning hypermedia: the immutability of frozen versions and the versioning of links.
Intrinsic to any version model is the fact that older versions of a resource are frozen, that is, they cannot be changed without creating a new version of the resource. Yet it may be useful to allow frozen versions to have new links (for instance, annotations or comments) coming from and going to them without necessarily creating a new version of the resource. At the same time, some links are substantially part of the resource itself, and thus their modification should definitely require the creation of a new version of the whole resource. Depending on their meaning and their role, therefore, the creation of some new links may or may not imply the creation of a new version of the resource. External link sets may seem a solution to this problem: When creating a new version of a resource, the author would also specify the set of substantial links (the ones that, if modified, would create a new version of the resource), while all other links would be considered as annotation links (and would not require a new version of the resource if changed or incremented).
If links are external to the resources they connect, the issue of link versioning must be considered: given a link from A to B, what happens to it when, for instance, B is changed under the control of a versioning system? Does it follow through to the current version of the resource, and no link points to the old version of B any longer?
Does it generate a new link pointing to the new version of the resource, so that we now have two links from A, going to both the old and the new version of B? Or does it create a new version of the whole hypermedia network, one in which the link goes from A to B (old version), and another in which the same link goes from A to B (new version)?
Differently from other fields, in hypermedia all these solutions could be valid and preferable over each other depending on the task is being performed. Thus, the final decision is left to the authors in a case-by-case fashion. This leads to noteworthy cognitive problems (also discussed in {Østerbye, 1992}) such as version freezing and element selection. The issue of version freezing concerns the complexity of deciding the set of resources to be frozen in a stable state after an editing session, and of actually performing the freeze. The issue of element selection arises whenever there is a link to a resource of which there are more than one version, and there is no pre-defined policy as to which version of the resource should the link point to. Here, both sending the reader to a default version and asking the user to choose the version seem cumbersome and awkward solutions.
A Brief History of Versioning in Hypermedia
Versioning has been a topic of hypermedia since a very early age. Version management is intrinsic and fundamental to the inner workings of the Xanadu system.150 Xanadu proposes a peculiar way to organize the data, called the Xanalogical storage, where the documents (the minimal structure of the system) either actually contain their content (native bytes), or refer to it by inclusion from other documents (included bytes). In Xanadu, versioning is at the same time an immediate functionality (a new version is a new document including all the parts of a document that were also present in the previous version and having as native bytes all the new data) and a requirement. Xanadu links refer to their end-points by offsets, so that any change to the content of a document would corrupt the very structure of the inclusions unless exact tracking of documents' evolutions is activated through versioning. Later in time, both RHYTHM151 and Palimpsest152 proposed a solution similar to the Xanalogical storage, heavily relying on versioning for the management of correct inclusions.
After the experience of the PIE system153 and Halasz's powerful keynote address to the Hypertext '87 Conference,154 where versioning was mentioned as one of the main open issues in the hypermedia field, many researchers set out to study the subject. CoVer155 is a contextual version server that can provide both state-based and task-based version models for the SEPIA hypermedia authoring system; within HB3156 and Hyperform157 researchers concentrated instead on abstracting the concept of version management from the actual hypertext systems they were going to provide such service for.
In 1994158 and 1995,159 two versioning workshops helped to further shape the field, examining aspects such as link selection, conceptual overhead in version freezing, and support for collaboration in distributed hypermedia. Among the hypertext systems that implemented some kind of version support we will also include Microcosm160 and Chimera.161
The advent of the World Wide Web introduced the new challenge of adding versioning functionalities to it. Vitali and Durand proposed VTML, a markup language to express change operations for WWW documents, in particular HTML.162 HTML 4.0163 includes two new tags, INS and DEL, that are meant to express changes from previous versions of the same document (e.g., in legal texts); unfortunately these tags, being part of the markup language, cannot express changes in the markup itself (e.g., two paragraphs have been joined, a link destination has been changed, etc.) or changes that disrupt the correct nesting of the markup.
A newer activity is that of the WebDAV specifications. WebDAV is an IETF working group devoted to extending the HTTP protocol to support distributed authoring. Since it was felt that versioning would play an important role in the management of distributed collaboration over documents available from an HTTP server, versioning was made part of the requirements of the WebDAV group164 and will be covered by a forthcoming specification.165
Issues in Versioning for Collaboration166
The WWW Distributed and Authoring Working Group (WebDAV) defines versioning as the fundamental basis of document management systems with far-reaching effects on the semantics of document identity and meaningful operations. The problem of versioning, particularly in relation to hypertext documents like those that makeup the majority of Web content, is a complex one. Link integrity, document set consistency, and editorial factors all have an influence.
Benefits of Versioning
Versioning in the context of the World Wide Web offers a variety of benefits:
• It provides infrastructure for efficient and controlled management of large evolving Web- sites. Modern configuration management systems are built on some form of repository that can track the revision history of individual resources,and provide the higher-level tools to manage those saved versions. Basic versioning capabilities are required to support such systems.
• It allows parallel development and update of single resources. Since versioning systems register change by creating new objects, they enable simultaneous write access by allowing the creation of variant versions. Many also provide merge support to ease the reverse operation.
• It provides a framework for access control over resources. While specifics vary, most systems provide some method of controlling or tracking access to enable collaborative resource development.
• It allows browsing through past and alternative versions of a resource Frequently the modification and authorship history of a resource is critical information in itself.
• It provides stable names that can support externally stored links for annotation and link-server support. Both annotation and link servers frequently need to store stable references to portions of resources that are not under their direct control. By providing stable states of resources, version control systems allow not only stable pointers into those resources, but also well defined methods to determine the relationships of those states of a resource.
• It allows explicit semantic representation of single resources with multiple states A versioning system directly represents the fact that a resource has an explicit history and a persistent identity across the various states it has had during the course of that history.
Requirements of Versioning
The following are general requirements for WWW versioning:
(1) Stableness of versions. Most versioning systems are intended to enable an accurate record of the history of evolution of a document. This accuracy is ensured by the fact that a version eventually becomes "frozen" and immutable. Once a version is frozen, further changes will create new versions rather than modifying the original. In order for caching and persistent references to be properly maintained, a client must be able to determine that a version has been frozen. We require that unlocked resource versions be frozen. This enables the common practice of keeping unfrozen "working versions." Any successful attempt to retrieve a frozen version of a resource will always retrieve exactly the same content, or return an error if that version (or the resource itself) is no longer available. Since URLs may be reassigned at a server's discretion this requirement applies only for that period of time during which a URL identifies the same resource. HTTP 1.1's Entity tags will need to be integrated into the versioning strategy in order for caching to work properly.
(2) User Agent Interoperability. All versioning clients should be able to work with any versioning HTTP server. It is acceptable for some client/server combinations to provide special features that are not universally available, but the protocol should be sufficient that a basic level of functionality will be universal. It should be possible for servers and clients to negotiate the use of optional features.
(3) Policy-free Versioning. Haake and Hicks167 have identified the notion of versioning styles (referred to here as versioning policies to reflect the nature of client/server interaction) as one way to think about the different policies that versioning systems implement. Versioning policies include decisions on the shape of version histories (linear or branched), the granularity of change tracking, locking requirements made by a server, etc. The protocol should not unnecessarily restrict version management policies to any one paradigm. For instance, locking and version number assignment should be interoperable across servers and clients, even if there are some differences in their preferred models.
(4) Separation of resource retrieval and concurrency control. The protocol must separate the reservation and release of versioned resources from their access methods. Provided that consistency constraints are met before, during, and after the modification of a versioned resource, no single policy for accessing a resource should be enforced by the protocol. For instance, a user may declare an intent ion to write before or after retrieving a resource via GET, may PUT a resource without releasing the lock, and might even request a lock via HTTP, but then retrieve the document using another communication channel such as FTP.
(5) Data format compatibility. The protocol should enable a versioning server to work with existing resources and URLs. Special versioning information should not become a mandatory part of document formats.
(6) Legacy client and server support. Servers should make versioned resources accessible to non-versioning clients in a format acceptable to them. Special version information that would break existing clients, such as new mandatory headers, cannot therefore be required for GET (and possibly also for PUT).168
Version management has a number of effects on collaborative editing and linking of documents. Asynchronous collaboration, which occurs over a long period of time (days to years), means that collaborators need to work in isolation, as well as cooperatively. In addition, the machines used by collaborators cannot count on the constant availability of a link to other collaborator's machines. This parallel asynchronous collaboration leaves the greatest freedom of interaction to the collaborating team.
Versioning systems, besides providing useful tools for the management of the complex and dynamic evolution of documents also gracefully allow asynchronous parallel collaboration, thus becoming a fundamental tool for joint editing. But, even more importantly, versioning creates a persistent addressing scheme on versioned documents, which is fundamental for sophisticated uses of references.
Parallel Asynchronous Collaboration
A number of collaboration models are possible for group and distributed editing:
• Synchronous collaboration on a document requires simultaneous interaction of all interested parties. There are situations where the document serves as a communicative prop for meeting support, even though the end result might have some value after the end of the editing session. From the point of view of geographically separated authors working on a document, there are several problems with synchronous interfaces. For example, some problems with synchronous collaboration are the need for object locking, bandwidth to provide awareness of other users' actions, possible maximum limits on the allowable number of collaborating partners, and the cognitive load of tracking multiple insertion points and action focuses. If synchronous communication is not a primary need, the only advantage of synchronous editing is the provision of a single, consistent state of the document at the end of the editing session.
• Serialized asynchronous collaboration accords write access to only one author at a time, thus locking the document to other authors until the first one is finished. This policy overcomes most of the problems that arise in synchronous collaboration, and still has the advantage of having one consistent state of the document after each editing session. However, it prevents simultaneous, independent editing of the same document, and subjects document availability to unpredictable delays from network partitions, system crashes, and the coffee breaks of the author who has write access. Furthermore, it does not allow off-line editing, since it strongly invites the author with the write token to return it immediately after he/she has finished the editing session and does not allow, for instance, modifying a document while keeping the token for a whole weekend.
• Parallel asynchronous collaboration , on the other hand, allows all authors to modify the document independently and in parallel, creating several independent and simultaneous states of the document (called variants ), which may need to be merged into one final state. By removing or postponing the convergence of the document to a single state, it overcomes most of the practical obstacles to the editing process imposed by other collaboration schemes.
Versioning Systems
A versioning system is a software module that maintains an identity relationship between different instances of a single data object. Each instance is a version of the object and is connected to the other versions in a possibly complex structure of ancestors, descendants, and siblings. Documents are thus shaped as a sequence, or a tree, or a directed acyclic graph of versions, so that the content of any desired version is determined by the operations performed on the sequence of nodes connecting it to the root of the derivation.
A versioning system allows parallel asynchronous collaboration, since it facilitates the display of differences between several subsequent versions of a document ( time-based versioning ), or the tracking of modifications between several different variants of the same version ( author-based versioning ). Furthermore, by allowing automatic merging, it makes it possible to build a single final state of the document as the result of several parallel contributions, making the collaboration converge to a single state as it would with the other kinds of collaboration.
Since version editing never impacts other users' activities, the check-in operation of a private version can happen at any time after several versions have been produced. Thus, it is possible for a user to download a working draft locally, work on it several times, produce several successive versions, and then send the final one or the whole set of them back to a server where the official copy of the document is stored. Furthermore, emergent collaborations become possible. Any user having read access to a document can create a modified version of it and submit it to the original authors, who may decide to put it in the set of official versions. Becoming part of the group of authors of a document is thus possible at any time, even for someone not known to the author previously.
A versioning system allows distribution of a team over a large-scale network without inherent scale problems in the number of authors, available documents, or involved servers. It can avoid many standard techniques such as locking and replication of objects or synchronization and serialization of operations. It would pose minimal constraints on the distributed system in terms of network load, maximum allowable number of collaborating partners, and client/server interaction patterns, among other factors.
Reliable Persistent Addresses
Another important advantage for hypertext versioning systems is the management of the persistent relationships of a versioned object. This is particularly important for hypertext: links are the explicit mark of an existing relationship between two given data objects. When either of the two objects is modified, the relationship needs to change as well. HTML has both ends of the link stored along with the data they refer to (the <A HREF> and <A NAME> tags), so that the update of the links is automatically performed when the documents are changed.
However, requiring internal storage of this kind of relationship has several drawbacks: basically, it is necessary to have write permission on a document to insert new relationships. Thus, it is impossible for us to add an internal HTML link, a comment, or new content to a document, unless we own it.
Even if a browser allows us to add new data to a document by storing it locally (i.e., externally to the document), there would still be a key consistency problem. If the original copy of the document is changed, the references stored locally are no longer valid because the position they refer to has moved.
VTML offers a solution based on a simple consideration on versions: the addresses of the chunks of every version of a document are unique, global, stable, and independent of the addresses of chunks inserted in alternative versions. Furthermore, they may be derived from the addresses of previous versions by recording successive edits performed in the meantime (such as insertions, deletions, and modifications), or, when this is not possible, through a sufficiently effective diff mechanism on the two versions.
This means that, by storing the successive operations that were done on the document, we are able to build persistent addresses of chunks in any version we are interested in. Furthermore, operations that do not belong to the chain of versions we are interested in may be stored as well. As long as it is possible to determine that they are irrelevant to the desired versions, they and their associated data can be completely ignored.
Being able to compute the position of any chunk in any version of a document means that references need not be modified when the document is changed and a new version is created. Instead, the current values can be computed when they are needed. References can be stored externally and independently of the document. It is possible to make local references to remote documents or to readable documents on which we have no write permission.
In hypertext, external references allow point-to-point (or span-to-span) links to be stored separately from the document they refer to. Point-to-point links are extremely useful in several situations where the length of the document cannot be decided arbitrarily (for instance, when using electronic instances of long linear texts such as traditional books).
External links are also ideal for implementing private links. Users will be able to create personal point-to-point links on public documents and store them on their computers. Links are always consistent, do not use public disk space, and do not clog public documents. We believe that all other solutions for private links have greater drawbacks than external links on versioned documents.
Finally, external references provide the basis for a truly useful inclusion facility: users are not limited to including whole documents, but can specify parts of them, being confident that the correct part will be retrieved again no matter what has happened to the document since the inclusion was specified. This form of inclusion is more like copy and paste, where the source of the data is still available, the source can be displayed, the data is not actually duplicated, and the data can be requested to modify and update according to what has happened in the source document in the meantime. The form of inclusion provided by versioning subsumes the functions of intelligent copy and paste and hot and warm links.169
Versioned Text Markup Language170
VTML (versioned text markup language), a markup language for storing document version information, can easily be implemented within a text editor and provides a notation and semantics for tracking successive revisions to a document. The main purpose of VTML is to allow asynchronous collaboration in the creation and editing of text documents.
Version control allows different instances of the same document to coexist, enabling individual and comparative display, as well as automated or assisted merging and differencing. Version control systems are routinely used in many fields of computer science such as distributed DBMS, software engineering, hypertext, and CSCW. VTML is a general versioning language that allows for a large number of different applications in all these fields, particularly in the joint editing of hypertext documents such as those available on WWW.
Naturally, most authors are not going to give away disk space so that others can revise their work, but with VTML it is possible, in principle, to enable universal write access on the Web. With VTML's ability to store changes externally to a document, it is possible for someone with access to the Web to publish correction or update documents that create a new version of another author's work stored separately. Access control for derived works becomes a matter of who has access to the relatively small server resources needed to make changes available. The author and the author's server do retain an imprimatur to mark revisions as "official." Such free access raises two fundamental requirements: consistency and accountability.
Consistency is a problem since the meaning of a link depends on the state of the document that it refers to. When documents are edited or revised, locations change, potentially destroying a record of what text was linked. Even if the link is translated to the corresponding part of the new document, the meaning may have changed significantly enough to make the original link and comment meaningless or incorrect. The use of symbolic identifiers avoids the problem of shifting text locations, but is, practically, only available to an author, since the original document must be changed to create the link destinations.
Accountability is the question of who is responsible for a document, and while always important, it is even more critical in the case of documents with multiple authors or successive versions. A reader needs to know who has authored a document, whether the document was modified, and, if so, by whom.
In a versioned context, both consistency and accountability can be managed much more easily. The most important characteristic of versions is that they are immutable: rather than overwriting old data as simple file systems do, new versions are simply added to the repository, superseding, but not replacing their previous versions. This guarantees that links to old versions are always accessible, and that they are always in context (temporally as well as spatially). Since links frequently remain relevant in later versions of a document, it is also desirable that data locations are tracked through successive versions of a document, so that the current location of externally-stored links can be determined.
Accountability is enhanced because each server is responsible for the versions or updates it stores and can retain any author or group identification information desired. VTML provides specific ways to record this information, so that, every change made to a document can be tracked to the person who made it.
Versioning also provides a solution to the problem of addressability, identified by Engelbart.171 Since one needs to be able to refer to any point in a document from outside that document, there must be a way to deal with change, or at least mitigate its effects. Because versions are immutable, they are addressable across time, even as the document they relate to evolves. This also means that any convenient structural addressing scheme can be used to reference within a versioned document, whether character offset in a file, or path specification through a structured tree. All are safe to use, as the navigational procedure for that version is fixed forever. This is the key that allows document information to be stored outside the document itself and makes it possible to externally create and manage resources such as external modifications, annotations, external links (like HyTime's ilink, chunk inclusions, private links, and documents of links (e.g., paths and guided tours). These facilities incur no update cost: no explicit update of external references is required when changing the referenced document, since the external references are all grounded by the persistent addressing schema provided by the versioning system.
It is important to bear in mind that this solution handles the problem of references to document-internal objects. Fully persistent references depend on a location-independent naming scheme. VTML does not address this latter problem, though it is compatible with, and indeed, depends on, such a scheme. For the World Wide Web, the URN (universal resource name) protocols under development within the IETF will provide such an infrastructure.
VTML associates every editing operation on the document with a specific version and each version with its author and the date on which it was created. The division of labor between client and server is simple. Document creation and editing happens locally (users work on their own computers), asynchronously (there is no requirement for immediate notification of the users' actions), and in parallel (all users can work on the same document independently, creating their own separate revised versions). These features make both simultaneous (as in GINA) and non-simultaneous collaborations possible. The delta-based nature of VTML also helps keep storage size reasonable, as constant data is generally not duplicated between versions. The deltas recorded are, however, expected to reflect the actual editing operations performed by users, rather than solving the expensive problem of the minimum space to store differences between versions. We believe the changes stored should reflect what actions were actually performed on the document in order to be truly meaningful to users of the system.
VTML data is stored in markup tags alongside the affected data, or externally in separate documents. The simplest VTML implementation is as a preprocessor that interprets VTML tags, producing a stream of characters for some other processor or protocol. For instance, to display a requested version, the document and its external resources can be read and parsed, and the content of the requested version created on the fly. VTML can store versioning information on anything represented as a linear document, but is particularly suited for distributed hypertext documents such as those created by collaboration on the WWW. VTML makes it possible to display selected versions (both subsequent and alternative ones), compare them, and merge them.172
Hypermedia authoring shares many problems with other creative authoring environments. The issues arising from complex project management support for multi-authored documents and collaboration in hypermedia are similar to the corresponding ones in many other fields. Hypermedia differs from other fields because of the management of explicit relationships among the resources being managed.
Versioning hypermedia presents a few new problems because of the management of ad hoc relationships among versioned resources. On the other hand, besides many more advantages, versioning provides an easy and safe solution to the well-known problem of referential integrity of links.
It may seem overkill to advocate versioning just to make sure that point-to-point links do not refer to a few bytes off the correct place after a few changes. Yet, the real cases where the reliable tracking of positions are of paramount importance are still ahead of us. We haven't understood yet how Xanalogical storage (i.e., how the virtualization of content through the systematic use of inclusion references of chunks of other possibly virtual documents) may change our view of the creative process. Yet, for Xanalogial storage to be really working, it is necessary that a forced, automatic, transparent mechanism of versioning of data is put in place. No approximate good-enough solutions for the management of changing references can conceivably be considered acceptable in this case. A sufficiently fine-grained versioning model for the electronic resources need to be implemented and used systematically.
Major Players
Continuus Software, 108 Pacifica, Irvine, California 92618. Tel: (949)453-2200; Fax: (949)453-2276. Continuus is a leading provider of software products and services for Internet and enterprise software asset management. E-asset management is an emerging market segment that enables organizations to more effectively develop, enhance, deploy and manage their Internet and enterprise software systems. Continuus offers an integrated product line, consisting of the Continuus WebSynergy Suite and the Continuus Change Management Suite, designed to support the collaborative development, management, approval and deployment of the most complex and demanding software, Internet applications, and Web content.
Cyclic Software (www.cyclic.com) has been acquired by SourceGear Corporation, 3200 Farber Drive, Champaign, Illinois 61822. Since 1995, Cyclic Software has been involved with the CVS version control system. They have ported CVS to diverse operating systems, added features, fixed bugs and been a focal point for collaboration with other CVS developers. In addition, they are involved with other free software packages for programmers and web authors.
Trillium Software (www.trilliumsoftware.com), Tel: 612-924-2422; Fax: 612-906-1025. Trillium Software is a world leader in change management for detecting, processing, assessing the impact of, versioning and documenting "change" made to Oracle Applications and Developer 2000 software. Trillium Software was established to provide change management software to those customers applying patches, upgrading, and/or customizing their Oracle environments.
Xythos Software (www.xythos.com). Xythos created the Xythos Storage Server, which is the first integrated, Web-based document collaboration tool. The Xythos Storage Server is a key component for the new Internet world providing users and groups a single Web space for users who:
• Need access to digital information from multiple locations.
• Need to securely collaborate on documents across corporate barriers or large distances.
• Need a space to backup private important resources.
• Need to allow others access to files even when their computer is disconnected from the Internet.
• Work from multiple machines (such as telecommuters).
• Access information from multiple Internet devices such as PCs, cell phones, PDAs, etc.
Mortice Kern Systems U.S., Inc. (www.mks.com), 2500 South Highland Avenue, Suite 200, Lombard, Illinois 60148. The MKS Integrity Framework, a full suite of products, services, and training for client/server, AS/400, and the Web, solves the business challenges of software change management, Web content management, and enterprise interoperability, improving the quality of mission-critical systems and maximizing the productivity of enterprise teams.
SERENA Software, Inc. (www.serena.com), 500 Airport Boulevard, 2nd Floor, Burlingame, California 94010-1904. Tel: 650-696-1800; Fax: 650-696-1849. SERENA Software is a global software and services company dedicated to providing customers with quality software change management solutions to meet their requirements across the enterprise.
New Technology
Imagine working on a report with colleagues around the world. Each of you can access the Web page, click on the part you wish to change, and just type. Any changes you make are visible to your colleagues, as soon as you press Ctrl-S. More than one person can edit a page at the same time, and being on the Web, they can be anywhere in the world to do so. That was the original vision of Tim Berners-Lee, founder of the World Wide Web and director of its ruling body, the World Wide Web Consortium (W3C). In March of this year, the W3C announced the availability of a new browser--Amaya 2.1--that gets back to that original idea.
According to Berners-Lee, "The real power of the Web is in the links between pages. These are very easy to make using Amaya. Because it is also a browser you can display two pages at the same time. To create a link you just highlight text, click on a Create Link button, then just click anywhere on the destination page, and the link is created. Never should you have to write a URL, never should you see an angled bracket."173
Jim Sapoza of PC Week (June 6, 1999) reviewed this latest version of Amaya. Says Sapoza, "Every company should test the W3C experimental browser, if only for a valuable glimpse at the future of the Web. Businesses evaluating Web content management packages should also investigate Amaya because most of its editing capabilities are both more effective and easier to use than those provided by content management applications. And any company evaluating WYSIWYG HTML authoring tools should pit these tools against Amaya, which, with its straightforward interface and excellent core technologies, is in many ways superior to other tools in this market."174
Amaya
Amaya is W3C's own versatile editor/browser. With the extremely fast moving nature of Web technology, Amaya plays a central role at the Consortium. Easily extended to integrate new ideas into its design, it provides developers with many specialized features including multiple views, where the internal structural model of the document can be displayed alongside the browser's view of how it should be presented on the screen. Amaya has a counterpart called Jigsaw, which plays a similar role on the server side. Amaya is a complete Web browsing and authoring environment and comes equipped with a WYSIWYG style of interface, similar to that of the more popular commercial browsers.
Amaya maintains a consistent internal document model adhering to the document type definition (DTD), meaning that it handles the relationships between various document components: paragraphs, headings, lists and so on, as laid down in the relevant W3C HTML Recommendation. Amaya has been extended to demonstrate many features in HTML 4.0, the current recommendation for the language and XHTML, the next generation of HTML.
Used by other groups within the consortium to demonstrate work and to act as an experimental platform, Amaya has played an important role in the areas of:
• HTMLAs an editor, Amaya is guaranteed to produce HTML 4 compliant code. The way it handles documents strictly follows the HTML DTD (document type definition).
• XHTMLAmaya can also handle documents in XHTML, i.e., using the XML syntax. Due to namespaces, it can seamlessly integrate and manipulate structured objects such as mathematical expressions and vector graphics.
• HTTP protocolIn its basic version, Amaya implements many Web protocols and formats: it accesses remote sites by means of HTTP 1.1. Amaya takes advantage of the most advanced features of HTTP, such as content negotiation to retrieve, for instance, the most appropriate picture format, keep alive connections to save bandwidth, and authentication to allow secure remote publishing.
• Math on the WebAmaya demonstrates an implementation of MathML, which allows users to browse and edit Web pages containing mathematical expressions. The screen below (Figure 7.27) shows the way that you can display equations on the screen side-by-side the MathML model used by Amaya.
Figure 7.27. Amaya MathML Model
• GraphicsAmaya displays images in the PNG format, which is a more powerful graphics format than GIF and more suited to the needs of the Web. A CGM plug-in developed by Rutherford Appleton Laboratories was first demonstrated at EITC '97 in Brussels and in many other events. An experiment with 2D vector graphics was made in Amaya, to prepare the work on Scalable Vector Graphics (SVG). The graphics are written in XML and may be mixed freely with HTML and MathML.
• Style sheetsAmaya has extensive support for the W3C style sheet language CSS and offers a simple-to-use interface enabling users to write style sheets for Web documents without having to know the details of the syntax associated with style sheet rules and properties. You can create colored text, change the font, set the background color, and control other presentational effects. CSS style sheets may also be used to alter the look of graphics or mathematical expressions.
• DOMAmaya is used to experiment with the Java API developed by the Document Object Model activity.
• InternationalizationIt is now possible to launch Amaya so that the user dialogs are in various languages such as English, German, or French. Users may add other languages. Amaya can also handle multilingual documents, and it takes the current language into account when spell checking or hyphenating.
The latest version of Amaya (available June 24, 1999) has a number of interesting features including:
• A secured authentication protocol This protocol, called message digest authentication (see HTTP/1.1 specification), avoids sending a user's password in an unencrypted form.
• Language negotiation The user can specify a list of preferred languages. Amaya will then negotiate with the server to get the document version written in one of these preferred languages. This implies that the server supports content language negotiation.
• Protection against lost updates Whenever a user wants to publish a page, Amaya is able to dialog with the server (Apache and Jigsaw) and notify the user if that page has been updated in the meantime. This can be seen as the first step towards a cooperative authoring tool.
• XHTML support Amaya is able to generate XHTML conformant documents.
• New CSS features With Amaya, users can create, download, edit, and publish CSS style sheets as well as HTML pages. Amaya also provides an efficient mechanism to test and associate external style sheets with HTML documents.
• Editing featuresA general, multi-level, multi-document undo/redo mechanism is available.
Beyond this, the Amaya team will be working on: 175
• A fuller implementation of CSS2 properties.
• Features to support internationalization and localization for languages using non-Latin characters.
• Experimentation with XML documents.
• Integration with the GTK toolkit to allow easier experimentation and external contributions.
New Horizons
The Web application change-management market, revenue, and customer base will grow as companies increasingly realize that they have a problem that will only be solved with automation and tools.
Increasingly, Web content management tools are critical for delivering Website quality, for coordinating Web content with legacy application versions, for providing audit trails of changes, and for allowing anyone to contribute content. The need is exacerbated by the inexorable revolution in what Websites are used for, which drives the following requirements:
• The expansion of the types of objects in a Website and the contributing population will cause the Website to grow organically, rather than via hierarchically managed development projects. New methods are needed to control autonomous collaboration.
• Sites increasingly rely on back-end applications to create Web content dynamically; thus Websites are becoming dependent upon enterprise application development. Web and application objects and projects have to be managed by a single set of tools.
• Companies who were frantic to get a Web presence are now reflecting on the legal and ethical obligations the site creates. They need audit trails, accurate site re-creation, security, and comprehensive and consistent content review.
New types of Websites are appearing predicated on constant revision by a limitless population of contributing participants. For example, a Website may support collaborations among thousands of architects, engineers, suppliers, builders, contractors, and clients who are involved in a vast public works construction project. Content management has to enable a person with any background to add or change content on the site, view the audit trail, and re-create yesterday's or last month's content at the drop of a hat.
Website development has created a new type of project and requires a new type of management. Software development projects track predetermined individual tasks that execute a design, but Website change is organic. People are responsible for sets of content, rather than assigned to a particular project. For example, artists can be freshening the graphics that will appear throughout the site, while the sales department is keeping the price list up-to-date, the marketing communications department is posting press releases, and the legal department is constantly posting new schedules, data, analysis, and depositions to their litigation site. None of these activities is exactly a project; they are all actions taken on behalf of ongoing responsibilities.176
Cooperating teams that are autonomous, widely distributed, and loosely associated in virtual enterprises will perform future software development. They will need to share data in the form of software artifacts, as well as coordinate and configure relationships among them, to order and harmonize the products of software development processes.
Project coordination entails supporting collaborative information sharing and tool usage, concurrent development processes and data updates, intra- and inter-team communication, and well-formed composition of configured software artifacts, products, and documents. Software development projects that operate within virtual enterprises cannot assume that a central repository or similar mechanism will exist to serve as the medium of coordination among developers. Thus, the problem is how can virtual enterprises share, manipulate, and update data among loosely coupled teams.
These conditions will increase concerns for how to accommodate heterogeneity while maintaining administrative autonomy and transparent access to shared online resources. In addition, participating teams will need to follow well-defined processes to coordinate their work and share objects, resources, intermediate work products--or more simply, artifacts--with other members. Thus, coordinating software development projects in the face of total distribution requires the ability to access, integrate, communicate, and update software products, processes, staff roles, tools, and repositories, via a wide-area information infrastructure.
Collaboration and information sharing
• Provide transparent access to artifacts and relationships in a heterogeneous, autonomous legacy repository.
• Preserve the local autonomy of integrated data, tool, or product repositories.
• Integrate existing/new tools, components, and engineering environments in a simple, incremental manner.
Coordination of concurrent activities
• Integrate the modeling and execution of development processes for different staff roles with specified tools, artifacts, and workspaces.
• Control concurrent access to shared objects to ensure their consistency.
• Support software process modeling and enactment in widely distributed Internet-based environments.
• Provide a clearinghouse of information such as process enactment histories, design discussions, product annotations, etc. that capture and record interaction between developers.
• Model software development artifacts, documents, versions, staff roles, and other relationships.
• Support the well-formed composition and interfacing of objects that represent project products, processes, tools, staff roles, and supporting environments.177
Forecasts and Markets
Table 7.17. Forecast Revenues for Web Authoring and Design Software
Industry/Technology Roadmaps
Software Roadmap178
The purpose is to provide users with a guide of past, present, and future releases of OpenLDAP. The roadmap is not a schedule of availability.
OpenLDAP 1.0 (released August 26, 1998). This version is not actively maintained.
OpenLDAP 1.1 (released December 14, 1998). This version is not actively maintained.
Additional Features
• Externally configurable client library support: ldap.conf(5).
• Demonstration GTK interface.
• Demonstration PHP3 interface.
Enhanced Security Features
• ACL by group support.
• Improved password security features including SHA1, MD5, and crypt(3) support instead of clear-text passwords.
• Enhanced TCP wrapper support.
• Kerberos V compatibility.
Improved Build Environment
• Automated configuration.
• Shared library support.
• Upgrade platform support.
• NT4 development kit (libraries/tools).
Current Releases
OpenLDAP 1.2 (released February 11, 1999). The "stable" and actively maintained version.
• ldapTCLa TCL SDK from NeoSoft.
• LDAP passwd tool.
• Salted passwd support.
• Numerous bug fixes and platform updates.
Future Minor Releases
OpenLDAP 1.3 (~2Q99)
Additional/enhanced contributed software packages
• Updated saucer application
• Enhanced SLAPD Berkeley DB2 backend
• Enhanced SLAPD Threading
• SLAPD Perl backend
• SLAPD TCL backend
• NT SLAPD/SLURPD support
Future Major Releases
OpenLDAP 2.0 (~3Q99)
• LDAPv3 support!
• SASL/TLS/SSL support
• Updated LDAP C API
• Multi-thread library implementation
• Proxy LDAP support
Development Roadmap179
This document will serve as a narrative roadmap for Mozilla browser development. It won't be a schedule, although schedules should be attempted that refer to the terrain recorded and projected here. It will state rules of the road, or the design principles we'd like to employ, to build on the value of XPFE, NGLayout, and modularity using XPCOM. It will list major items of work. And will be updated over time to reflect reality.
Nothing (apart from accurate history) in this roadmap should be taken as irrevocable. Although we try to avoid unduly revisiting decisions, we welcome all developer comments and corrections. Let controversy bloom if it needs to. Just give us your evidence and reasons, and we at mozilla.org will correct our course and this map to match the actual terrain.
Here, are the browser road rules. Some of these points are concrete design decisions more than highfalutin' principles. But we think they reflect sound ideas (for example, autoconf captures feature dependencies better than our old Unix build system's platform macros and consequent #if defined(linux) || ... tests in the code).
• External development counts more than convenience or ease-of-habit for internal-to-Netscape developers. The Netscape X-heads, for example, have moved all of their mail usage except for I'm-out-sick-today and any truly proprietary messages to the Mozilla.unix newsgroup. Likewise with NGLayout hackers and the Mozilla.layout group. So it shall be for all development.
• Fresh mail and news clients will be designed and implemented jointly by Netscape and external developers, using open source methods, and this time with an open source database (which is likely to be Berkeley DB). The new mail/news code will use NGLayout for HTML rendering. It shall use as much XPFE-like cross-platform widgetry as it can; it shall use thin-mail techniques akin to Ender and Shack.
• As much as possible, UI structure should be implemented using HTML or XML and the NGLayout engine. Style should be expressed using CSS where doing so makes sense, and doesn't require non-standard extensions to CSS. Structure that can be queried, modified, and superposed from remote sources should probably be RDF, expressed in its XML syntax. Actions should be implemented (or at least, be implementable) via well-defined events and their JavaScript handlers
• Modules will use XP-IDL and XPCOM to specify and query their programmatic interfaces. That way, all modules are scriptable without requiring all interface creators to write repetitive-yet-tricky script-engine glue by hand. Also, parts of the system may be distributed across thread, process, and machine boundaries using automatically generated stubs. This distribution potential is a distant second goal, except where single-threaded code restrictions require us to implement an apartment threading model.
• Any scripting hooks above and beyond the scriptable-C++ entry points that we get by using XP-IDL must be designed and specified using IDL extensions. The crucial principle here is to make all useful parts of the browser easy to script. What's more, events must be easy to "hook" or handle in a flexible way, say using JavaScript. More on this point will be written in the XPCOM-Connect document.
• autoconf will be the one true Unix-hosted build system for the modules you checkout and build en masse to make a browser that runs on Unix. Module owners will have to maintain only their module's Makefile.in and configure.in scripts for Unix, not both of those and gmake Makefiles . (This principle does not apply to NSPR, which is a separately-built prerequisite of the browser; it may be that the Berkeley DB follows NSPR into separately-built prerequisite status, eventually.)
• X-heads believe the time is right to move from Motif to GTK+, the leading fully-open-source X-based UI toolkit. The general principle here, mentioned above in the mail/news paragraph in connection with Berkeley DB, and of course behind autoconf adoption, is that Mozilla must use the best open source solution to solve a well-understood problem.
Each of the following tasks constitutes a major milestone. This list isn't even partially ordered, but it should be, to express dependencies. It should be topologically sorted and scheduled, too (later). It shall be refined to include sub-tasks and missing items of work. For now, it's a roughly-ordered brain dump of what I think we'll all be doing in the next few months:
• NGLayout completion. See the NGLayout Project Page for detailed to-do lists and schedules. In light of the "open source solution" principle, the widget library used by NGLayout needs to be ported from Motif to GTK+.
• The old composer/editor was tightly coupled to old layout. NGLayout has a rich DOM API that perhaps (with more event work) could form the basis for the new editor. In any case, Mozilla must have an HTML composer/editor, and it should be embeddable via an OBJECT or TEXTAREA TYPE="text/html" tag.
• XPFE design and implementation. There is a very preliminary set of design documents , but they are subject to change and evolution based on the design principles above, and interested developers' input.
• Back-end modules such as RDF and JavaScript are more-or-less ready to go, but their interactions, especially their execution model interactions, need analysis. Also, memory consumption and things like garbage collector scheduling require a "whole system" analysis.
• Mail/news XPFE and modular back-ends need to be designed and implemented, or in a few cases, evolved from existing Mozilla code such as mozilla/lib/libmime .
• The XP-IDL compiler and IDL specs for all interfaces must be written, tested, and deployed as part of the build system.
• The JavaScript XPCOM-Connect runtime, by which JS can call C++ methods using runtime type information and convert results to JS types, must be built. The good news is that some of it will resemble LiveConnect. The bad (or good, for hackers who enjoy it) news is that we need some assembly code to implement each platform's Invoke method, where platform is a pair: (cpu instruction set architecture, compiler-and-CPU-determined calling conventions).
• Conversion of all Unix builds to autoconf. Currently, NGLayout is built by mozilla/nglayout.mk . If we follow the existing browser build model, it should be built by the Makefile generated from mozilla/Makefile.in and mozilla/configure.in .
Risk Factors
BUSINESS CHALLENGES
Increased competition
Reduced time to market
More customization of products and services
Need for risk reduction
Requirement to integrate disparate information sources for e-business
Shortage of appropriate skill sets and labor
TECHNICAL CHALLENGES
Abstraction from specific technical implementations
Need for high-performance applications
Building for scalability
Building for change
Security
Creating a component architecture
Key Business Issues180
This hyper-competitive environment is driving the need to alter business processes dynamically as new opportunities or threats appear. For example, based on a competitive threat, a large catalog retailer may need to create a new e-business application that combines individual clothing items, such as shirts or pants, from one catalog into an online catalog that shows complete outfits.
To make this work, you need to do more than just put together the right color combinations. It means that the Website and call-center applications need to be able to handle products composed of other products (similar to a bill of materials). This requires incredible flexibility from both the application and IT infrastructure. It also hints at the problems of scalability and adaptability facing many e-business applications. As the number of users grows, companies need the back-end flexibility to shift processing from one resource to another. Whether it means moving from a Sybase database to a Microsoft SQLServer database, or from a Microsoft COM-based application to a CORBA application, adaptability is a key requirement for tomorrow's IT systems.
With the increased pace of business change, IT organizations are under tremendous pressure to integrate formerly disparate systems and applications to meet business needs. Hurwitz Group research shows that the major business trends driving these integration requirements are
• Customer-focused process re-engineering.
• Globalization of business operations.
• Implementation of enterprise software packages such as Baan, Oracle, PeopleSoft, SAP, and others.
• Integration of electronic business with the rest of the enterprise.
But the complexity of implementing integration solutions can be daunting because these business drivers mandate the flow of information across legacy systems, packaged applications, custom applications, diverse technical platforms, and multiple databases with synonyms, homonyms, and different data representations. The combination of great need, an acute lack of skilled labor, and short implementation times makes all enterprise application integration solutions that abstract complexity and increase adaptability highly attractive. Hurwitz Group believes that the highest integration value for most businesses will be found at the business-integration level, where businesses need to manage business processes across systems and business units.
Another important issue facing business managers is risk. Although no competitive advantage will be gained without taking risk, there is no reason to seek it out or purposely expose your business to additional risk. A key success factor for businesses will be the ability to reduce exposure to risk caused by proprietary, unchangeable IT and application infrastructures. Quite simply, Hurwitz Group believes that the company with the most adaptable IT infrastructure will be the one that wins.
Key Technical Issues
Business issues are not the only problem facing companies. As line-of-business applications become an integral part of most companies' e-business strategies, the technical foundations and issues become even more important than they were five years ago. How can companies reduce risk in a world in which technological standards continue to change faster than trends in fashion? Today's IT managers live in a heterogeneous world with multiple object models (COM, CORBA, EJB), languages, and platforms.
Whereas most people once thought client-server technology (and lately, Internet technology) would solve IT and application problems, these advances simply contributed to a dramatically more complicated set of choices and technical environments for IT managers. On which object model should a company standardize? Which application server is best? How can all the COBOL programmers in a company be retrained for Java? These are the typical technical questions facing today's IT professionals.
In terms of enterprise application integration, the technical requirements of implementing integrated solutions are complex, and a number of different technologies are required. These include the communication plumbing between systems that consist of messaging and ORBs, transaction management, the translation and transformation of messages and data among systems, and the ability to manage events across systems.
Other key technical issues include scalability, security, and the move toward component architectures. In the old days, scalability was defined by the mainframe MIPS purchased and carefully allocated to the most important batch-processing jobs. More recently, in the client-server environments, scalability was defined by the number of desktops an application was deployed to and possibly how many database connections were required. But in today's e-business world, scalability is defined by the number of concurrent users the applications have.
In addition to the proliferation of access points into an organization, security issues will also be driven by the new integration requirements. The more companies integrate their resources and applications, the more insecure they become. If you've put everything you own in one building, it's much easier to access and use, but it's much easier for someone to steal from as well. Hurwitz Group believes that security issues will become an even more important strategic and tactical challenge for businesses over the next two years.
Lastly, in a world of constant change, a component-based enterprise-application architecture may be the only way to stay ahead. With a component-based development (CBD) approach, applications work with components through well-defined interfaces that expose only the methods and properties needed for the component to perform its function. This helps provide IT organizations with insulation from underlying technology and abstraction from low-level coding and underlying application plumbing. Of course, to fulfill this promise, CBD environments must support industry standards such as DCOM and CORBA, and also provide the flexibility to adopt new standards such as Java and Enterprise JavaBeans (EJB) as they emerge and mature.181
COTS Analysis
Trillium Software
Trillium Software's "Change Management Suite" is the only software on the market capable of identifying change, assessing the impact of, processing, versioning and documenting "change" for the Oracle Applications and/or Developer 2000 programs. The Change Management Suite can assist with managing change within Oracle Applications and/or Developer 2000 programs. The Change Finder allows you to detect and report on changes made to forms, reports, libraries, database objects, and entire database schemas.
The Automated Change Finder automates the manual running of the Change Finder. Once configured, the software will monitor the Oracle applications environment (or internally developed applications) and automatically generate different reports whenever changes are made to your forms, reports, libraries, and database schemas.
The Object Finder enables a developer to perform impact analysis on changes being made to forms, reports, libraries, and database objects. A query screen allows you to see where objects and libraries are being used throughout your entire application.
The Automated Generation Software will automate the installation and generation of your application for all of your Oracle Environments (DEV, TEST, PROD, etc.) throughout the entire software development lifecycle.
Serena Software
SERENA Software FULL.CYCLE Enterprise meets the challenge by viewing the mainframe and desktop as a single managed environment, providing an end-to-end solution to software change management (SCM) across the enterprise. SERENA FULL.CYCLE Enterprise is composed of FULL.CYCLE Mainframe and FULL.CYCLE Desktop, connected by SERENA's advanced SERNET technology.
FULL.CYCLE Mainframe is an industry-leading suite of products for managing the software change environment on mainframes. Products may be used individually to provide specific functionality or teamed to provide end-to-end management of the full software application life cycle. FULL.CYCLE Desktop delivers the SERENA Software core technologies of software change management to the distributed environment, including management of "shrink-wrapped" and customized applications. Pre- and post-deployment features assure that your software infrastructure remains available to users.
SERNET Connect technology not only connects desktop to mainframe files, but also connects desktop applications to mainframe applications.
• Compare desktop files to mainframe files.
• Develop applications on the desktop and runs them on the mainframe.
• Manage the entire enterprise environment from either the desktop or mainframe.
At the foundation of SERENA FULL.CYCLE Enterprise products is the SERNET technology, providing complete desktop-to-mainframe connectivity, as well as access to the full range of services provided by other SERENA products:
• SERNET Mainframe offers such core services as file I/O, patented "fingerprinting" technology, license management, and more. Additionally, SERNET Mainframe contains the mainframe portion of the connectivity function provided by SERNET Connect.
• SERNET Desktop offers common services, such as housekeeping functions and file management, to other SERENA FULL.CYCLE Enterprise desktop products and contains the desktop portion of the connectivity function provided by SERNET Connect.
• The SERNET architecture provides an open application interface (API), available to in-house developers and third-party independent software developers, assuring integration ease and preserving your IT investment.
MKS Solutions
Need to work fast to create exciting, fresh content, and code for your Website? Teams creating HTML, documents, graphics, JAVA, application logic, and dynamic content can use our Web Team Solution to store, manage, and track their Website changes. Your team can:
• Allow content providers to easily publish information to your Website.
• Maintain quality and control of your Website.
• Ensure content is approved prior to publishing.
• Easily share information with external groups.
• Leverage your existing Website structure.
Software developers, build engineers, and release managers must work quickly to release updated applications to the market. Teams using Visual C++, Visual Basic, Oracle Dev/2000, and other tools can benefit from our Software Development Team Solution to manage and control application changes. Teams of two to 500 people can:
• Easily maintain multiple releases of an application.
• Provide fine-grained protection for source code.
• Maximize productivity with integrations into popular IDEs.
• Automate code standards and code checks.
• Improve project management with status reports.
• Leverage work across multiple platforms.
Large development teams may have team members in many different locations and must have effective communication to ensure that work is completed on time and on budget. These teams can benefit from our Enterprise Software Development Team Solution. With MKS Source Integrity Professional Edition, teams of 10 to 2,000 people can:
• Improve software quality by recording and tracking defect and enhancement requests.
• Speed issue resolution time.
• Remotely access SCM and defect tracking functionality through the Web interface.
• Maintain multiple releases of an application.
• Provide fine-grained protection for source code.
• Maximize productivity with integrations into popular IDEs.
Bibliography
ADT Magazine, http://www.adtmag.com/pub/.
Bob Jensen's Website, http://www.trinity.edu/rjensen/.
Continuus Software, www.continuus.com/presswhatis.html.
Durand, David G. "Text-Only Versioning Requirements," (November 6, 1996). Available online: http://lists.w3.org/Archives/Public/w3c-dist-auth/1996OctDec/0120.html.
Dvarts, http://www.dvarts.com/Encyclopedia/WhitePapers/AAFwhitepaper.htm.
EDUCOM White Paper. "The Generic Office Environment." Available online: http://educom.on.ca/gen_off/introduc.htm.
File Formats and Image Compression, http://www.deakin.edu.au/~agoodman/scc308/topic7.html.
Geekgirl.talk, http://www.geekgirls.com/wheres_html_going.htm.
Industry Canada. Strategis Technology Roadmaps. http://strategis.ic.gc.ca/sc_indps/trm/engdoc/homepage.html, 1998.
Internet World, http://www.internetworld.com/
Internet.com, http://www.iw.com/.
New Developments in Non-Linear Editing, http://www.v-site.net/smpte-ne/nldesign.html.
Kelly, D. "Developing a Software-Development Strategy for the Year 2000," Performance Computing. Available online: http://www.performance-computing.com/hotproducts/hp2kf4.shtml.
National Center for Supercomputing Applications, Software Development Division. "Habanero." Available online: http://havefun.ncsa.uiuc.edu/habanero/Whitepapers/ecscw-habanero.html.
PC Magazine, http://www.zdnet.com/pcmag/.
Reimer, U., Ed. Proceedings of the 2nd International Conference on Practical Aspects of Knowledge Management (PAKM98), Basel, Switzerland (October 29-30, 1998. Available online: http://sunsite.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-13/.
Scientific American, http://www.sciam.com/1999/0599issue/0599bosak.html
SGML and XML Tools: Editing and Composition, http://www.infotek.no/sgmltool/editetc.htm.
Tate, Austin. Notes Toward the Creation of a Program Roadmap. AIAI, University of Edinburgh, 1993. Available online: http://www.aiai.ed.ac.uk/~bat/ roadmap.html.
The SGML/XML Web Page, http://www.oasis-open.org/cover/.
van der Spek, R. and Andre Spijkervet. "Knowledge Management: Dealing Intelligently with Knowledge." CIBIT, 1997.
Vitali, F. "Versioning Hypermedia," ACM Computing Survey (1999). Available online: http://www.cs.unibo.it/~fabio/bio/papers/1999/ACMCS/Version.pdf.
Web Developers Virtual Library, http://stars.com/.
Web Review, http://webreview.com/.
WEB Techniques Magazine, http://www.webtechniques.com/features/.
Web3D Consortium, http://www.web3d.org/Specifications/VRML97/.
World Wide Web Consortium, http://www.w3.org/.
World Wide Web Consortium, www.w3.org/Conferences/WWW4/Papers/91/.
XMLInfo, http://www.xmlinfo.com/.
Zurcher R. J. and R. N. Kostoff. "Modeling Technology Roadmaps." Journal of Technology Transfer, Vol. 22, No. 3, Fall 1997.
